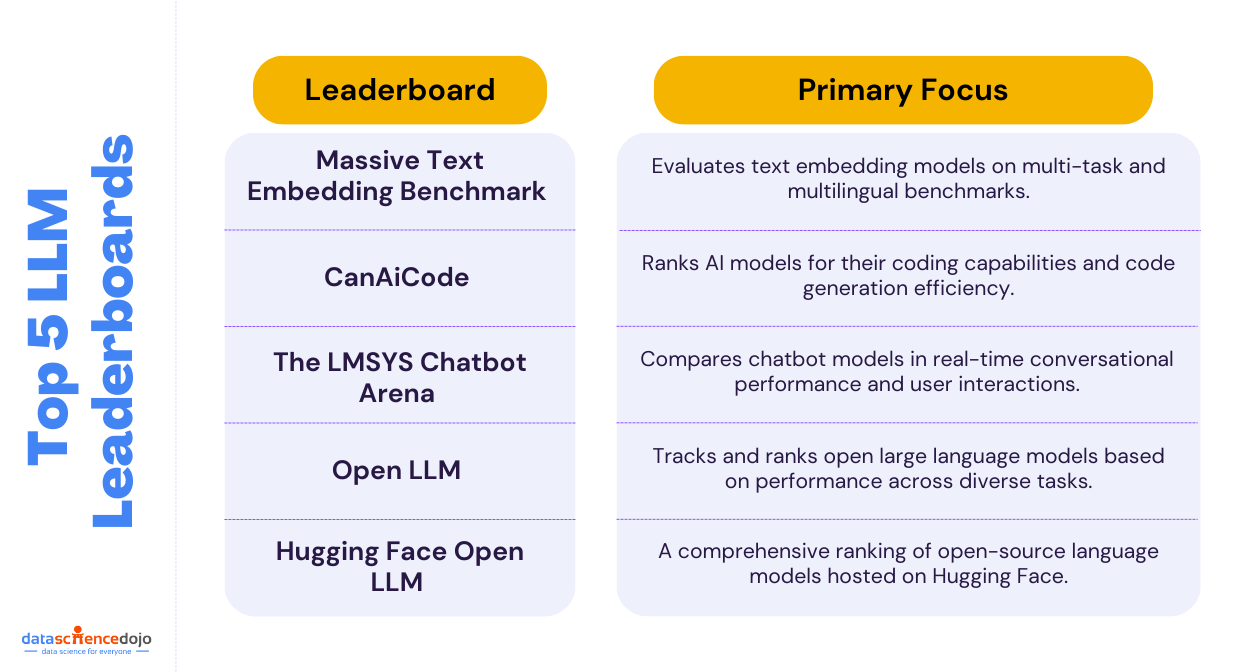
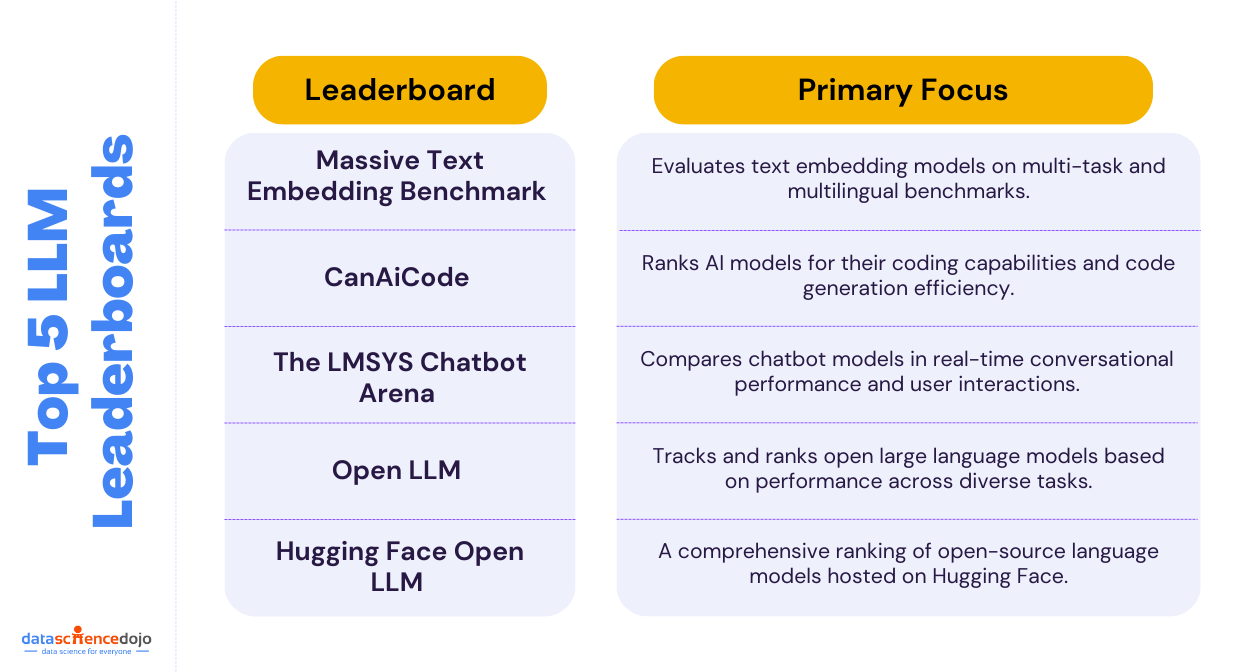
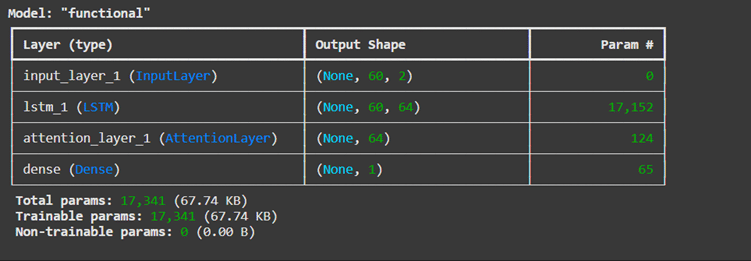
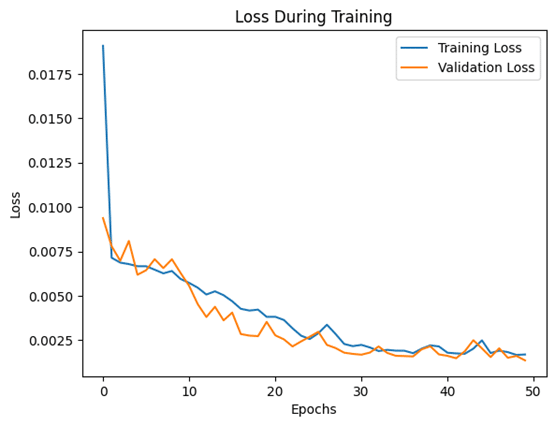
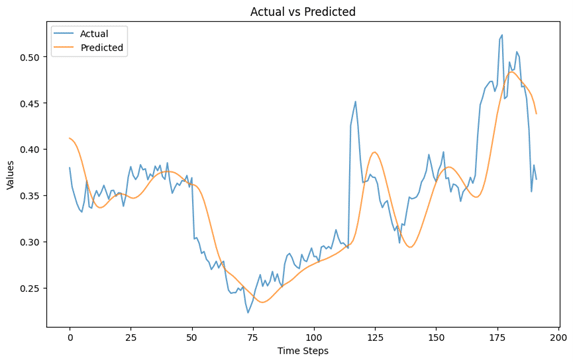
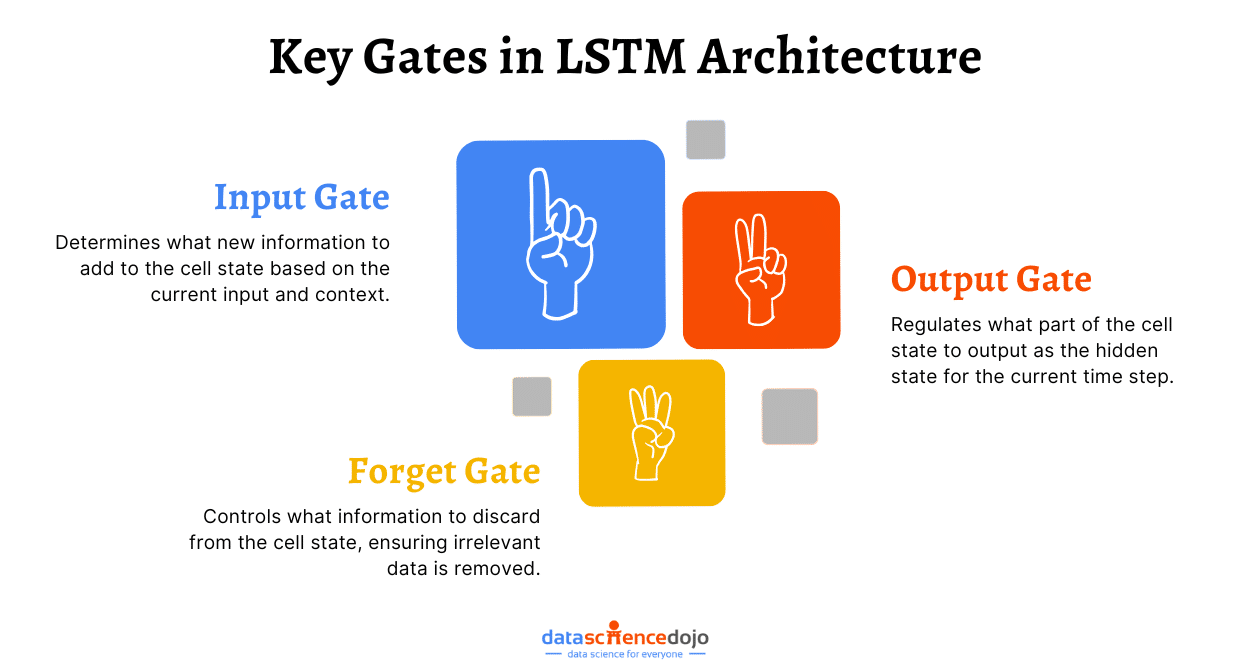
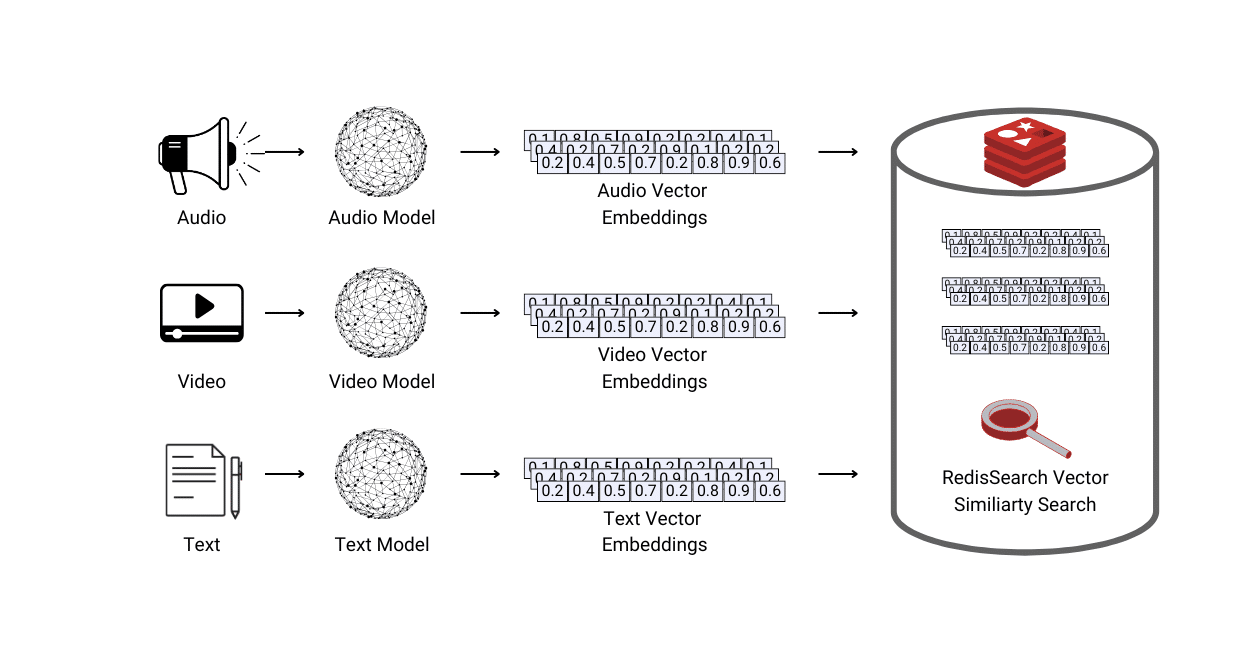
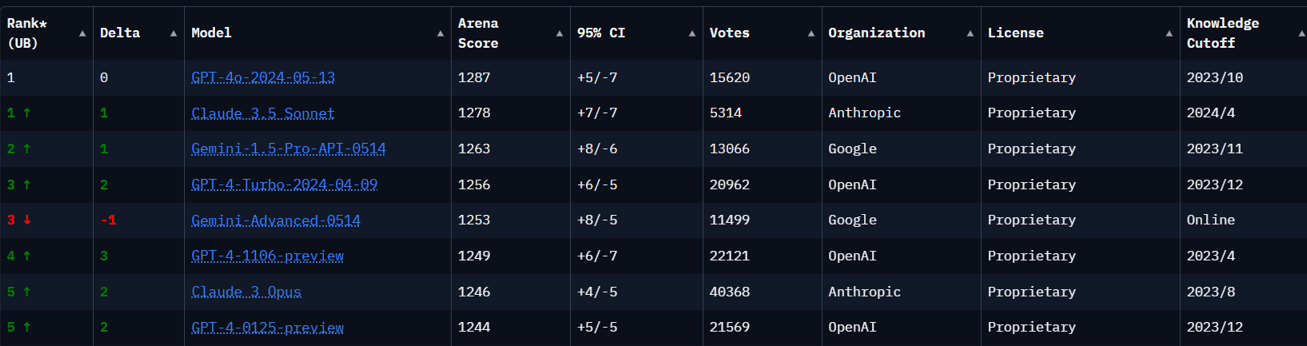
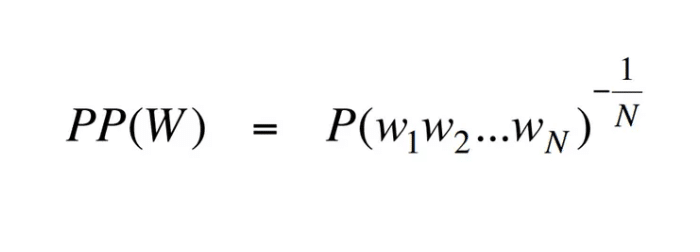In the rapidly evolving world of artificial intelligence, Large Language Models (LLMs) have become pivotal in transforming how machines understand and generate human language. To ensure these models are both effective and responsible, LLM benchmarks play a crucial role in evaluating their capabilities and limitations.
This blog delves into the significance of popular benchmarks for LLM and explores some of the most influential LLM benchmarks shaping the future of AI.
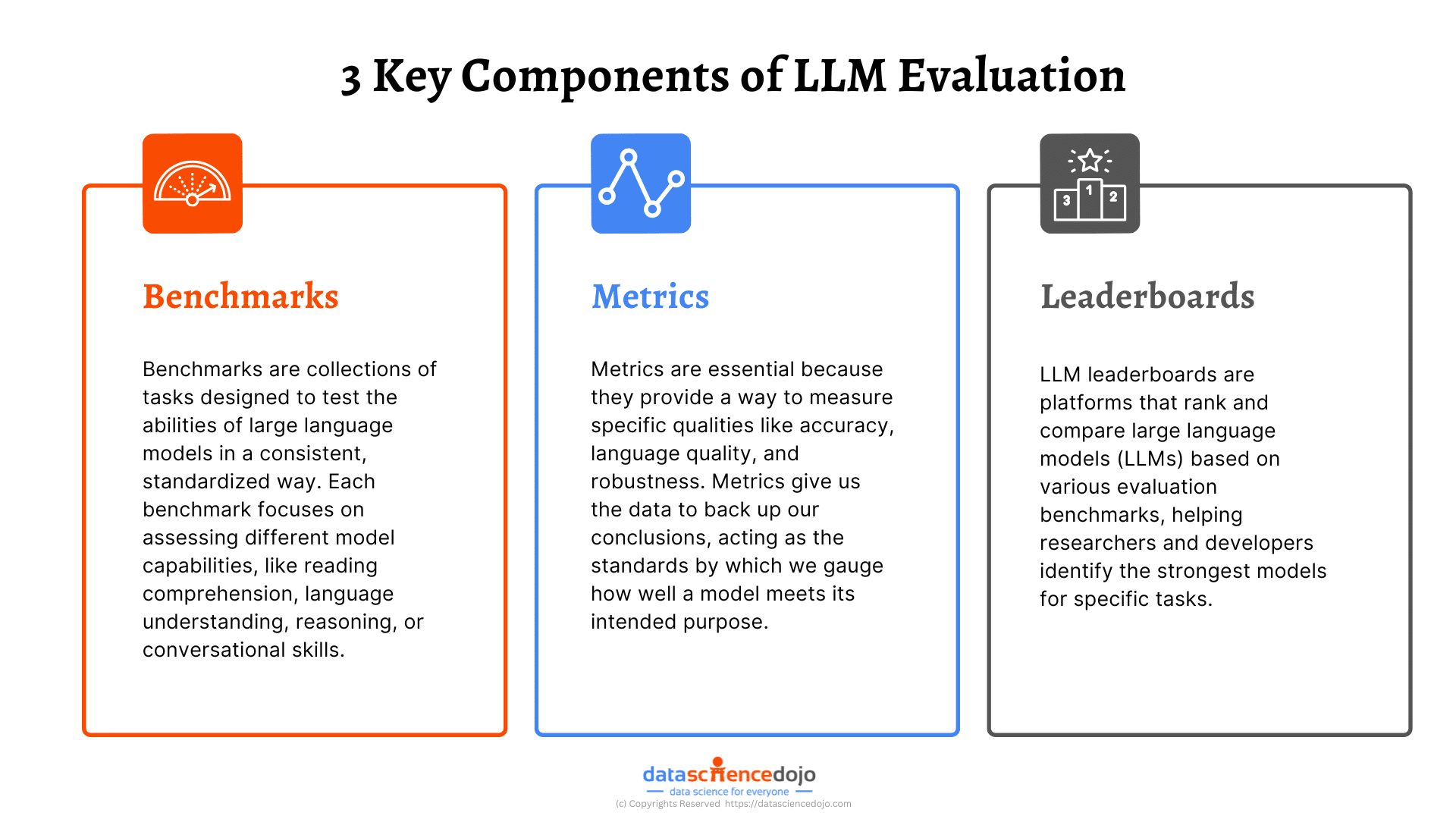
What is LLM Benchmarking?
LLM Benchmarks refers to the systematic evaluation of these models against standardized datasets and tasks. It provides a framework to measure their performance, identify strengths and weaknesses, and guide improvements. By using LLM benchmarks, researchers and developers can ensure that LLMs meet specific criteria for accuracy, efficiency, and ethical considerations.

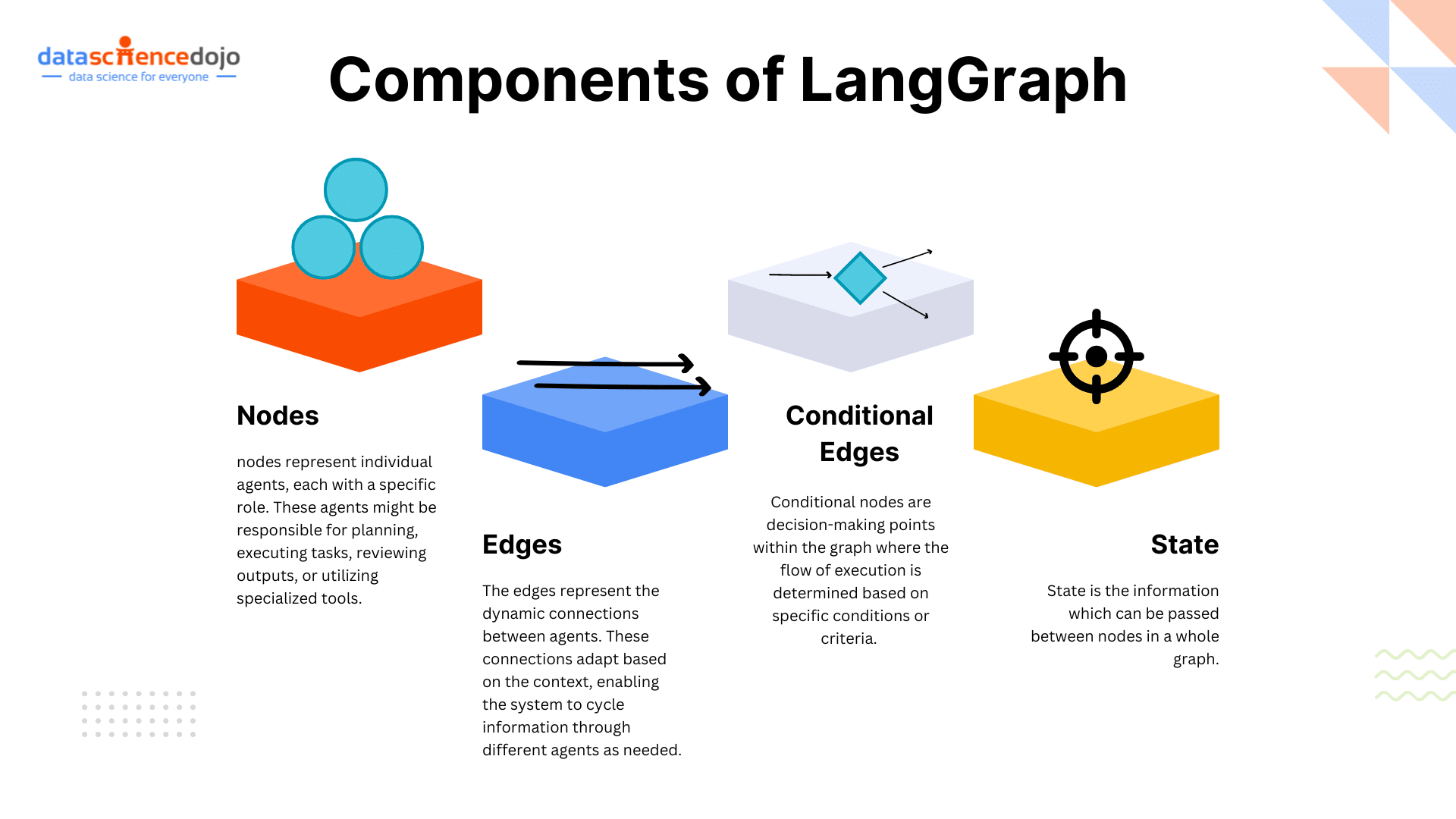
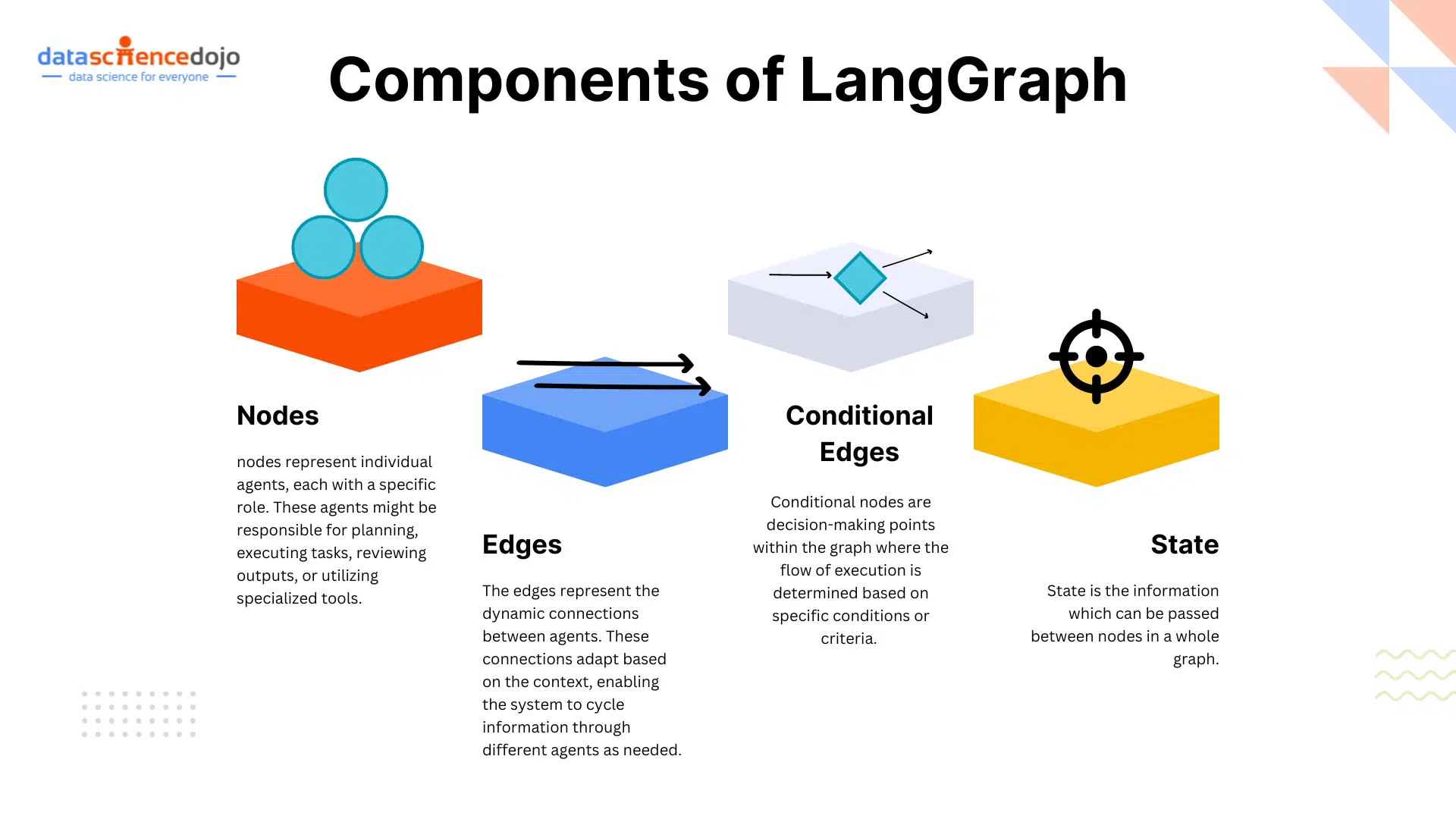
Key Aspects of LLM Benchmarks
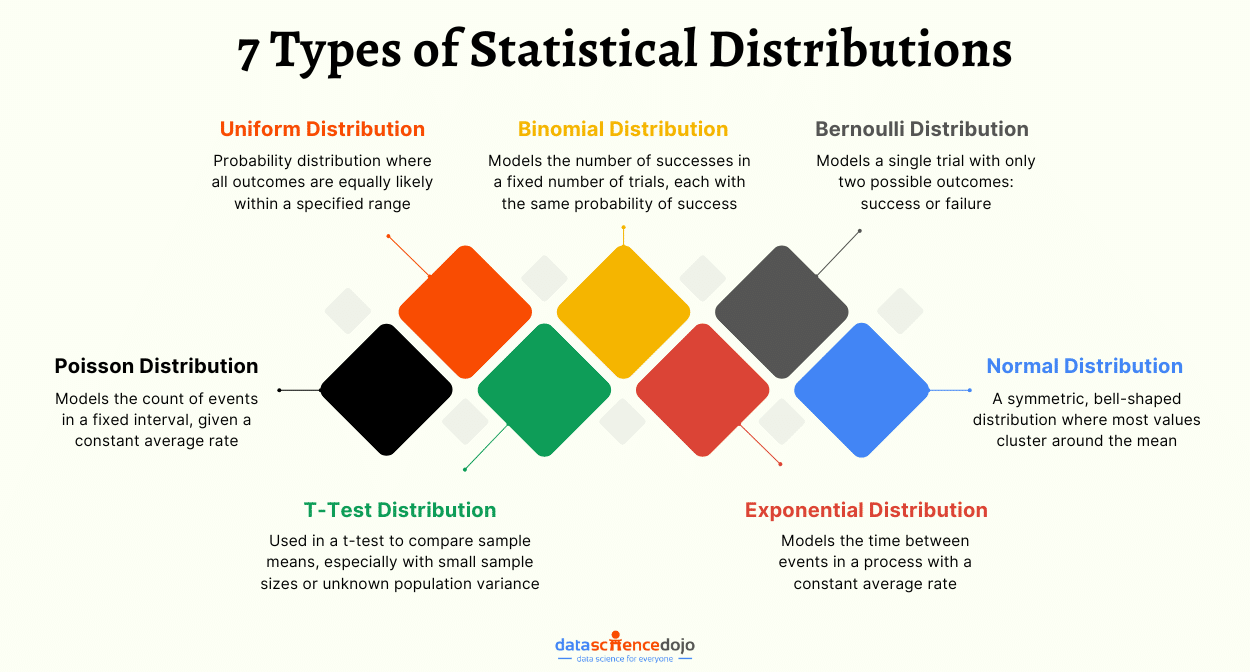
LLM benchmarks provide a set of standardized tests to assess various aspects of model performance. These benchmarks help in understanding how well a model performs across different tasks, ensuring a thorough evaluation of its capabilities.

Dimensions of LLM Evaluation
LLM benchmarks evaluate models across key areas to ensure strong performance in diverse tasks. Reasoning tests a model’s ability to think logically and solve problems, while language understanding checks how well it grasps grammar, meaning, and context for clear responses.
Understand LLM Evaluation: Metrics, Benchmarks, and Real-World Applications
Moreover, conversational abilities measure how smoothly the model maintains context in dialogues, and multilingual performance assesses its proficiency in multiple languages for global use. Lastly, tool use evaluates how effectively the model integrates with external systems to deliver accurate, real-time results.

Common Metrics
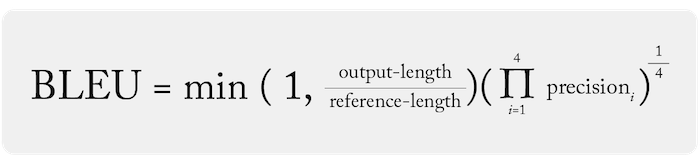
Metrics are essential for measuring an LLM’s performance in tasks like text generation, classification, and dialogue. Perplexity evaluates how well a model predicts word sequences, with lower scores indicating better accuracy. Metrics such as BLEU, ROUGE, and METEOR assess text quality by comparing outputs to reference texts.
For tasks like classification and question-answering, F1-Score, Precision, and Recall ensure relevant information is captured with minimal errors. In dialogue systems, win rate measures how often a model’s responses are preferred. Together, these metrics offer a clear view of a model’s strengths and areas for improvement.
Frameworks and Tools for LLM Benchmarks
Benchmarking frameworks provide a structured way to evaluate LLMs and compare their performance. For instance:
- OpenAI’s Evals enable customizable tests
- Hugging Face Datasets offer pre-built resources
- BIG-bench supports collaborative assessments
- EleutherAI’s LM Evaluation Harness ensures consistent and reliable benchmarking
These frameworks help developers identify strengths and weaknesses while ensuring models meet quality standards.
Popular LLM Benchmarks
Exploring key LLM benchmarks is crucial for comprehensive model evaluation, as they provide a set of standardized tests to assess various aspects of model performance. These benchmarks help in understanding how well a model performs across different tasks, ensuring a thorough evaluation of its capabilities.
Know more about LLM Guide: A Beginner’s Resource to the Decade’s Top Technology

MMLU (Massive Multitask Language Understanding)
MMLU (Massive Multitask Language Understanding) is designed to evaluate an LLM‘s ability to handle a wide range of tasks across different domains, humanities, sciences, and social sciences. It focuses on the comprehensiveness of the knowledge and reasoning capabilities of the model.
Learn how is LLM Development making Chatbots Smarter in 2023?
This LLM benchmark is developed to evaluate the breadth of a model’s knowledge and its capacity to generalize across multiple disciplines, making it ideal for assessing comprehensive language understanding. This also makes it one of the most challenging and diverse benchmarks when evaluating multitask learning.
The key features of the MMLU benchmark include:
- It covers diverse subjects which includes questions from 57 domains, covering a mix of difficulty levels
- It measures performance across many unrelated tasks to test strong generalization abilities
- MMLU uses multiple-choice questions (MCQs), where each question has four answer choices
- Along with general language understanding it also tests domain-specific knowledge, such as medical diagnostics or software engineering
- It provides benchmarks for human performance, allowing a comparison between model capabilities and expert knowledge
Benefits of MMLU
MMLU acts as a multitool for testing LLMs, allowing researchers to evaluate model performance across various subjects. This is particularly useful in real-world scenarios where models must handle questions from multiple domains. By using standardized tasks, MMLU ensures fair comparisons, highlighting which models excel.
Beyond ranking, MMLU checks if a model can transfer knowledge between areas, crucial for adaptable AI. Its challenging tasks push developers to create smarter systems, ensuring models are not just impressive on paper but also ready to tackle real-world problems where knowledge and reasoning matter.
Applications
Some key applications of the MMLU benchmark include:
Educational AI: MMLU evaluates AI’s ability to answer questions at various educational levels, enabling the development of intelligent tutoring systems. For instance, it can be used to develop AI teaching assistants to answer domain-specific questions.
Professional Knowledge Testing: The benchmark can be used to train and test LLMs in professional fields like healthcare, law, and engineering. Thus, it can support the development of AI tools to assist professionals such as doctors in their diagnosis.
Model Benchmarking for Research: Researchers use MMLU to compare the performance of LLMs like GPT-4, PaLM, or LLaMA, aiding in the discovery of strengths and weaknesses. It ensures a comprehensive comparison of language models with useful insights to study.
Multidisciplinary Chatbots: MMLU is one of the ideal LLM benchmarks for evaluating conversational agents that need expertise in multiple areas, such as customer service or knowledge retrieval. For example, an AI chatbot that has to answer both financial and technical queries can be tested using the MMLU benchmark.
Here’s your one-stop guide to LLMs and their applications
While these are suitable use cases for the MMLU benchmarks, we have seen its real-world example in the form of the GPT-4 model. The results highlighted the model’s ability to reason through complex questions across multiple domains.
SuperGLUE
As an advanced version of the GLUE benchmark, SuperGLUE presents more challenging tasks that require nuanced understanding and reasoning. It evaluates a model’s performance on tasks like reading comprehension, common sense reasoning, and natural language inference.
SuperGLUE is an advanced tool for LLM benchmarks designed to push the boundaries of language model evaluation. It builds upon the original GLUE benchmark by introducing more challenging tasks that require nuanced understanding and reasoning.
The key features of the MMLU benchmark include:
- Includes tasks that require higher-order thinking, such as reading comprehension.
- Covers a wide range of tasks, ensuring comprehensive evaluation across different aspects of language processing.
- Provides benchmarks for human performance, allowing a direct comparison with model capabilities.
- Tests models on their ability to perform logical reasoning and comprehend complex scenarios.
- Evaluates a model’s ability to generalize knowledge across various domains and tasks.
Benefits
SuperGLUE enhances model evaluation by presenting challenging tasks that delve into a model’s capabilities and limitations. It includes tasks requiring advanced reasoning and nuanced language understanding, essential for real-world applications.
Understand how to Revolutionize LLM with Llama 2 fine-tuning
The complexity of SuperGLUE tasks drives researchers to develop more sophisticated models, leading to advanced algorithms and techniques. This pursuit of excellence inspires new approaches that handle the intricacies of human language more effectively, advancing the field of AI.
Applications
Some key applications of the MMLU benchmark include:
Advanced Language Understanding: It evaluates a model’s ability to understand and process complex language tasks, such as reading comprehension, textual entailment, and coreference resolution.
Conversational AI: It evaluates and enhances chatbots and virtual assistants, ensuring they can handle complex interactions. For example, virtual assistants that need to understand customer queries.
Natural Language Processing Applications: Develops and refines NLP applications, ensuring they can handle language tasks effectively, such as sentiment analysis and question answering.
AI Research and Development: Researchers utilize SuperGLUE to explore new architectures and techniques to enhance language understanding, comparing the performance of different language models to identify areas for improvement and innovation.
HumanEval
HumanEval is a benchmark specifically designed to evaluate the coding capabilities of AI models. It presents programming tasks that require generating correct and efficient code, and challenging models to demonstrate their understanding of programming logic and syntax.
It provides a platform for testing models on tasks that demand a deep understanding of programming, making it a critical tool for assessing advanced coding skills. Some of the key features of the HumanEval Benchmark include:
- Tasks that require a deep understanding of programming logic and syntax.
- A wide range of coding challenges, ensuring comprehensive evaluation across different programming scenarios.
- LLM Benchmarks for human performance, allowing direct comparison with model capabilities.
- Tests models on their ability to generate correct and efficient code.
- Evaluates a model’s ability to handle complex programming tasks across various domains.
Benefits
HumanEval enhances model evaluation by presenting challenging coding tasks that delve into a model’s capabilities and limitations. It includes tasks requiring advanced problem-solving skills and programming knowledge, essential for real-world applications.
This comprehensive assessment helps researchers identify specific areas for improvement, guiding the development of more refined models to meet complex coding demands. The complexity of HumanEval tasks drives researchers to develop more sophisticated models, leading to advanced algorithms and techniques.
Applications
Some key applications of the HumanEval benchmark include:
AI-Driven Coding Tools: HumanEval is used to evaluate and enhance AI-driven coding tools, ensuring they can handle complex programming challenges. For example, AI systems that assist developers in writing efficient and error-free code.
Versatile Coding Models: HumanEval’s role in LLM benchmarks extends to supporting the development of versatile coding models, encouraging the creation of systems capable of handling multiple programming tasks simultaneously.
It serves as a critical benchmark in the realm of LLM benchmarks, fostering the development and refinement of applications that can adeptly manage complex programming tasks.

GPQA (General Purpose Question Answering)
GPQA tests a model’s ability to answer a wide range of questions, from factual to opinion-based, across various topics. This benchmark evaluates the versatility and adaptability of a model in handling diverse question types, making it essential for applications in customer support and information retrieval.
The key features of the GPQA Benchmark include:
- This benchmark is in a realm of LLM benchmarks that require understanding and answering questions across various domains.
- A comprehensive range of topics, ensuring thorough evaluation of general knowledge.
- Benchmarks for human performance, allowing direct comparison with model capabilities.
- Test models on their ability to provide accurate and contextually relevant answers.
- Evaluates a model’s ability to handle diverse and complex queries.
Benefits
GPQA presents a diverse array of question-answering tasks that test a model’s breadth of knowledge and comprehension skills. As one of the key LLM benchmarks, it challenges models with questions from various domains, ensuring that AI systems are capable of understanding context in human language.
Another key benefit of GPQA, as part of the LLM benchmarks, is its role in advancing the field of NLP by providing a comprehensive evaluation framework. It helps researchers and developers understand how well AI models can process and interpret human language.
Applications
Following are some major applications of GPQA.
Conversational AI: It develops chatbots and virtual assistants that can handle a wide range of user queries. For instance, a customer service chatbot powered by GPQA could assist users with troubleshooting technical issues, providing step-by-step solutions based on the latest product information.
NLP Applications: GPQA supports the development of NLP applications. In the healthcare industry, for example, an AI system could assist doctors by answering complex medical questions and suggesting potential diagnoses based on patient symptoms.
This benchmark is instrumental in guiding researchers to refine algorithms to improve accuracy and relevance in responses. It fosters innovation in AI development by encouraging the creation of complex models.
BFCL (Benchmark for Few-Shot Learning)
BFCL focuses on evaluating a model’s ability to learn and adapt from a limited number of examples. It tests the model’s few-shot learning capabilities, which are essential for applications where data is scarce, such as personalized AI systems and niche market solutions.
It encourages the development of models that can adapt to new tasks with minimal training accelerating the deployment of AI solutions. The features of the BFCL benchmark include:
- Tasks that require learning from a few examples.
- A wide range of scenarios, ensuring comprehensive evaluation of learning efficiency.
- Benchmarks for human performance, allowing direct comparison with model capabilities.
- Tests models on their ability to generalize knowledge from limited data.
- Evaluates a model’s ability to adapt quickly to new tasks.
Benefits
BFCL plays a pivotal role in advancing the field of few-shot learning by providing a rigorous framework for evaluating a model’s ability to learn from limited data. Another significant benefit of BFCL, within the context of LLM benchmarks, is its potential to democratize AI technology.
By enabling models to learn effectively from a few examples, BFCL reduces the dependency on large datasets, making AI development more accessible to organizations with limited resources. It also contributes to the development of versatile AI systems.
By evaluating a model’s ability to learn from limited data, BFCL helps researchers identify and address the challenges associated with few-shot learning, such as overfitting and poor generalization.
Applications
Some of the mentionable applications include:
Rapid Adaptation: In the field of personalized medicine, BFCL, as part of LLM benchmarks, can be used to develop AI models that quickly adapt to individual patient data, providing tailored treatment recommendations based on a few medical records.
AI Research and Development: BFCL supports researchers in advancements, for example, in the field of robotics, few-shot learning models can be trained to perform new tasks with minimal examples, enabling robots to adapt to different environments and perform a variety of functions.
Versatile AI Systems: In the retail industry, BFCL can be applied to develop AI systems that quickly learn customer preferences from a few interactions, providing personalized product recommendations and improving the overall shopping experience.
MGSM (Mathematical Grade School Math)
MGSM is a benchmark designed to evaluate the mathematical problem-solving capabilities of AI models at the grade school level. It challenges models to solve math problems accurately and efficiently, testing their understanding of mathematical concepts and operations.
This benchmark is crucial for assessing a model’s ability to handle basic arithmetic and problem-solving tasks. Key Features of the MGSM Benchmark are:
- Tasks that require solving grade school math problems.
- A comprehensive range of mathematical concepts, ensuring thorough evaluation of problem-solving skills.
- Benchmarks for human performance, allowing direct comparison with model capabilities.
- Tests models on their ability to perform accurate calculations and logical reasoning.
- Evaluates a model’s ability to understand and apply mathematical concepts.
Benefits
MGSM provides a valuable framework for evaluating the mathematical problem-solving capabilities of AI models at the grade school level. As one of the foundational LLM benchmarks, it helps researchers identify areas where models may struggle, guiding the development of more effective algorithms that can perform accurate calculations and logical reasoning.
Another key benefit of MGSM, within the realm of LLM benchmarks, is its role in enhancing educational tools and resources. By evaluating a model’s ability to solve grade school math problems, MGSM supports the development of AI-driven educational applications that assist students in learning and understanding math concepts.
Applications
Key applications for the MGSM include:
Mathematical Problem Solving: In educational settings, MGSM, as part of LLM benchmarks, can be used to develop intelligent tutoring systems that provide students with instant feedback on their math problems, helping them understand and master mathematical concepts.
AI-Driven Math Tools: MGSM can be used to develop AI tools that assist analysts in performing calculations and analyzing financial data, automating routine tasks, such as calculating interest rates or evaluating investment portfolios.
MGSM enhances model evaluation by presenting challenging mathematical tasks that delve into a model’s capabilities and limitations. It includes tasks requiring basic arithmetic and logical reasoning, essential for real-world applications.
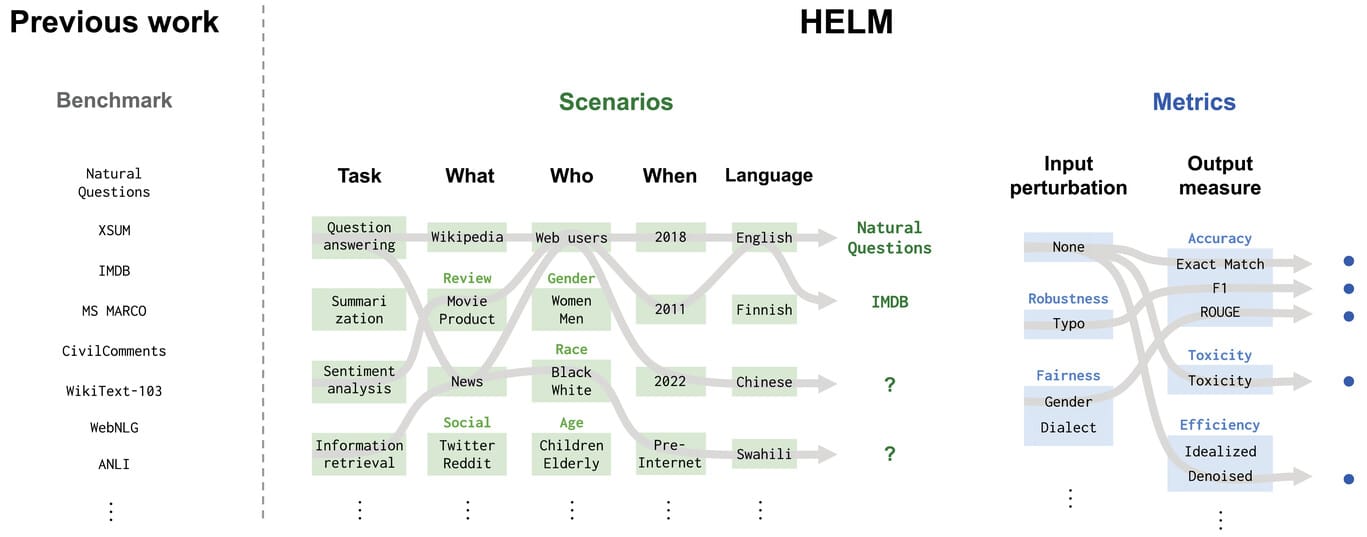
HELM (Holistic Evaluation of Language Models)
HELM is a benchmark designed to provide a comprehensive evaluation of language models across various dimensions. It challenges models to demonstrate proficiency in multiple language tasks, testing their overall language understanding and processing capabilities.
This benchmark is crucial for assessing a model’s holistic performance. Key Features of the HELM Benchmark Include:
- Tasks that require proficiency in multiple language dimensions.
- A wide range of language tasks, ensuring comprehensive evaluation of language capabilities.
- Benchmarks for human performance, allowing direct comparison with model capabilities.
- Tests model on their ability to handle diverse language scenarios.
- Evaluates a model’s ability to generalize language knowledge across tasks.
Benefits
HELM provides a comprehensive framework for evaluating the language capabilities of AI models across multiple dimensions. This benchmark is instrumental in identifying the strengths and weaknesses of language models, guiding researchers in refining algorithms to improve overall language understanding and processing capabilities.
For instance, a HELM-trained model could help doctors by providing quick access to medical knowledge, assist financial analysts by answering complex economic queries, or aid lawyers by retrieving relevant legal precedents. This capability not only enhances efficiency but also ensures that decisions are informed by accurate and comprehensive data.
Applications
Key applications of HELM include:
Comprehensive Language Understanding: In the field of customer service, HELM, as part of LLM benchmarks, can be used to develop chatbots that understand and respond to customer inquiries with accuracy and empathy.
Conversational AI: In the healthcare industry, HELM can be applied to develop virtual assistants that support doctors and nurses by providing evidence-based recommendations and answering complex medical questions.
AI Research and Development: In the field of legal research, HELM supports the development of AI systems capable of analyzing legal documents and providing insights into case law and regulations. These systems can assist lawyers in preparing cases to understand relevant legal precedents and statutes.
HELM contributes to the development of AI systems that can assist in decision-making processes. By accurately understanding and generating language, AI models can support professionals in fields such as healthcare, finance, and law.
MATH
MATH is a benchmark designed to evaluate the advanced mathematical problem-solving capabilities of AI models. It challenges models to solve complex math problems, testing their understanding of higher-level mathematical concepts and operations.
This benchmark is crucial for assessing a model’s ability to handle advanced mathematical reasoning. Key Features of the MATH Benchmark include:
- Tasks that require solving advanced math problems.
- A comprehensive range of mathematical concepts, ensuring thorough evaluation of problem-solving skills.
- Benchmarks for human performance, allowing direct comparison with model capabilities.
- Tests models on their ability to perform complex calculations and logical reasoning.
- Evaluates a model’s ability to understand and apply advanced mathematical concepts.
Benefits
MATH provides a rigorous framework for evaluating the advanced mathematical problem-solving capabilities of AI models. As one of the advanced LLM benchmarks, it challenges models with complex math problems, ensuring that AI systems can handle higher-level mathematical concepts and operations, which are essential for a wide range of applications.
Within the realm of LLM benchmarks, the role of MATH is in enhancing educational tools and resources. By evaluating a model’s ability to solve advanced math problems, MATH supports the development of AI-driven educational applications that assist students in learning and understanding complex mathematical concepts.
Applications
Major applications include:
Advanced Mathematical Problem Solving: In the field of scientific research, MATH, as part of LLM benchmarks, can be used to develop AI models that assist researchers in solving complex mathematical problems, such as those encountered in physics and engineering.
AI-Driven Math Tools: In the finance industry, MATH can be applied to develop AI tools that assist analysts in performing complex financial calculations and modeling. These tools can automate routine tasks, such as calculating risk metrics or evaluating investment portfolios, allowing professionals to focus on more complex analyses.
NLP Applications: In the field of data analysis, MATH supports the development of AI systems capable of handling mathematical queries and tasks. For instance, an AI-powered data analysis tool could assist researchers in performing statistical analyses, generating visualizations, and interpreting results, streamlining the research process
MATH enables the creation of AI tools that support professionals in fields such as finance, engineering, and data analysis. These tools can perform calculations, analyze data, and provide insights, enhancing efficiency and accuracy in decision-making processes.
BIG-Bench
BIG-Bench is a benchmark designed to evaluate the broad capabilities of AI models across a wide range of tasks. It challenges models to demonstrate proficiency in diverse scenarios, testing their generalization and adaptability.
This benchmark is crucial for assessing a model’s overall performance. Key Features of the BIG-Bench Benchmark include:
- Tasks that require proficiency in diverse scenarios.
- A wide range of tasks, ensuring comprehensive evaluation of general capabilities.
- Benchmarks for human performance, allowing direct comparison with model capabilities.
- Tests models on their ability to generalize knowledge across tasks.
- Evaluates a model’s ability to adapt to new and varied challenges.
Benefits
BIG-Bench provides a comprehensive framework for evaluating the broad capabilities of AI models across a wide range of tasks. As one of the versatile LLM benchmarks, it challenges models with diverse scenarios, ensuring that AI systems can handle varied tasks, from language understanding to problem-solving.
Another significant benefit of BIG-Bench, within the context of LLM benchmarks, is its role in advancing the field of artificial intelligence. By providing a holistic evaluation framework, BIG-Bench helps researchers and developers understand how well AI models can generalize knowledge across tasks.
Applications
Application of BIG-Bench includes:
Versatile AI Systems: In the field of legal research, BIG-Bench supports the development of AI systems capable of analyzing legal documents and providing insights into case law and regulations. These systems can assist lawyers in preparing cases, ensuring an understanding of relevant legal precedents and statutes.
AI Research and Development: In the healthcare industry, BIG-Bench can be applied to develop virtual assistants that support doctors and nurses by providing evidence-based recommendations and answering complex medical questions.
General Capability Assessment: In the field of customer service, BIG-Bench, as part of LLM benchmarks, can be used to develop chatbots that understand and respond to customer inquiries with accuracy and empathy. For example, a customer service chatbot could assist users with troubleshooting technical issues.
Thus, BIG-Bench is a useful benchmark to keep in mind when evaluating LLMs.
TruthfulQA
TruthfulQA is a benchmark designed to evaluate the truthfulness and accuracy of AI models in generating responses. It challenges models to provide factually correct and reliable answers, testing their ability to discern truth from misinformation.
This benchmark is crucial for assessing a model’s reliability and trustworthiness. The Key Features of the TruthfulQA Benchmark are as follows;
- Tasks that require generating factually correct responses.
- A comprehensive range of topics, ensuring thorough evaluation of truthfulness.
- Benchmarks for human performance, allowing direct comparison with model capabilities.
- Tests models on their ability to discern truth from misinformation.
- Evaluates a model’s ability to provide reliable and accurate information
Benefits
TruthfulQA provides a rigorous framework for evaluating the truthfulness and accuracy of AI models in generating responses. As one of the critical LLM benchmarks, it challenges models to provide factually correct and reliable answers, ensuring that AI systems can discern truth from misinformation.
This benchmark helps researchers identify areas where models may struggle, guiding the development of more effective algorithms that can provide accurate and reliable information. Another key benefit of TruthfulQA, within the realm of LLM benchmarks, is its role in enhancing trust and reliability in AI systems.
Applications
Key applications of TruthfulQA are as follows:
Conversational AI: In the healthcare industry, TruthfulQA can be applied to develop virtual assistants that provide patients with accurate and reliable health information. These assistants can answer common medical questions, provide guidance on symptoms and treatments, and direct patients to appropriate healthcare resources.
NLP Applications: For instance, it supports the development of AI systems that students with accurate and reliable information when researching topics, and providing evidence-based explanations.
TruthfulQA contributes to the development of AI systems that can assist in various professional fields. By ensuring that models can provide accurate and reliable information, TruthfulQA enables the creation of AI tools that support professionals in fields such as healthcare, finance, and law.

In conclusion, Popular benchmarks for LLM are vital tools in assessing and guiding the development of language models. LLM benchmarks provide essential insights into the strengths and weaknesses of AI systems, helping to ensure that advancements are both powerful and aligned with human values.