Titanium: A robust foundation for workload-optimized cloud computing

Amin Vahdat
VP/GM, ML, Systems, and Cloud AI
Nirav Mehta
Sr Director, Product Management, Google Cloud
Powering the fastest block storage performance among leading hyperscalers
Google Cloud is built on world-class technical infrastructure that supports services that are loved and relied on by billions of people across the globe: Google Search, YouTube, Gmail, Google Maps and more. A core tenet at Google Cloud is to leverage Google’s experience building and operating highly available and highly reliable planetary-scale compute, storage and networking systems and data centers.
Google takes a workload-optimized approach to building its infrastructure, employing a combination of dedicated hardware and software components to meet its workloads’ ever-growing demands. Underpinning this infrastructure is Titanium, a system of purpose-built, custom silicon and multiple tiers of scale-out offloads that together power improvements in the performance, reliability, and security of our customers’ workloads (for example, 25% faster block storage IOPS/instance compared to the other two leading hyperscalers). Unveiled today at Google Cloud Next, you’ll find Titanium technology in many of Google Cloud’s recent infrastructure offerings.
10x demands of tomorrow
Meeting the growing performance, reliability, and security demands of both legacy and emerging workloads is a constant challenge for cloud infrastructure providers. And now, these demands are multiplying with the heightened adoption of generative AI across almost every industry. Meanwhile, the benefits of Moore’s law have been declining in recent years. We can’t rely on silicon advances alone to meet tomorrow's needs.
As just one example, this chart shows the exponential computing demands of large language models.
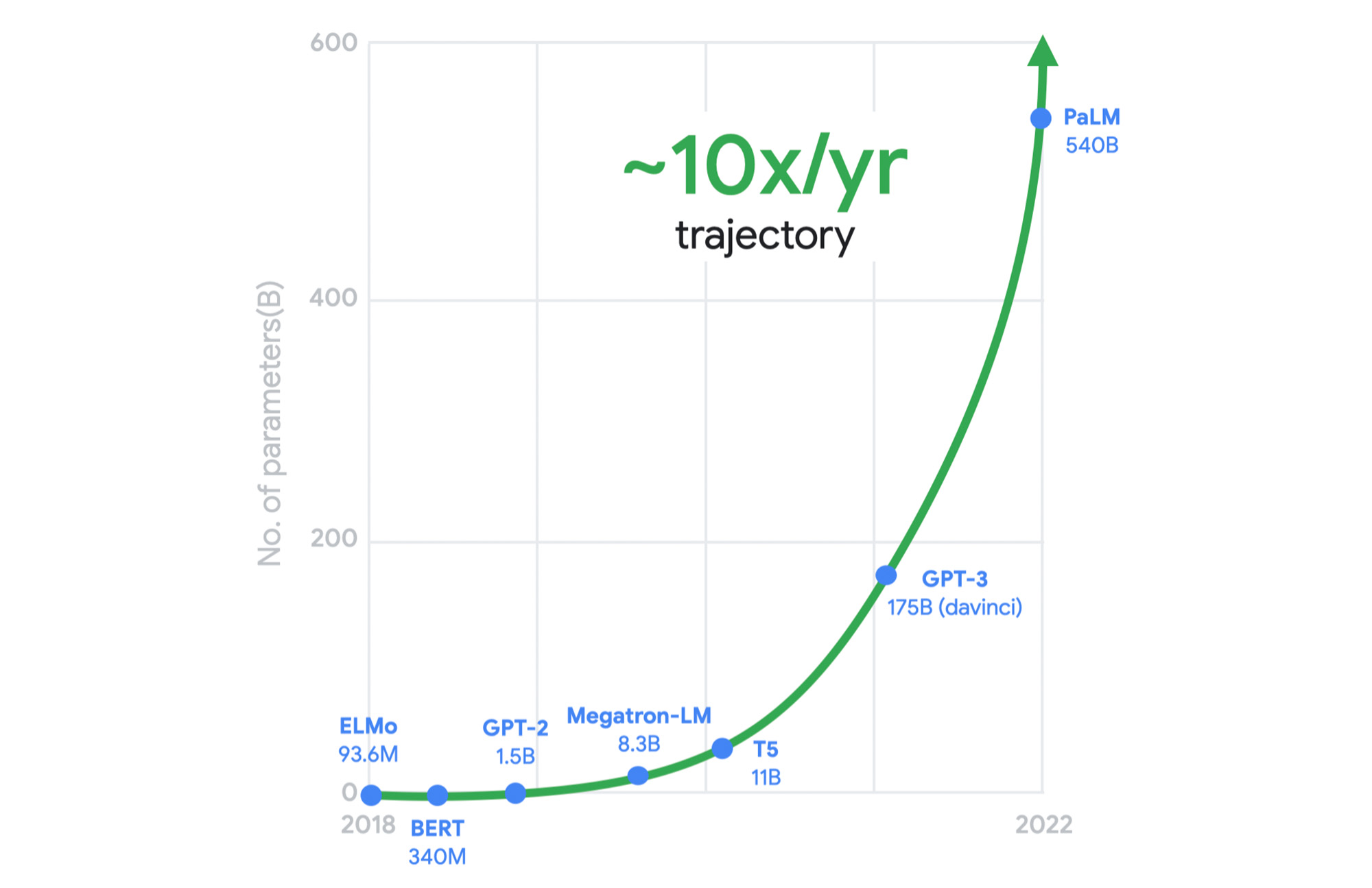
It was clear to us a long time ago that we needed to rethink our infrastructure designs to meet these demands. This is why, for several years, we’ve adopted workload-optimization and intentional design as central principles for our infrastructure platform. We engineer golden paths from silicon to the customer workload, using a combination of purpose-built infrastructure, prescriptive architectures, and an open ecosystem to deliver workload-optimized infrastructure.
Offloads play a pivotal role
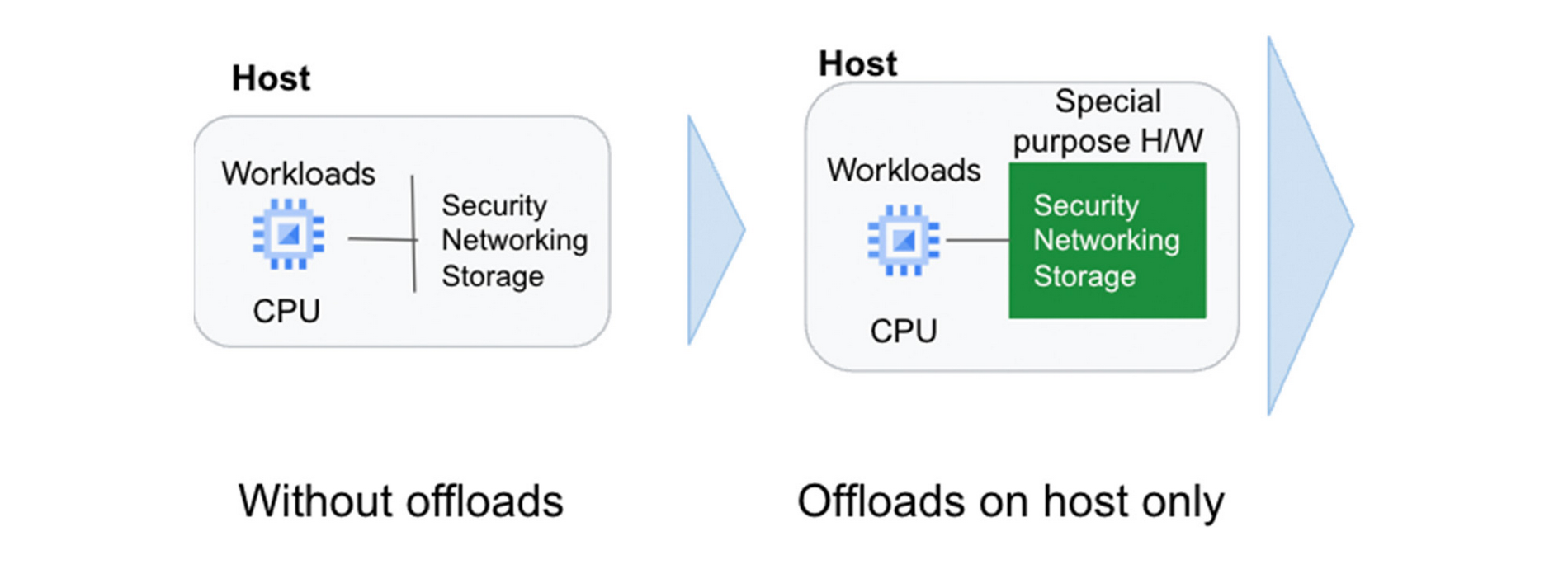
Central to this strategy are offload technologies. Traditionally, the CPU wears many hats: It runs the hypervisor, the virtualization stack to enable your workloads, and manages storage and networking I/O; it’s responsible for security isolation for virtual interfaces and physical hardware, etc. In this model, customer workloads running on the CPU contend for resources with these platform tasks.
Offloads on dedicated hardware perform behind-the-scenes security, networking, and storage functions that were previously performed by the host CPU, allowing the CPU to focus on maximizing performance for customer workloads.
A recent example of an on-host offload or accelerator is the Infrastructure Processing Unit (IPU), a system-on-chip that we co-designed with Intel to enable better security isolation and performance on our 3rd gen compute instances. The IPU enables:
- Predictable and efficient compute
- Programmable packet processing for low latency, 200 Gbps networking with 3x the packets per second compared to our previous-generation compute instances
- In-transit encryption with the PSP protocol
Another important example of Google’s on-host hardware is Titan, a secure, low-power microcontroller that helps ensure that every machine in Google Cloud boots from a trusted state.
But we did not stop there. To meet tomorrow’s demands, we knew we needed to go past the performance that could be achieved using the host’s dedicated offload hardware.
A tiered system of offloads
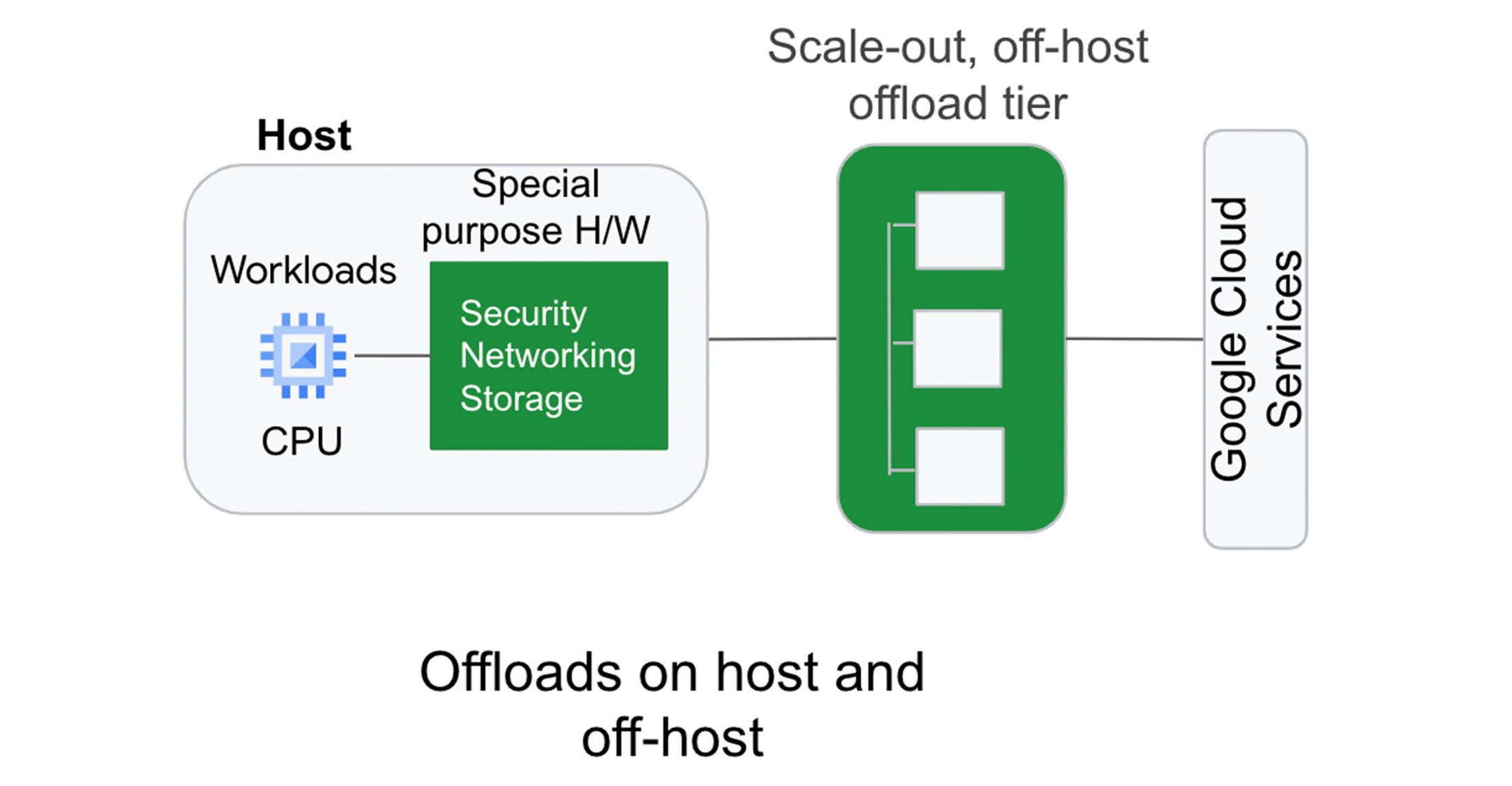
A key component of Titanium is its modern offload architecture, which combines capabilities whose scale and performance are well-established within Google, as well as new capabilities tailored for cloud use cases.
Just as modern workloads scale out horizontally in the cloud, with Titanium, we’ve extended the architecture to augment on-host offloads with an additional tier of scale-out offloads that run outside the host. This system of offloads is deployed fleet-wide and dynamically adjusts to changing workload needs to continually deliver the best performance.
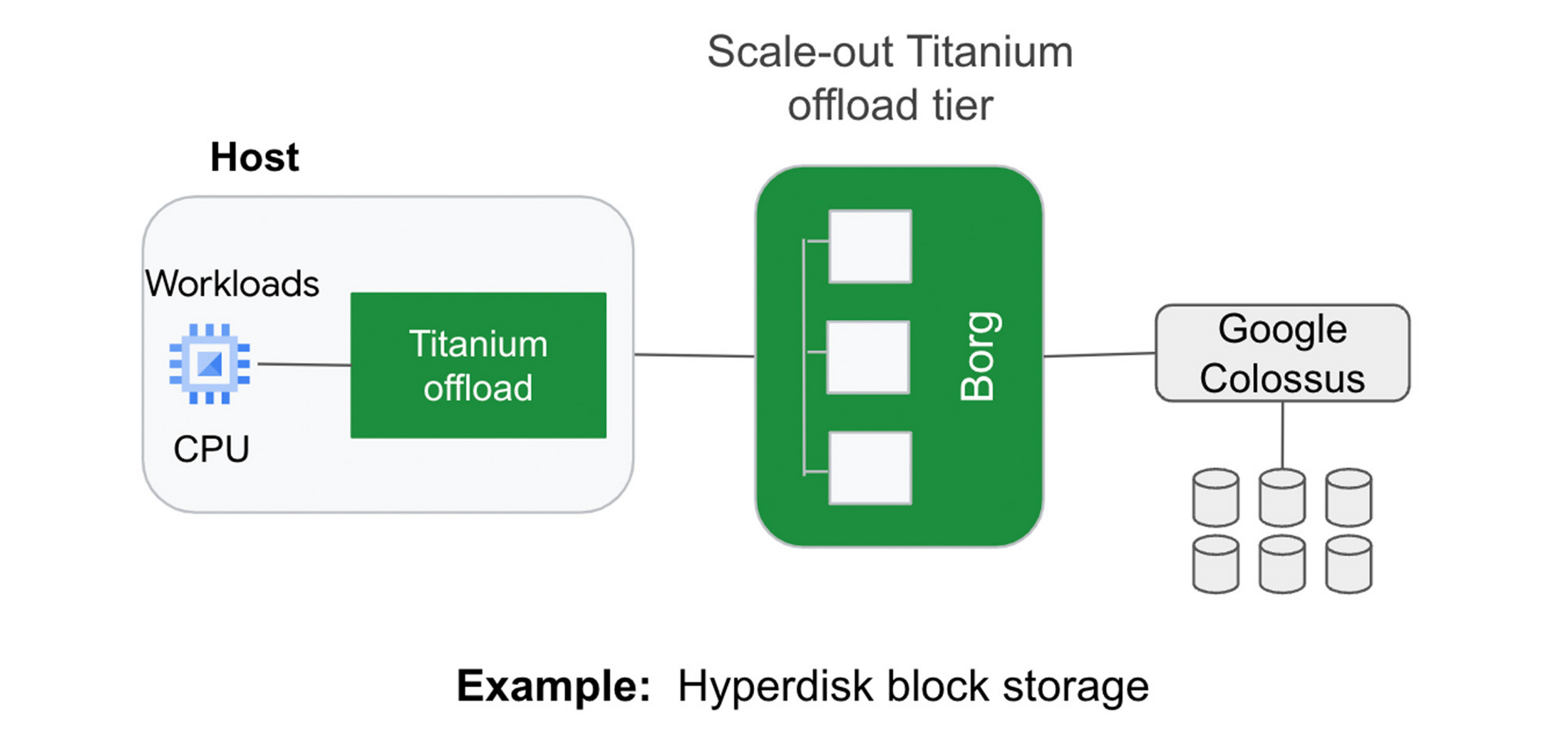
Example 1: Block storage
Titanium scale-out offload enables Hyperdisk block storage to deliver stellar I/O performance. Hyperdisk's Titanium offload on the host IPU works in tandem with the Titanium scale-out offload tier that distributes I/O across Google’s massive cluster-level filesystem, Colossus.
With traditional offload architectures, higher block storage IOPS requires purchasing larger compute instances. For example, you may need to deploy a data-intensive workload on a compute instance with many more vCPUs than the workload needs just to get sufficient storage performance. This tight coupling results in wasted resources and higher costs for customers. Further, even with large instances, storage performance in the cloud may be inadequate relative to what customers are used to with on-prem storage systems.
With our new block storage, Hyperdisk powered by Titanium, we have decoupled compute-instance size from storage performance. Hyperdisk uses a tier of offloads in our cloud fabric to offload storage I/O from the customer hosts to achieve higher storage performance even with a general-purpose VM.
In fact, today we are announcing that Titanium-powered C3 VMs with Hyperdisk Extreme now support 500K IOPS per compute instance in preview to meet the needs of the most demanding workloads. This is 25% faster IOPS/instance compared to the other two leading hyperscalers, courtesy of the Titanium system.
Example 2: Network routing
Virtual network routing is another example of using a second tier of scale-out offloads (“hoverboards”). With Titanium, Google’s Andromeda virtual networking stack on the IPU offload device sends all packets for which it does not have a route to Hoverboard gateways, which have forwarding information for all virtual networks. Hoverboards are standalone software switches that act as default routers for some flows.
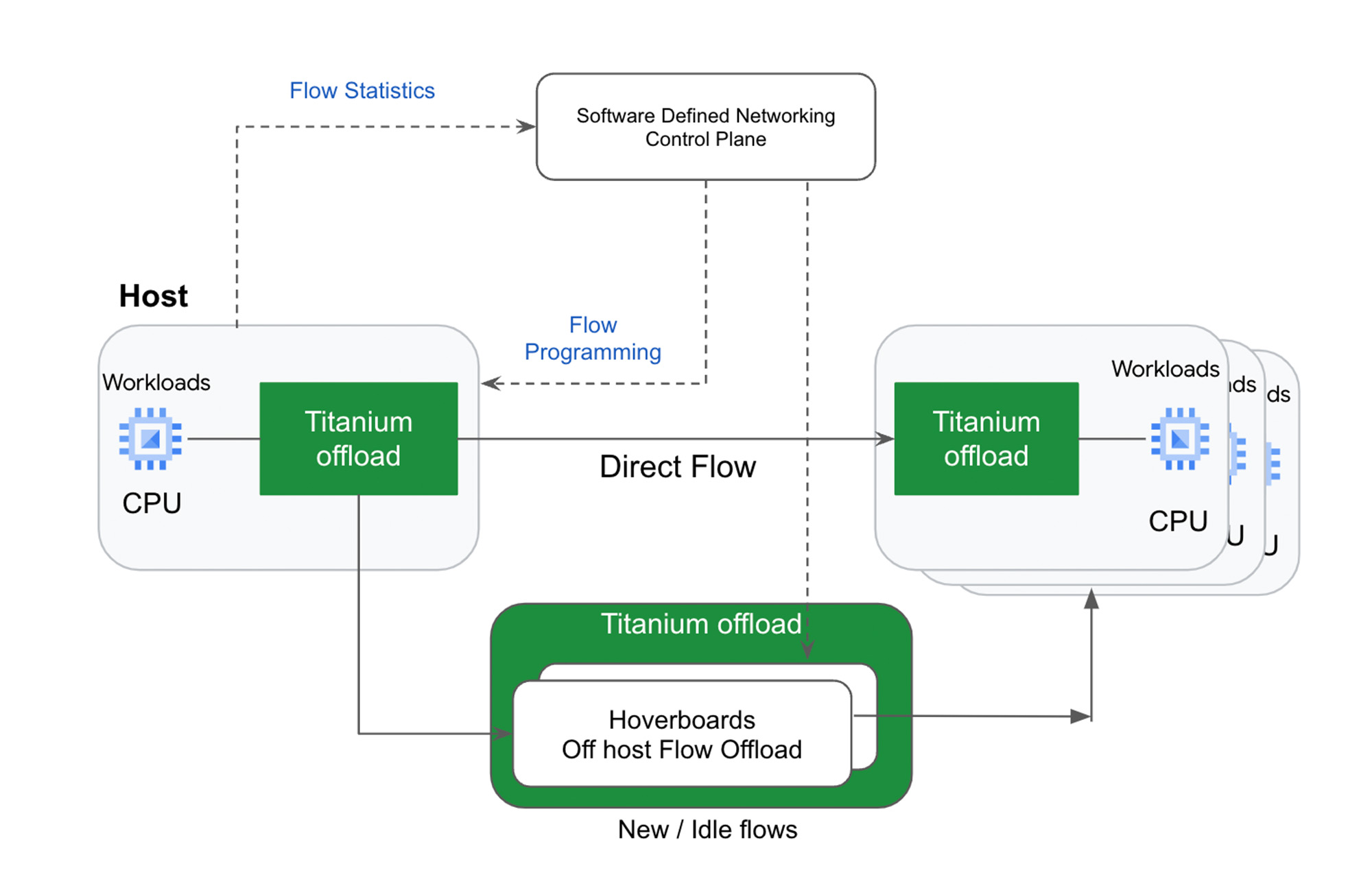
Unlike the traditional gateway model, the control plane dynamically detects flows that exceed a specified usage threshold and programs them to be direct host-to-host flows, bypassing the hoverboards allowing hoverboards to focus on the long tail of less frequent flows. Typically, only a small subset of possible VM pairs in a network communicate with one another, so the VMs only have to store and process a small fraction of the usual network configuration on an individual VM host, improving per-server memory utilization and control-plane CPU scalability.
Titanium already powers your workloads
The Titanium journey began years ago with the component technologies described above. Many of our products already benefit from this architecture, and the newest elements of this architecture are now available with our 3rd gen Compute Engine instances such as C3 and the new Hyperdisk block storage.
Going forward, look for the Titanium architecture to underpin all future generations of our infrastructure offerings, in the process enabling new classes of infrastructure capabilities that move well beyond the confines of a single server.



