In today’s world, technology is evolving at a rapid pace. One of the advanced developments is edge computing. But what exactly is it? And why is it becoming so important? This article will explore edge computing and why it is considered the new frontier in international data science trends.
Understanding edge computing
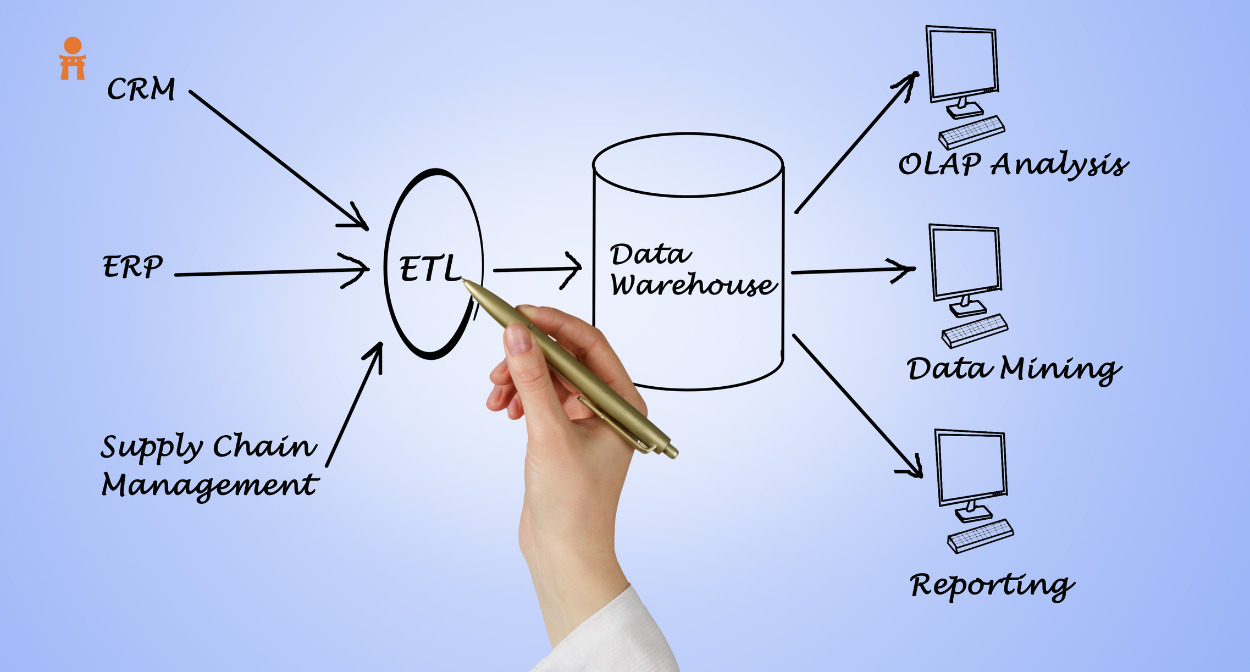
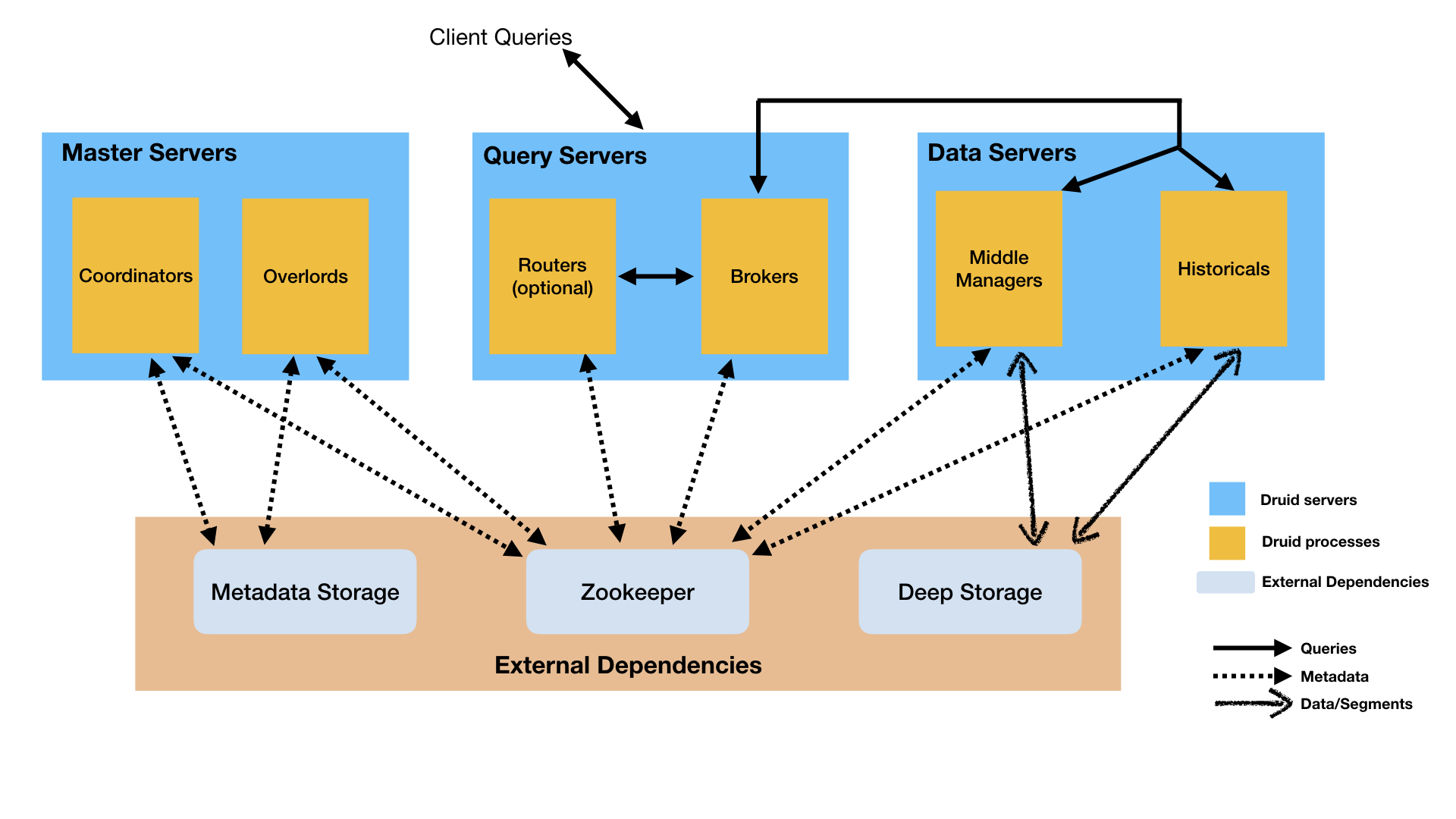
Edge computing is a method where data processing happens closer to where it is generated rather than relying on a centralized data-processing warehouse. This means faster response times and less strain on network resources.
Some of the main characteristics of edge computing include:
- Speed: Faster data processing and analysis.
- Efficiency: Less bandwidth usage, which means lower costs.
- Reliability: More stable, as it doesn’t depend much on long-distance data transmission.
Benefits of implementing edge computing
Implementing edge computing can bring several benefits, such as:
- Improved performance: It can be analyzed more quickly by processing data locally.
- Enhanced security: Data is less vulnerable as it doesn’t travel long distances.
- Scalability: It’s easier to expand the system as needed.
Read more –> Guide to LLM chatbots: Real-life applications
Data processing at the edge
In data science, edge computing is emerging as a pivotal force, enabling faster data processing directly at the source. This acceleration in data handling allows for realizing real-time insights and analytics previously hampered by latency issues.
Consequently, it requires solid knowledge of the field, either earned through experience or through the best data science course, fostering a more dynamic and responsive approach to data analysis, paving the way for innovations and advancements in various fields that rely heavily on data-driven insights.

Real-time analytics and insights
Edge computing revolutionizes business operations by facilitating instantaneous data analysis, allowing companies to glean critical insights in real-time. This swift data processing enables businesses to make well-informed decisions promptly, enhancing their agility and responsiveness in a fast-paced market.
Consequently, it empowers organizations to stay ahead, giving opportunities to their employees to learn PG in Data Science, optimize their strategies, and seize opportunities more effectively.
Enhancing data security and privacy
Edge computing enhances data security significantly by processing data closer to its generation point, thereby reducing the distance it needs to traverse.
This localized approach diminishes the opportunities for potential security breaches and data interceptions, ensuring a more secure and reliable data handling process. Consequently, it fosters a safer digital ecosystem where sensitive information is better shielded from unauthorized access and cyber threats.
Adoption rates in various regions
The adoption of edge computing is witnessing a varied pace across different regions globally. Developed nations, with their sophisticated infrastructure and technological advancements, are spearheading this transition, leveraging the benefits of edge computing to foster innovation and efficiency in various sectors.
This disparity in adoption rates underscores the pivotal role of robust infrastructure in harnessing the full potential of this burgeoning technology.
Successful implementations of edge computing
Across the globe, numerous companies are embracing the advantages of edge computing, integrating it into their operational frameworks to enhance efficiency and service delivery.
By processing data closer to the source, these firms can offer more responsive and personalized services to their customers, fostering improved customer satisfaction and potentially driving a competitive edge in their respective markets. This successful adoption showcases the tangible benefits and transformative potential of edge computing in the business landscape.
Government policies and regulations
Governments globally are actively fostering the growth of edge computing by formulating supportive policies and regulations. These initiatives are designed to facilitate the seamless integration of this technology into various sectors, promoting innovation and ensuring security and privacy standards are met.
Through such efforts, governments are catalyzing a conducive environment for the flourishing of edge computing, steering society towards a more connected and efficient future.
Infrastructure challenges
Despite its promising prospects, edge computing has its challenges, particularly concerning infrastructure development. Establishing the requisite infrastructure demands substantial investment in time and resources, posing a significant challenge. The process involves the installation of advanced hardware and the development of compatible software solutions, which can be both costly and time-intensive, potentially slowing the pace of its widespread adoption.
Security concerns
While edge computing brings numerous benefits, it raises security concerns, potentially opening up new avenues for cyber vulnerabilities. Data processing at multiple nodes instead of a centralized location might increase the risk of data breaches and unauthorized access. Therefore, robust security protocols will be paramount as edge computing evolves to safeguard sensitive information and maintain user trust.
Solutions and future directions
A collaborative approach between businesses and governments is emerging to navigate the complexities of implementing edge computing. Together, they craft strategies and policies that foster innovation while addressing potential hurdles such as security concerns and infrastructure development.
This united front is instrumental in shaping a conducive environment for the seamless integration and growth of edge computing in the coming years.
Healthcare sector
In healthcare, computing is becoming a cornerstone for advancing patient care. It facilitates real-time monitoring and swift data analysis, providing timely interventions and personalized treatment plans. This enhances the accuracy and efficacy of healthcare services and potentially saves lives by enabling quicker responses in critical situations.
Manufacturing industry
In the manufacturing sector, it is vital to streamlining and enhancing production lines. By enabling real-time data analysis directly on the factory floor, it assists in fine-tuning processes, minimizing downtime, and predicting maintenance needs before they become critical issues.
Consequently, it fosters a more agile, efficient, and productive manufacturing environment, paving the way for heightened productivity and reduced operational costs.
Smart cities
Smart cities envisioned as the epitome of urban innovation, are increasingly harnessing the power of edge computing to revolutionize their operations. By processing data in affinity to its source, edge computing facilitates real-time responses, enabling cities to manage traffic flows, thereby reducing congestion and commute times.
Furthermore, it aids in deploying advanced sensors that monitor and mitigate pollution levels, ensuring cleaner urban environments. Beyond these, edge computing also streamlines public services, from waste management to energy distribution, ensuring they are more efficient, responsive, and tailored to the dynamic needs of urban populations.
Integration with IoT and 5G
As we venture forward, edge computing is slated to meld seamlessly with burgeoning technologies like the Internet of Things (IoT) and 5G networks. This integration is anticipated to unlock many benefits, including lightning-fast data transmission, enhanced connectivity, and the facilitation of real-time analytics.
Consequently, this amalgamation is expected to catalyze a new era of technological innovation, fostering a more interconnected and efficient world.
Read more –> IoT | New trainings at Data Science Dojo
Role in Artificial Intelligence and Machine Learning
Edge computing stands poised to be a linchpin in the revolution of artificial intelligence (AI) and machine learning (ML). Facilitating faster data processing and analysis at the source will empower these technologies to function more efficiently and effectively. This synergy promises to accelerate advancements in AI and ML, fostering innovations that could reshape industries and redefine modern convenience.
Predictions for the next decade
In the forthcoming decade, the ubiquity of edge computing is set to redefine our interaction with data fundamentally. This technology, by decentralizing data processing and bringing it closer to the source, promises swifter data analysis and enhanced security and efficiency.
As it integrates seamlessly with burgeoning technologies like IoT and 5G, we anticipate a transformative impact on various sectors, including healthcare, manufacturing, and urban development. This shift towards edge computing signifies a monumental leap towards a future where real-time insights and connectivity are not just luxuries but integral components of daily life, facilitating more intelligent living and streamlined operations in numerous facets of society.
Conclusion
Edge computing is shaping up to be a significant player in the international data science trends. As we have seen, it offers many benefits, including faster data processing, improved security, and the potential to revolutionize industries like healthcare, manufacturing, and urban planning. As we look to the future, the prospects for edge computing seem bright, promising a new frontier in the world of technology.
Remember, the world of technology is ever-changing, and staying informed is the key to staying ahead. So, keep exploring data science courses, keep learning, and keep growing!

Written by Erika Balla