데이터 세트 만들기
이 문서에서는 BigQuery에서 데이터 세트를 만드는 방법을 설명합니다.
다음 방법으로 데이터 세트를 만들 수 있습니다.
- Google Cloud 콘솔을 사용합니다.
- SQL 쿼리 사용
- bq 명령줄 도구에서
bq mk명령어 사용 datasets.insertAPI 메서드 호출- 클라이언트 라이브러리 사용
- 기존 데이터 세트 복사
리전 간 복사를 비롯해 데이터 세트를 복사하는 단계를 알아보려면 데이터 세트 복사를 참조하세요.
이 문서에서는 BigQuery에 데이터를 저장하는 일반 데이터 세트를 사용하는 방법을 설명합니다. Spanner 외부 데이터 세트를 사용하는 방법을 알아보려면 Spanner 외부 데이터 세트 만들기를 참고하세요. AWS Glue 제휴 데이터 세트를 사용하는 방법을 알아보려면 AWS Glue 제휴 데이터 세트 만들기를 참고하세요.
공개 데이터 세트의 테이블을 쿼리하는 방법을 알아보려면 Google Cloud 콘솔로 공개 데이터 세트 쿼리를 참고하세요.
데이터 세트 제한사항
BigQuery 데이터 세트에는 다음과 같은 제한사항이 적용됩니다.
- 데이터 세트 위치는 생성 당시에만 설정할 수 있습니다. 데이터 세트를 만든 후에는 위치를 변경할 수 없습니다.
- 쿼리에서 참조하는 모든 테이블은 같은 위치의 데이터 세트에 저장해야 합니다.
외부 데이터 세트는 테이블 만료, 복제본, 시간 여행, 기본 정렬, 기본 반올림 모드 또는 대소문자를 구분하지 않는 테이블 이름을 사용 설정하거나 사용 중지하는 옵션을 지원하지 않습니다.
테이블을 복사할 때 소스 테이블과 대상 테이블을 포함하는 데이터 세트는 같은 위치에 있어야 합니다.
프로젝트마다 데이터 세트 이름이 달라야 합니다.
데이터 세트의 스토리지 청구 모델을 변경한 경우 스토리지 청구 모델을 다시 변경할 수 있으려면 14일을 기다려야 합니다.
데이터 세트와 동일한 리전에 있는 기존 레거시 정액제 슬롯 약정이 있으면 물리적 스토리지 청구에 데이터 세트를 등록할 수 없습니다.
시작하기 전에
사용자에게 이 문서의 각 작업을 수행하는 데 필요한 권한을 부여하는 Identity and Access Management(IAM) 역할을 부여합니다.
필수 권한
데이터 세트를 만들려면 bigquery.datasets.create IAM 권한이 필요합니다.
다음과 같은 사전 정의된 각 IAM 역할에는 데이터 세트를 만드는 데 필요한 권한이 포함되어 있습니다.
roles/bigquery.dataEditorroles/bigquery.dataOwnerroles/bigquery.userroles/bigquery.admin
BigQuery에서 IAM 역할에 대한 자세한 내용은 사전 정의된 역할 및 권한을 참조하세요.
데이터 세트 이름 지정
BigQuery에서 데이터 세트를 만들 때 데이터 세트 이름은 프로젝트마다 고유해야 합니다. 데이터 세트 이름은 다음을 포함할 수 있습니다.
- 최대 1,024자(영문 기준)
- 문자(대문자 또는 소문자), 숫자, 밑줄
데이터 세트 이름은 기본적으로 대소문자를 구분합니다. mydataset 및 MyDataset는 둘 중 하나의 대소문자 구분이 사용 중지되지 않는 한 동일한 프로젝트에 공존할 수 있습니다.
데이터 세트 이름에는 -, &, @, %와 같은 공백이나 특수문자를 사용할 수 없습니다.
숨겨진 데이터 세트
숨겨진 데이터 세트는 이름이 밑줄로 시작하는 데이터 세트입니다. 다른 데이터 세트에서와 동일한 방식으로 숨겨진 데이터 세트의 테이블과 뷰를 쿼리할 수 있습니다. 숨겨진 데이터 세트에는 다음과 같은 제한사항이 있습니다.
- Google Cloud 콘솔의 탐색기 패널에는 숨겨져 있습니다.
INFORMATION_SCHEMA뷰에는 표시되지 않습니다.- 연결된 데이터 세트와 함께 사용할 수 없습니다.
- Data Catalog에는 표시되지 않습니다.
데이터 세트 만들기
데이터 세트를 만들려면 다음 안내를 따르세요.
콘솔
Google Cloud 콘솔에서 BigQuery 페이지를 엽니다.
탐색기 패널에서 데이터 세트를 만들 프로젝트를 선택합니다.
작업 옵션을 펼치고 데이터 세트 만들기를 클릭합니다.
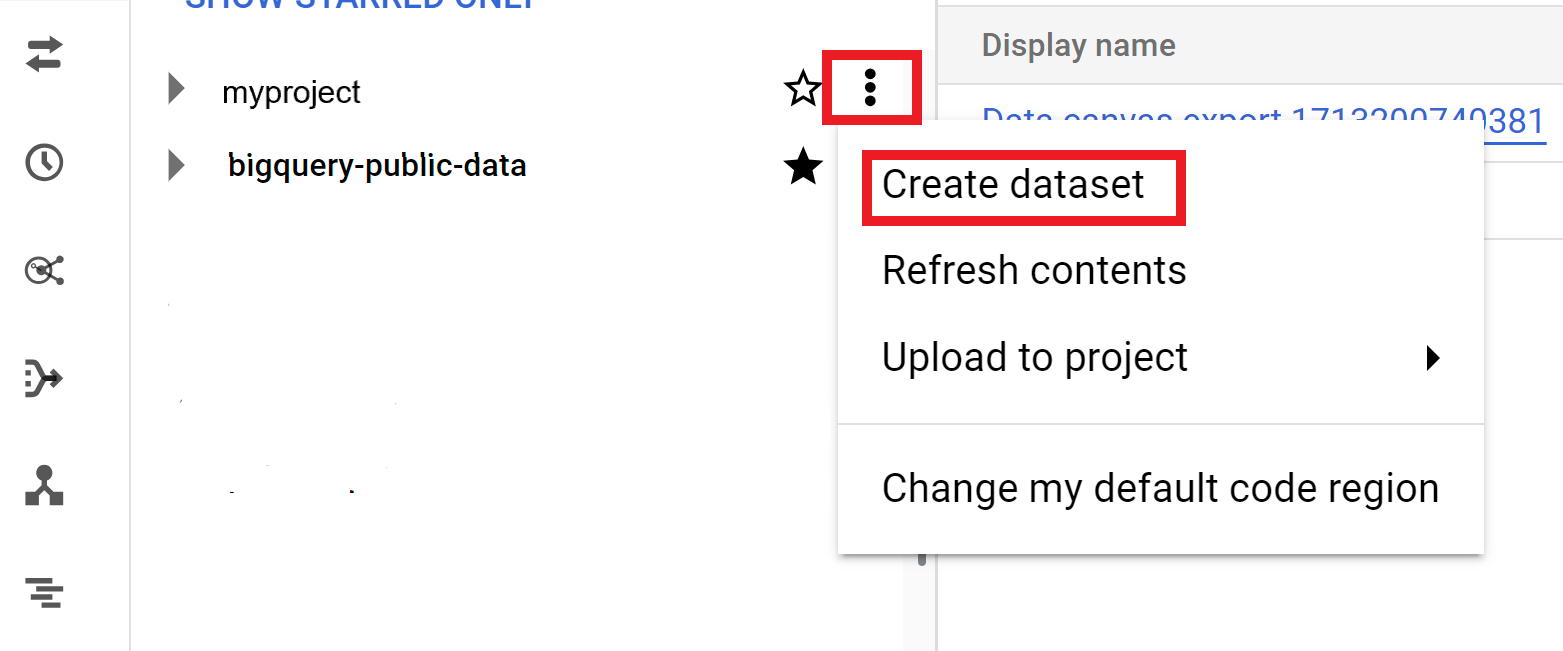
데이터 세트 만들기 페이지에서 다음을 실행합니다.
- 데이터 세트 ID에 고유한 데이터 세트 이름을 입력합니다.
위치 유형에서 데이터 세트의 지리적 위치를 선택합니다. 데이터 세트가 생성된 후에는 위치를 변경할 수 없습니다.
선택사항: 이 데이터 세트의 테이블을 만료시키려면 테이블 만료 시간 사용 설정을 선택한 다음 기본 최대 테이블 기간을(일 단위) 지정합니다.
선택사항: 고객 관리 암호화 키(CMEK)를 사용하려면 고급 옵션을 확장한 다음 고객 관리 암호화 키(CMEK)를 선택합니다.
선택사항: 대소문자를 구분하지 않는 테이블 이름을 사용하려면 고급 옵션을 확장한 다음 대소문자를 구분하지 않는 테이블 이름 사용 설정을 선택합니다.
선택사항: 기본 콜레이션을 사용하려면 고급 옵션을 확장한 다음 기본 콜레이션 사용 설정을 선택한 다음 사용할 기본 콜레이션을 선택합니다.
선택사항: 기본 반올림 모드를 사용하려면 고급 옵션을 확장한 다음 사용할 기본 반올림 모드를 선택합니다.
선택사항: 물리적 스토리지 청구 모델 을 사용 설정하려면 고급 옵션을 확장한 다음 선택하고물리적 스토리지 청구 모델 사용 설정을 선택합니다.
데이터 세트의 청구 모델을 변경하면 변경사항이 적용되는 데 24시간 정도 걸립니다.
데이터 세트의 스토리지 청구 모델을 변경한 후에는 스토리지 청구 모델을 다시 변경할 수 있으려면 14일을 기다려야 합니다.
선택사항: 데이터 세트의 시간 이동 기간을 설정하려면 고급 옵션을 확장한 다음 사용할 시간 이동 기간을 선택합니다.
데이터 세트 만들기를 클릭합니다.
SQL
CREATE SCHEMA 문을 사용합니다.
기본 프로젝트가 아닌 다른 프로젝트에서 데이터 세트를 만들려면 해당 프로젝트 ID를 PROJECT_ID.DATASET_ID 형식으로 데이터 세트 ID에 추가합니다.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
쿼리 편집기에서 다음 문을 입력합니다.
CREATE SCHEMA PROJECT_ID.DATASET_ID OPTIONS ( default_kms_key_name = 'KMS_KEY_NAME', default_partition_expiration_days = PARTITION_EXPIRATION, default_table_expiration_days = TABLE_EXPIRATION, description = 'DESCRIPTION', labels = [('KEY_1','VALUE_1'),('KEY_2','VALUE_2')], location = 'LOCATION', max_time_travel_hours = HOURS, storage_billing_model = BILLING_MODEL);
다음을 바꿉니다.
PROJECT_ID: 프로젝트 IDDATASET_ID: 사용자가 만들려는 데이터 세트 IDKMS_KEY_NAME: 이 데이터 세트에서 새로 생성된 테이블을 보호하는 데 사용되는 기본 Cloud Key Management Service 키의 이름. 생성 시 다른 키가 제공되면 그 이름을 사용합니다. 이 매개변수를 설정하여 데이터 세트에 Google 암호화 테이블을 만들 수 없습니다.PARTITION_EXPIRATION: 새로 생성된 파티션을 나눈 테이블의 파티션 기본 수명(일)입니다. 기본 파티션 만료 시간에는 최솟값이 없습니다. 만료 시간은 파티션의 날짜와 정수 값을 더한 값입니다. 데이터 세트의 파티션을 나눈 테이블에서 생성된 모든 파티션은 파티션 날짜로부터PARTITION_EXPIRATION일 후에 삭제됩니다. 파티션을 나눈 테이블을 만들거나 업데이트할 때time_partitioning_expiration옵션을 지정하면 테이블 수준의 파티션 만료 시간이 데이터 세트 수준의 기본 파티션 만료 시간보다 우선 적용됩니다.TABLE_EXPIRATION: 새로 생성된 테이블의 기본 수명(일)입니다. 최솟값은 0.042일(1시간)입니다. 만료 시간은 현재 시간과 정수 값을 더한 값으로 계산됩니다. 데이터 세트에서 생성된 모든 테이블은 생성 시간TABLE_EXPIRATION일 후에 삭제됩니다. 테이블을 만들 때 테이블 만료 시간을 설정하지 않으면 이 값이 적용됩니다.DESCRIPTION: 데이터 세트에 대한 설명KEY_1:VALUE_1: 이 데이터 세트의 첫 번째 라벨로 설정하려는 키-값 쌍KEY_2:VALUE_2: 두 번째 라벨로 설정하려는 키-값 쌍LOCATION: 데이터 세트의 위치. 데이터 세트가 생성된 후에는 위치를 변경할 수 없습니다.HOURS: 새 데이터 세트의 시간 이동 창의 시간 지정.HOURS값은 24(48, 72, 96, 120, 144, 168)의 배수로 표현된 48(2일)에서 168(7일) 사이의 정수여야 합니다. 이 옵션을 지정하지 않으면 168시간이 기본값입니다.BILLING_MODEL: 데이터 세트의 스토리지 청구 모델을 설정합니다.BILLING_MODEL값을PHYSICAL로 설정하여 스토리지 요금을 계산할 때 물리적 바이트를 사용하거나LOGICAL로 설정하여 논리 바이트를 사용합니다. 기본값은LOGICAL입니다.데이터 세트의 청구 모델을 변경하면 변경사항이 적용되는 데 24시간 정도 걸립니다.
데이터 세트의 스토리지 청구 모델을 변경한 후에는 스토리지 청구 모델을 다시 변경할 수 있으려면 14일을 기다려야 합니다.
실행을 클릭합니다.
쿼리를 실행하는 방법에 대한 자세한 내용은 대화형 쿼리 실행을 참조하세요.
bq
새 데이터 세트를 만들려면 --location 플래그와 함께 bq mk 명령어를 실행합니다. 사용할 수 있는 전체 파라미터 목록은 bq mk --dataset 명령어 참조를 확인하세요.
기본 프로젝트가 아닌 다른 프로젝트에서 데이터 세트를 만들려면 해당 프로젝트 ID를 PROJECT_ID:DATASET_ID 형식으로 데이터 세트 이름에 추가합니다.
bq --location=LOCATION mk \ --dataset \ --default_kms_key=KMS_KEY_NAME \ --default_partition_expiration=PARTITION_EXPIRATION \ --default_table_expiration=TABLE_EXPIRATION \ --description="DESCRIPTION" \ --label=KEY_1:VALUE_1 \ --label=KEY_2:VALUE_2 \ --add_tags=KEY_3:VALUE_3[,...] \ --max_time_travel_hours=HOURS \ --storage_billing_model=BILLING_MODEL \ PROJECT_ID:DATASET_ID
다음을 바꿉니다.
LOCATION: 데이터 세트의 위치. 데이터 세트가 생성된 후에는 위치를 변경할 수 없습니다..bigqueryrc파일을 사용하여 위치 기본값을 설정할 수 있습니다.KMS_KEY_NAME: 이 데이터 세트에서 새로 생성된 테이블을 보호하는 데 사용되는 기본 Cloud Key Management Service 키의 이름. 생성 시 다른 키가 제공되면 그 이름을 사용합니다. 이 매개변수를 설정하여 데이터 세트에 Google 암호화 테이블을 만들 수 없습니다.PARTITION_EXPIRATION: 새로 생성된 파티션을 나눈 테이블의 파티션 기본 수명(초). 기본 파티션 만료 시간에는 최솟값이 없습니다. 만료 시간은 파티션의 날짜와 정수 값을 더한 값입니다. 데이터 세트의 파티션을 나눈 테이블에서 생성된 모든 파티션은 파티션 날짜로부터PARTITION_EXPIRATION초 후에 삭제됩니다. 파티션을 나눈 테이블을 만들거나 업데이트할 때--time_partitioning_expiration플래그를 지정하면 테이블 수준의 파티션 만료 시간이 데이터 세트 수준의 기본 파티션 만료보다 우선 적용됩니다.TABLE_EXPIRATION: 새로 생성된 테이블의 기본 수명(초). 최솟값은 3,600초(1시간)입니다. 만료 시간은 현재 시간과 정수 값을 더한 값으로 계산됩니다. 데이터 세트에서 생성된 모든 테이블은 생성 시간TABLE_EXPIRATION초 후에 삭제됩니다. 테이블이 생성될 때 테이블 만료 시간을 설정하지 않은 경우에 이 값이 적용됩니다.DESCRIPTION: 데이터 세트에 대한 설명KEY_1:VALUE_1: 이 데이터 세트의 첫 번째 라벨로 설정하려는 키-값 쌍.KEY_2:VALUE_2는 두 번째 라벨로 설정하려는 키-값 쌍입니다.KEY_3:VALUE_3: 데이터 세트의 태그로 설정하려는 키-값 쌍입니다. 키-값 쌍 사이 쉼표를 사용하여 동일한 플래그 아래에 여러 태그를 추가합니다.HOURS: 새 데이터 세트의 시간 이동 창의 시간 지정.HOURS값은 24(48, 72, 96, 120, 144, 168)의 배수로 표현된 48(2일)에서 168(7일) 사이의 정수여야 합니다. 이 옵션을 지정하지 않으면 168시간이 기본값입니다.BILLING_MODEL: 데이터 세트의 스토리지 청구 모델을 설정합니다.BILLING_MODEL값을PHYSICAL로 설정하여 스토리지 요금을 계산할 때 물리적 바이트를 사용하거나LOGICAL로 설정하여 논리 바이트를 사용합니다. 기본값은LOGICAL입니다.데이터 세트의 청구 모델을 변경하면 변경사항이 적용되는 데 24시간 정도 걸립니다.
데이터 세트의 스토리지 청구 모델을 변경한 후에는 스토리지 청구 모델을 다시 변경할 수 있으려면 14일을 기다려야 합니다.
PROJECT_ID: 프로젝트 IDDATASET_ID: 사용자가 만들려는 데이터 세트 ID
예를 들어 다음 명령어를 실행하면 데이터 위치가 US, 기본 테이블 만료 시간이 3,600초(1시간), 설명이 This is my dataset로 설정되고 이름이 mydataset인 데이터 세트가 생성됩니다. --dataset 플래그를 사용하는 대신 이 명령어는 -d 단축키를 사용합니다. -d와 --dataset를 생략할 경우 이 명령어는 기본적으로 데이터 세트를 만듭니다.
bq --location=US mk -d \ --default_table_expiration 3600 \ --description "This is my dataset." \ mydataset
데이터 세트가 생성되었는지 확인하려면 bq ls 명령어를 입력합니다. 또한 bq mk -t dataset.table 형식을 사용하여 새 데이터 세트를 만들 때 테이블을 만들 수 있습니다.
테이블 만들기에 대한 자세한 내용은 테이블 만들기를 참조하세요.
Terraform
google_bigquery_dataset 리소스를 사용합니다.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
데이터 세트 만들기
다음 예시에서는 이름이 mydataset인 데이터 세트를 만듭니다.
google_bigquery_dataset 리소스를 사용하여 데이터 세트를 만들면 프로젝트 수준의 기본 역할의 구성원인 모든 계정에 데이터 세트에 대한 액세스 권한이 자동으로 부여됩니다.
데이터 세트를 만든 후 terraform show 명령어를 실행하면 데이터 세트의 access 블록이 다음과 유사하게 표시됩니다.
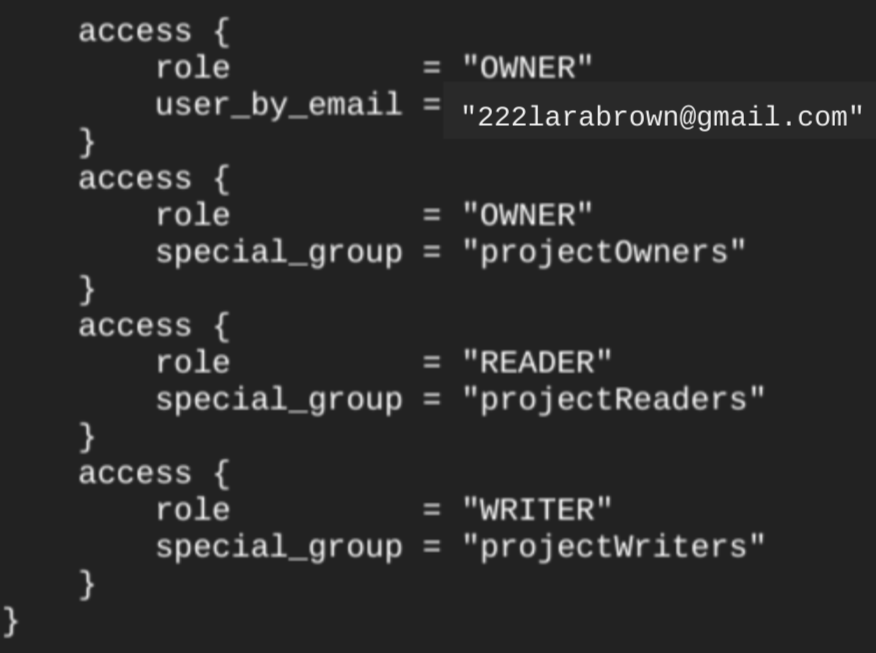
데이터 세트에 대한 액세스 권한을 부여하려면 google_bigquery_iam 리소스 중 하나를 사용하는 것이 좋습니다. 단, 데이터 세트 내 승인된 뷰와 같은 승인된 객체를 만들려는 경우는 예외입니다.
이 경우 google_bigquery_dataset_access 리소스를 사용합니다. 예시는 해당 문서를 참조하세요.
데이터 세트 만들기 및 액세스 권한 부여
다음 예시에서는 mydataset라는 테이블을 만든 후 google_bigquery_dataset_iam_policy 리소스를 사용해서 액세스 권한을 부여합니다.
고객 관리 암호화 키로 데이터 세트 만들기
다음 예시에서는 mydataset라는 데이터 세트를 만들고 google_kms_crypto_key 및 google_kms_key_ring 리소스를 사용하여 데이터 세트의 Cloud Key Management Service 키를 지정합니다. 이 예시를 실행하기 전에 Cloud Key Management Service API를 사용 설정해야 합니다.
Google Cloud 프로젝트에 Terraform 구성을 적용하려면 다음 섹션의 단계를 완료하세요.
Cloud Shell 준비
- Cloud Shell을 실행합니다.
-
Terraform 구성을 적용할 기본 Google Cloud 프로젝트를 설정합니다.
이 명령어는 프로젝트당 한 번만 실행하면 되며 어떤 디렉터리에서도 실행할 수 있습니다.
export GOOGLE_CLOUD_PROJECT=PROJECT_ID
Terraform 구성 파일에서 명시적 값을 설정하면 환경 변수가 재정의됩니다.
디렉터리 준비
각 Terraform 구성 파일에는 자체 디렉터리(루트 모듈이라고도 함)가 있어야 합니다.
-
Cloud Shell에서 디렉터리를 만들고 해당 디렉터리 내에 새 파일을 만드세요. 파일 이름에는
.tf확장자가 있어야 합니다(예:main.tf). 이 튜토리얼에서는 파일을main.tf라고 합니다.mkdir DIRECTORY && cd DIRECTORY && touch main.tf
-
튜토리얼을 따라 하는 경우 각 섹션이나 단계에서 샘플 코드를 복사할 수 있습니다.
샘플 코드를 새로 만든
main.tf에 복사합니다.필요한 경우 GitHub에서 코드를 복사합니다. 이는 Terraform 스니펫이 엔드 투 엔드 솔루션의 일부인 경우에 권장됩니다.
- 환경에 적용할 샘플 매개변수를 검토하고 수정합니다.
- 변경사항을 저장합니다.
-
Terraform을 초기화합니다. 이 작업은 디렉터리당 한 번만 수행하면 됩니다.
terraform init
원하는 경우 최신 Google 공급업체 버전을 사용하려면
-upgrade옵션을 포함합니다.terraform init -upgrade
변경사항 적용
-
구성을 검토하고 Terraform에서 만들거나 업데이트할 리소스가 예상과 일치하는지 확인합니다.
terraform plan
필요에 따라 구성을 수정합니다.
-
다음 명령어를 실행하고 프롬프트에
yes를 입력하여 Terraform 구성을 적용합니다.terraform apply
Terraform에 '적용 완료' 메시지가 표시될 때까지 기다립니다.
- Google Cloud 프로젝트를 열어 결과를 확인합니다. Google Cloud 콘솔에서 UI의 리소스로 이동하여 Terraform이 리소스를 만들었거나 업데이트했는지 확인합니다.
API
데이터 세트 리소스가 정의된 datasets.insert 메서드를 호출합니다.
C#
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 C# 설정 안내를 따르세요. 자세한 내용은 BigQuery C# API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
Go
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 Go 설정 안내를 따르세요. 자세한 내용은 BigQuery Go API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
자바
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 Java 설정 안내를 따르세요. 자세한 내용은 BigQuery Java API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
Node.js
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 Node.js 설정 안내를 따르세요. 자세한 내용은 BigQuery Node.js API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
PHP
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 PHP 설정 안내를 따르세요. 자세한 내용은 BigQuery PHP API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
Python
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 Python 설정 안내를 따르세요. 자세한 내용은 BigQuery Python API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
Ruby
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 Ruby 설정 안내를 따르세요. 자세한 내용은 BigQuery Ruby API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
데이터 세트 보안
BigQuery에서 데이터 세트에 대한 액세스를 제어하려면 데이터 세트에 대한 액세스 제어를 참조하세요. 데이터 암호화에 대한 자세한 내용은 저장 데이터 암호화를 참조하세요.
다음 단계
- 프로젝트의 데이터 세트 나열에 대한 자세한 내용은 데이터 세트 나열을 참조하세요.
- 데이터 세트 메타데이터에 대한 자세한 내용은 데이터 세트 정보 가져오기를 참조하세요.
- 데이터 세트 속성 변경에 대한 자세한 내용은 데이터 세트 업데이트를 참조하세요.
- 라벨 만들기 및 관리에 대한 자세한 내용은 라벨 만들기 및 관리를 참조하세요.
직접 사용해 보기
Google Cloud를 처음 사용하는 경우 계정을 만들어 실제 시나리오에서 BigQuery의 성능을 평가할 수 있습니다. 신규 고객에게는 워크로드를 실행, 테스트, 배포하는 데 사용할 수 있는 $300의 무료 크레딧이 제공됩니다.
BigQuery 무료로 사용해 보기