Diese Seite bietet einen Überblick über die Hochverfügbarkeitskonfiguration für Cloud SQL-Instanzen. Informationen zum Konfigurieren einer neuen Instanz mit Hochverfügbarkeit oder zum Aktivieren der Hochverfügbarkeit für eine vorhandene Instanz finden Sie unter Hochverfügbarkeit für eine Instanz aktivieren und deaktivieren.
Hochverfügbarkeit konfigurieren
Der Zweck einer Hochverfügbarkeitskonfiguration besteht darin, Ausfallzeiten zu reduzieren, wenn eine Zone oder Instanz nicht mehr verfügbar ist. Dies kann bei einem Zonenausfall oder Hardwareproblem auftreten. Mit Hochverfügbarkeit sind Ihre Daten weiterhin für Clientanwendungen verfügbar.
Die Konfiguration der Hochverfügbarkeit bietet Datenredundanz. Eine Cloud SQL-Instanz, die für Hochverfügbarkeit konfiguriert ist, wird auch als regionale Instanz bezeichnet und hat eine primäre und sekundäre Zone* innerhalb der konfigurierten Region. Innerhalb einer regionalen Instanz besteht die Konfiguration aus einer primären Instanz und einer Standby-Instanz. Durch synchrone Replikation auf den nichtflüchtigen Speicher jeder Zone werden alle an der primären Instanz ausgeführten Schreibvorgänge auf Laufwerken in beiden Zonen repliziert, bevor eine Transaktion als Commit gemeldet wird. Bei einem Ausfall einer Instanz oder Zone wird die Standby-Instanz zur neuen primären Instanz. Anschließend werden die Nutzer auf die neue primäre Instanz umgeleitet. Dieser Vorgang wird als failover bezeichnet.
Nach einem Failover bleibt die Instanz, die das Failover erhalten hat, weiterhin die primäre Instanz, auch wenn die ursprüngliche Instanz wieder online ist. Sobald die Zone oder Instanz, in der ein Ausfall aufgetreten ist, wieder verfügbar ist, wird die ursprüngliche primäre Instanz gelöscht und neu erstellt. Dann wird sie zur neuen Standby-Instanz. Wenn ein Failover in Zukunft stattfindet, führt ein Failover der neuen primären Instanz auf die ursprüngliche Instanz in der ursprünglichen Zone durch.
Wenn Sie die primäre Instanz in der Zone haben, die den Ausfall verursacht hat, können Sie ein Failback ausführen. Ein Failback führt dieselben Schritte wie ein Failover aus, nur in der Gegenrichtung, um Traffic zurück zur ursprünglichen Instanz zu leiten. Verwenden Sie das Verfahren unter Failover initialisieren, um ein Failback auszuführen.
Der regionale Support für nichtflüchtigen Speicher für die Cloud SQL-Konfiguration für Hochverfügbarkeit mit mindestens einer dedizierten CPU bietet eine vollständige Service Level Agreement (SLA)-Abdeckung. Eine für Hochverfügbarkeit konfigurierte Instanz kostet doppelt so viel wie eine eigenständige Instanz. Der Preis umfasst CPU, Arbeitsspeicher und Speicher. Weitere Informationen finden Sie auf der Preisseite.
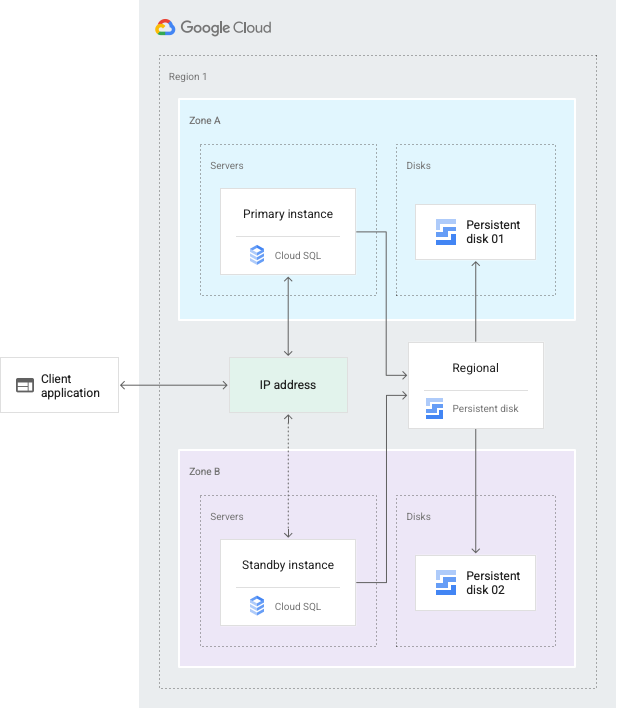
* Die Regionen Mexiko, Montreal und Osaka haben drei Zonen in einem oder zwei physischen Rechenzentren. In diesen Regionen wird derzeit auf mindestens drei physische Rechenzentren erweitert. Weitere Informationen finden Sie unter Cloudstandorte und SLAs für die Google Cloud Platform. Um die Zuverlässigkeit Ihrer Arbeitslasten zu verbessern, sollten Sie eine mehrere Regionen umfassende Bereitstellung in Betracht ziehen.
Lesereplikate
Wenn die Verfügbarkeit für Ihre Lesereplikate eine Rolle spielt, können Sie Hochverfügbarkeit für die Replikate aktivieren. Wenn Sie ein solches Replikat zur primären Instanz hochstufen, ist es bereits als hochverfügbare Instanz eingerichtet.
Während eines Zonenausfalls wird der Traffic zu Lesereplikaten in dieser Zone angehalten. Sobald die Zone wieder verfügbar ist, setzen alle Lesereplikate in der Zone die Replikation von der primären Instanz fort. Wenn sich Lesereplikate nicht in einer Zone befinden, die ausgefallen ist, werden sie mit der Standby-Instanz verbunden, wenn diese zur primären Instanz wird.
Als Best Practice empfehlen wir, einige Ihrer Lesereplikate in einer anderen Zone als der primären Instanz und Standby-Instanz zu platzieren. Wenn Sie beispielsweise eine primäre Instanz in Zone A und eine Standby-Instanz in Zone B haben, fügen Sie ein Lesereplikat in Zone C hinzu, um die Zuverlässigkeit zu erhöhen. Diese Vorgehensweise gewährleistet, dass Lesereplikate auch dann funktionieren, wenn die Zone für die primäre Instanz ausfällt. Sie sollten auch eine Geschäftslogik in der Client-Anwendung hinzufügen, um Lesevorgänge an die primäre Instanz zu senden, wenn Lesereplikate nicht verfügbar sind.
Hinweis: Die Standby-Instanz kann nicht für Leseanfragen verwendet werden. Dies unterscheidet sich von der Legacy-Hochverfügbarkeitskonfiguration für Cloud SQL for MySQL.
Failover – Übersicht
Wenn eine für hohe Verfügbarkeit konfigurierte Instanz nicht mehr reagiert, wechselt Cloud SQL zum Bereitstellen von Daten automatisch zur Stand-by-Instanz. Im Failover-Verlauf des Vorgangslogs können Sie sehen, ob ein Failover aufgetreten ist.
Weitere Informationen dazu, wie Sie Abfragen im Log-Explorer erstellen. Wenn Sie genauere Informationen zu einem Vorgang benötigen, z. B. den Nutzer, der den Vorgang ausgeführt hat, müssen Sie das Audit-Logging aktivieren.
Klicken Sie auf die Tabs, um zu sehen, wie sich das Failover auf die Instanz auswirkt.
Normal

Failover

Nach dem Failover

Failback
Prozess
Der folgende Prozess läuft ab:
Die primäre Instanz oder Zone schlägt fehl.
Jede Sekunde erkennt das Heartbeat-System, ob die primäre Instanz fehlerfrei ist. Wenn mehrere Heartbeats ausbleiben, wird ein Failover ausgelöst.
Sobald die Standby-Instanz neu verbunden ist, liefert sie die Daten.
Die Standby-Instanz liefert nun Daten aus der sekundären Zone über eine gemeinsame statische IP-Adresse mit der primären Instanz.
Voraussetzungen
Damit Cloud SQL ein Failover zulässt, muss die Konfiguration die folgenden Anforderungen erfüllen:
- Die primäre Instanz muss in einem normalen Betriebszustand sein (d. h. sie darf nicht angehalten sein, gewartet werden oder einen lang andauernden Cloud SQL-Instanzvorgang ausführen, etwa einen Sicherungsvorgang).
- Die sekundäre Zone und die Standby-Instanz müssen beide in einem fehlerfreien Zustand sein. Wenn die Standby-Instanz nicht mehr reagiert, werden Failover-Vorgänge blockiert. Nachdem Cloud SQL die Standby-Instanz repariert hat und die sekundäre Zone wieder verfügbar ist, erlaubt Cloud SQL einen Failover.
Sichern und wiederherstellen
Automatische Instanzen und Wiederherstellung zu einem bestimmten Zeitpunkt müssen für Hochverfügbarkeitsinstanzen aktiviert sein, mit Ausnahme von Lesereplikaten.
Anwendungen und Instanzen
Es macht keinen Unterschied, ob Sie mit Instanzen mit hoher Verfügbarkeit oder ohne hohe Verfügbarkeit arbeiten. Daher muss Ihre Anwendung nicht auf eine bestimmte Weise konfiguriert werden. Wenn ein Failover auftritt, werden alle vorhandenen Verbindungen zur primären Instanz und den Lesereplikaten geschlossen. Es dauert etwa 2 bis 3 Minuten, bis die Verbindungen zur primären Instanz wiederhergestellt sind. Ihre Anwendung kann jedoch die Verbindung mit demselben Verbindungsstring oder derselben IP-Adresse wiederherstellen, sodass Sie die Anwendung nach dem Failover nicht aktualisieren müssen.
Sie können ein Failover manuell auslösen, um genau zu sehen, wie sich ein Failover auf Ihre Anwendungen auswirkt.
Wartungsausfallzeit
Wartungsereignisse wirken sich auf mit Hochverfügbarkeit konfigurierte primäre Instanzen auf die gleiche Weise aus wie auf jede andere Instanz. Sie können davon ausgehen, dass die primären Instanzen für einen kurzen Zeitraum nicht verfügbar sind. Weitere Informationen dazu, wie sich die Wartung auf Hochverfügbarkeitsinstanzen auswirkt, finden Sie unter So funktioniert die Wartung. Um die Auswirkungen auf Ihren Dienst zu minimieren, ändern Sie die Wartungseinstellungen, um zu steuern, wann Ausfallzeiten auftreten.
Leistung
Die Leistung nichtflüchtiger Speicher hängt von vielen Faktoren ab. Die Eingabe-/Ausgabevorgänge pro Sekunde (IOPS) können bei regionalen nichtflüchtigen Speichern im Vergleich zum zonalen nichtflüchtigen Speicher reduziert werden. Beachten Sie den VM-Instanztyp und die Arbeitslasteingabe und -ausgabe. Ein weiterer zu beachtender Messwert ist, dass die Latenz für regionalen nichtflüchtigen Speicher mit SSDs (Solid State Drives) höher ist als für nichtflüchtige Speicher mit SSDs. Dies bedeutet, dass Ihre Arbeitslast, wenn sie keine Streamingarbeitslast und latenzempfindlich ist, das IOPS-Limit nicht erreichen kann, da ein regionaler nichtflüchtiger Speicher mit SSD eine höhere Latenz hat als ein zonaler nichtflüchtiger Speicher mit SSD. Dies liegt an der synchronen Replikation der Daten über mehrere Zonen hinweg, die an einem regionalen nichtflüchtigen Speicher beteiligt sind, um mehrere Kopien von Daten in den Zonen einer Region bereitzustellen.
Alte MySQL-Hochverfügbarkeitsoption
Der Legacy-Prozess zum Hinzufügen der Hochverfügbarkeit zu MySQL-Instanzen verwendet ein Failover-Replikat. Das Legacy-Feature ist in der Google Cloud Console nicht verfügbar. Weitere Informationen erhalten Sie unter Legacy-Konfiguration: Neue Instanz mit Hochverfügbarkeit erstellen oder Legacy-Konfiguration: Eine bestehende Instanz für Hochverfügbarkeit konfigurieren.
Nächste Schritte
- Hochverfügbarkeit für eine Instanz aktivieren und deaktivieren
- Failover auslösen
- Mehr über die Verwaltung von Datenbankverbindungen erfahren
- Mehr zu Regionen und Zonen in Cloud SQL