Designing ETL architecture for a cloud-native data warehouse on Google Cloud Platform
Sergei Sokolenko
Cloud Dataflow Product Manager
Learn how to build an ETL solution for Google BigQuery using Google Cloud Dataflow, Google Cloud Pub/Sub and Google App Engine Cron as building blocks.
Many customers migrating their on-premises data warehouse to Google Cloud Platform (GCP) need ETL solutions that automate the tasks of extracting data from operational databases, making initial transformations to data, loading data records into Google BigQuery staging tables and initiating aggregation calculations. Quite often, these solutions reflect these main requirements:
- Support for a large variety of operational data sources and support for relational as well as NoSQL databases, files and streaming events
- Ability to use DML statements in BigQuery to do secondary processing of data in staging tables
- Ability to maximize resource utilization by automatically scaling up or down depending on the workload, and scaling, if need be, to millions of records per second
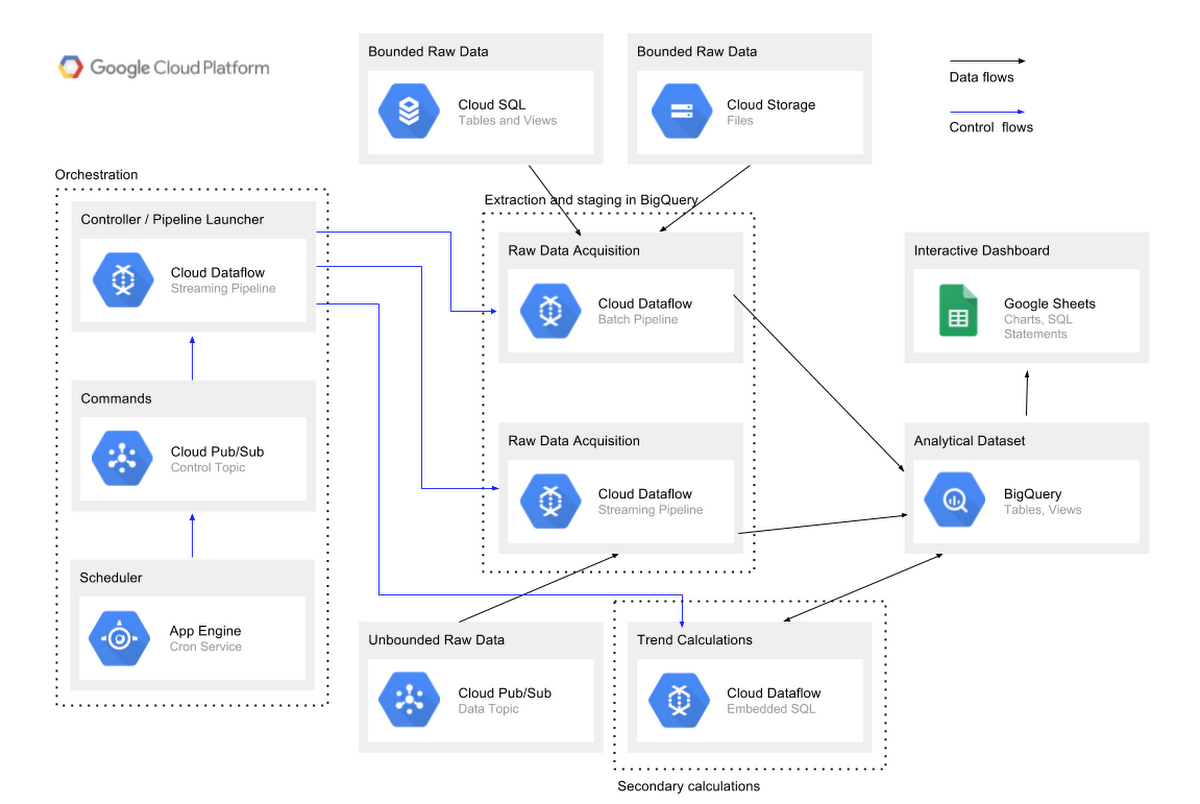
Architecture components
The components of this architecture include (following the architecture diagram left to right):- A task orchestrator built using Google App Engine Cron Service, Google Cloud Pub/Sub control topic and Google Cloud Dataflow in streaming mode
- Cloud Dataflow for importing bounded (batch) raw data from sources such as relational Google Cloud SQL databases (MySQL or PostgreSQL, via the JDBC connector) and files in Google Cloud Storage
- Cloud Dataflow for importing unbounded (streaming) raw data from a Google Cloud Pub/Sub data ingestion topic
- BigQuery for storing staging and final datasets
- Additional ETL transformations enabled via Cloud Dataflow and embedded SQL statements
- An interactive dashboard implemented via Google Sheets and connected to BigQuery
Next, let’s explore how it works.
Launching pipelines
The basis of this ETL solution is the App Engine Task Queue Cron Service, configured to periodically send commands to a pipeline launcher.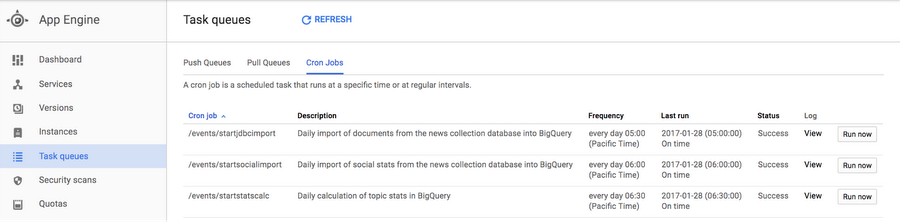
Commands can be scripted e.g., in Python and are sent via a Cloud Pub/Sub control topic. They include the name of the command and parameters such as a time window for pulling data from the data source. An example command is shown below:
Here's the Python script that gets invoked by the Cron Service to send this command:
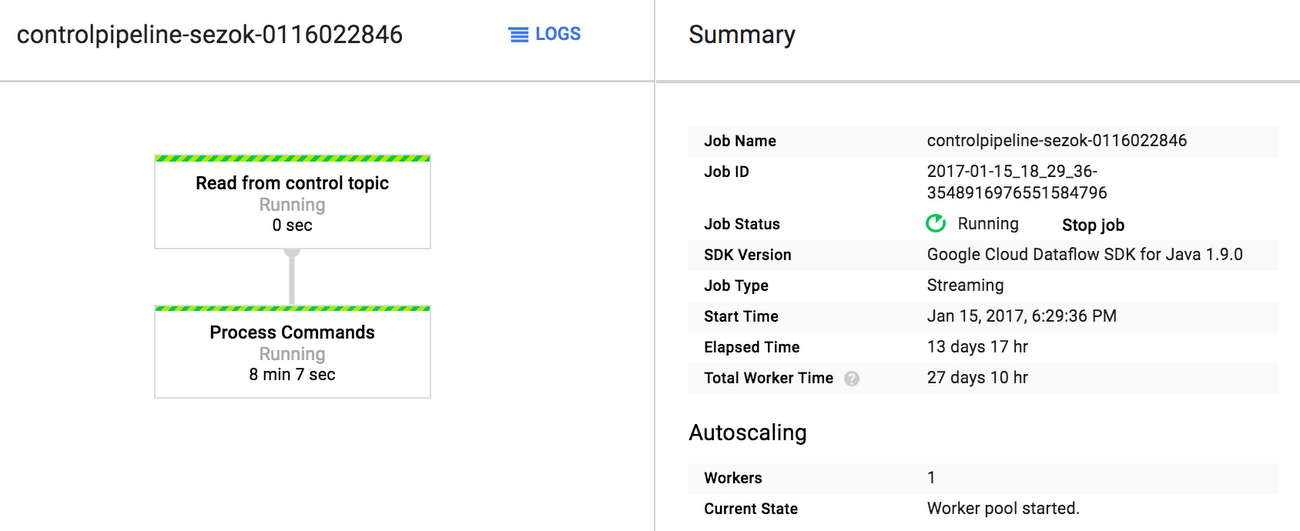
At the receiving end of the control Cloud Pub/Sub topic is a streaming Cloud Dataflow pipeline whose task is to triage the commands and create new pipelines for ingesting data or running secondary calculations on BigQuery staging tables.
Using an orchestrating Cloud Dataflow pipeline is not the only option for launching other pipelines. One alternative is to use Cloud Dataflow templates, which let you stage your pipelines in Cloud Storage and execute them using a REST API or the gcloud command-line tool. Another alternative involves using servlets or Google Cloud Functions for initiating Cloud Dataflow jobs. Yet another option is to use Apache Airflow.
We chose the streaming Cloud Dataflow approach for this solution because it allows us to more easily pass parameters to the pipelines we wanted to launch, and did not require operating an intermediate host for executing shell commands or host servlets.
Loading data
Batch and streaming Cloud Dataflow pipelines, which are the core of the ETL solution, are responsible for ingesting data from operational sources into BigQuery. Batch pipelines process data from relational and NoSQL databases and Cloud Storage files, while streaming pipelines process streams of events ingested into the solution via a separate Cloud Pub/Sub topic.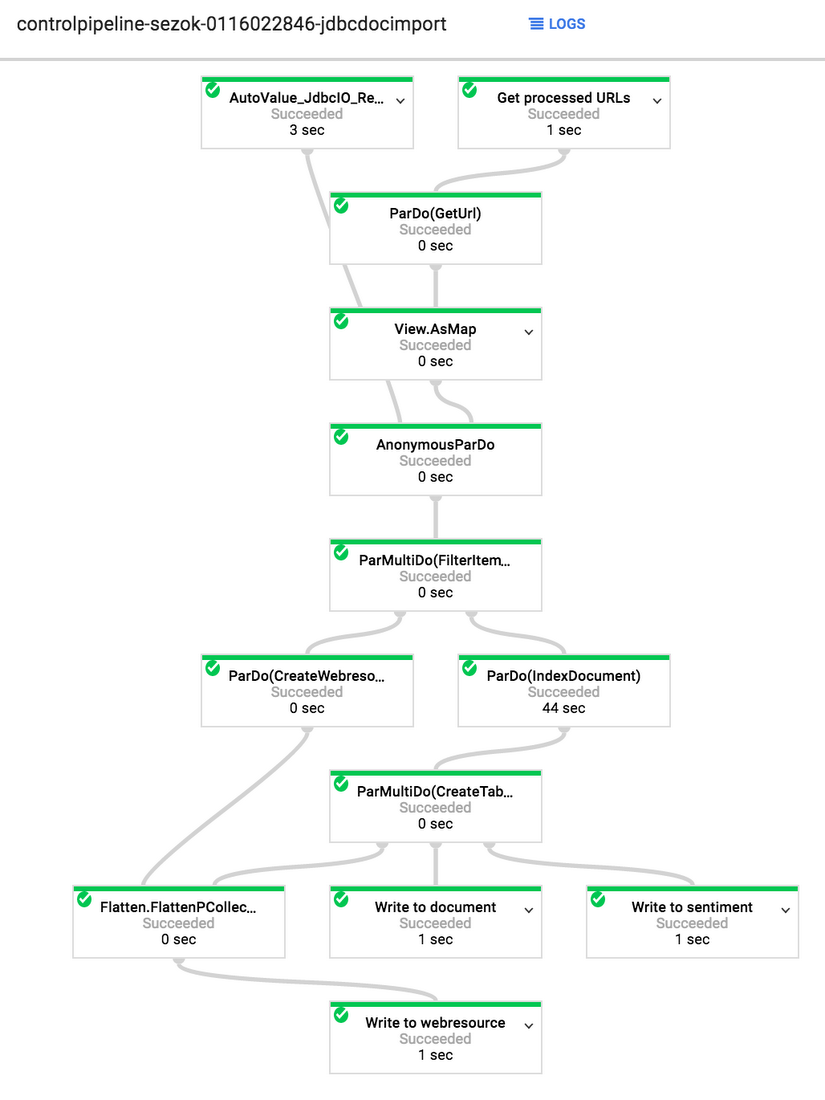
One common technique for loading data into a data warehouse is to load hourly or daily changes from operational datastores. The timewindowsec parameter in our example command specifies a window of 130,000 seconds, or approximately 1.5 days. While the loading process will run daily to account for variations in execution time of the batch load, we set the time window to a duration longer than a day.
The destination table in BigQuery might already contain parts of the data captured on the source table, so a deduplication step is often required. Because BigQuery is optimized for adding records to tables and updates or deletes are discouraged, albeit still possible, it's advisable to do the deduplication before loading into BigQuery. This step ensures that the loading process only adds new, previously unwritten records to destination tables. In this ETL solution, a cache of record ids that were already inserted into the BigQuery tables is maintained inside the Dataflow pipeline. This cache is implemented as a Side Input, and is populated by record ids created in the time window of a duration specified by the historywindowsec parameter.
After daily delta changes have been loaded to BigQuery, users often need to run secondary calculations on loaded data. For example, data in staging tables needs to be further transformed into records in final tables. In other cases, aggregations need to be run on data in fact tables and persisted in aggregation tables. In many cases, BigQuery is replacing an on-premises data warehousing solution with legacy SQL scripts or stored procedures used to perform these calculations, and customers want to preserve these scripts at least in part. So, in this ETL architecture we propose a way to replace the stored procedures and scripts traditionally used to do secondary transformations with INSERT SELECT statements using a multi-level WITH clause that calculates intermediate results in stages, as a stored procedure would do. Here’s an example (also available on github):
The above INSERT statement calculates aggregate statistics for a daily snapshot and stores them in the table statstoryimpact.
Orchestrating aggregations
Cloud Dataflow orchestrates the execution of these SQL statements in case there are multiple tables to be populated or several daily snapshots to be calculated in a batch. App Engine's Cron Service sends to ControlPipeline, our pipeline launcher, a regularly-scheduled command to initiate the processing of secondary calculations:The ControlPipeline accepts either a date range (useful for one-time backfill process) "fromdate" to "todate", or a relative date marker T-[N], where "T-1" stands for the previous day, T-2 for 2 days before etc. For example, our cron entry for daily stats calculations always sends “T-1” as the parameter.
During the statistics/aggregations calculation step, when SQL statements need to be executed sequentially (e.g., when they use the results of previous calculations), they're accumulated in an array of Strings and then executed in a loop using the BigQuery client. When calculations can be run in parallel, a new branch is added to the pipeline graph using the addSQLCommandTransform call.


