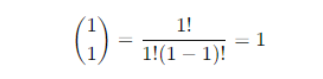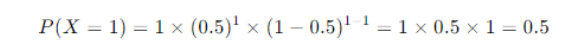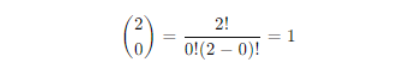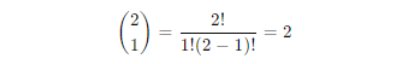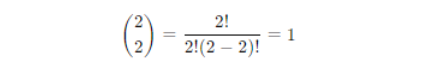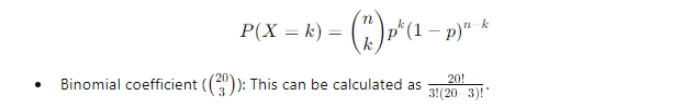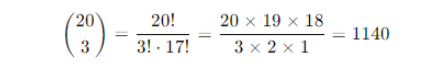For a hands-on learning experience to develop LLM applications, join our LLM Bootcamp today.
First 6 seats get an early bird discount of 30%! So hurry up!
In the realm of statistics and machine learning, understanding various probability distributions is paramount. One such fundamental distribution is the Binomial Distribution.
This distribution is not only a cornerstone in probability theory but also plays a crucial role in various machine learning algorithms and applications.
In this blog, we will delve into the concept of binomial distribution, its mathematical formulation, and its significance in the field of machine learning.
What is Binomial Distribution?
The binomial distribution is a discrete probability distribution that describes the number of successes in a fixed number of independent and identically distributed Bernoulli trials.
A Bernoulli trial is a random experiment where there are only two possible outcomes:
success (with probability ( p ))
failure (with probability ( 1 – p ))
Mathematical Formulation
The probability of observing exactly k successes in n trials is given by the binomial probability formula:
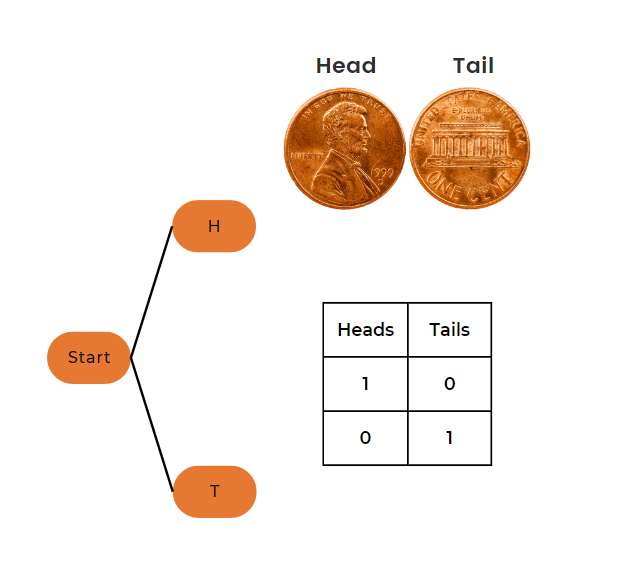
Example 1: Tossing One Coin
Let’s start with a simple example of tossing a single coin.
Parameters
Number of trials (n) = 1
Probability of heads (p) = 0.5
Number of heads (k) = 1
Calculation
Binomial coefficient
Probability
So, the probability of getting exactly one head in one toss of a coin is 0.5 or 50%.
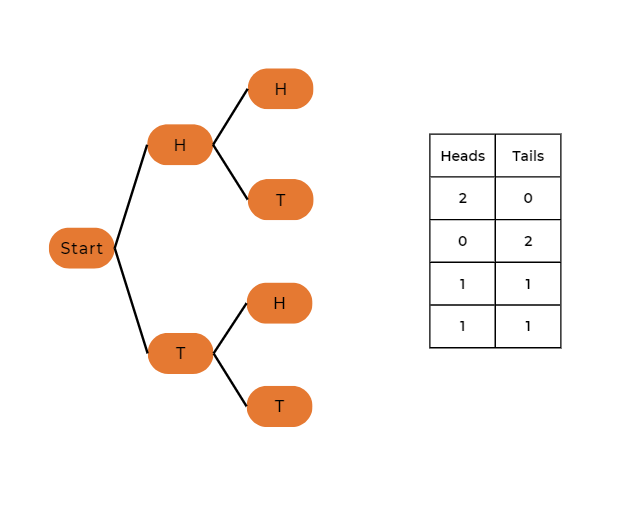
Example 2: Tossing Two Coins
Now, let’s consider the case of tossing two coins.
So, the probabilities for different numbers of heads in two-coin tosses are:
P(X = 0) = 0.25 – no heads
P(X = 1) = 0.5 – one head
P(X = 2) = 0.25 – two heads
Detailed Example: Predicting Machine Failure
Let’s consider a more practical example involving predictive maintenance in an industrial setting. Suppose we have a machine that is known to fail with a probability of 0.05 during a daily checkup. We want to determine the probability of the machine failing exactly 3 times in 20 days.
Step-by-Step Calculation
1. Identify Parameters
Number of trials (n) = 20 days
Probability of success (p) = 0.05 – failure is considered a success in this context
Number of successes (k) = 3 failures
2. Apply the Formula
3. Compute Binomial Coefficient
4. Calculate Probability
Plugging the values into the binomial formula
Substitute the values
P(X = 3) = 1140 × (0.05)3 × (0.95)17
Calculate (0.05)3
(0.05)3 = 0.000125
Calculate (0.95)17
(0.95)17 ≈ 0.411
5. Multiply all Components Together
P(X = 3) = 1140 × 0.000125 × 0.411 ≈ 0.0585
Therefore, the probability of the machine failing exactly 3 times in 20 days is approximately 0.0585 or 5.85%.
Role of Binomial Distribution in Machine Learning
The binomial distribution is integral to several aspects of machine learning, providing a foundation for understanding and modeling binary events, hypothesis testing, and beyond.
Let’s explore how it intersects with various machine-learning concepts and techniques.
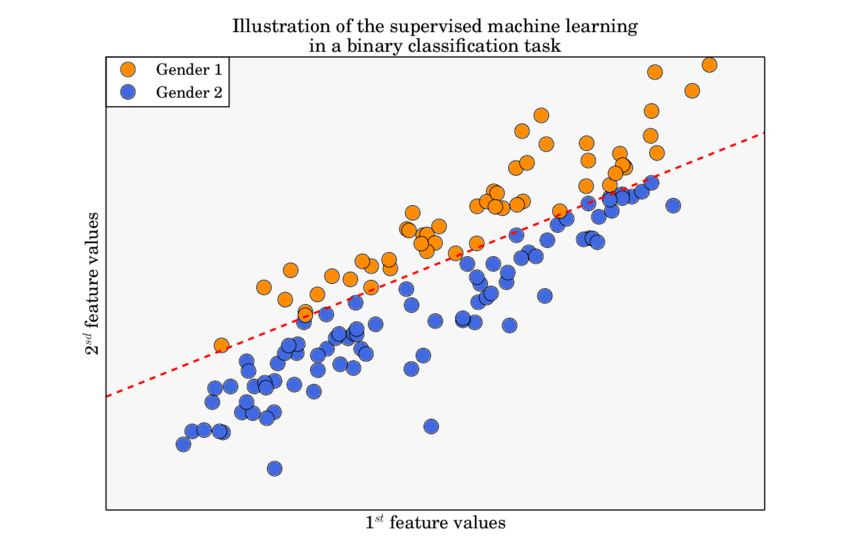
Binary Classification
In binary classification problems, where the outcomes are often categorized as success or failure, the binomial distribution forms the underlying probabilistic model. For instance, if we are predicting whether an email is spam or not, each email can be thought of as a Bernoulli trial.
Algorithms like Logistic Regression and Support Vector Machines (SVM) are particularly designed to handle these binary outcomes.
An example of binary classification – ResearchGate
Understanding the binomial distribution helps in correctly interpreting the results of these classifiers. The performance metrics such as accuracy, precision, recall, and F1-score ultimately derive from the binomial probability model.
This understanding ensures that we can make informed decisions about model improvements and performance evaluation.
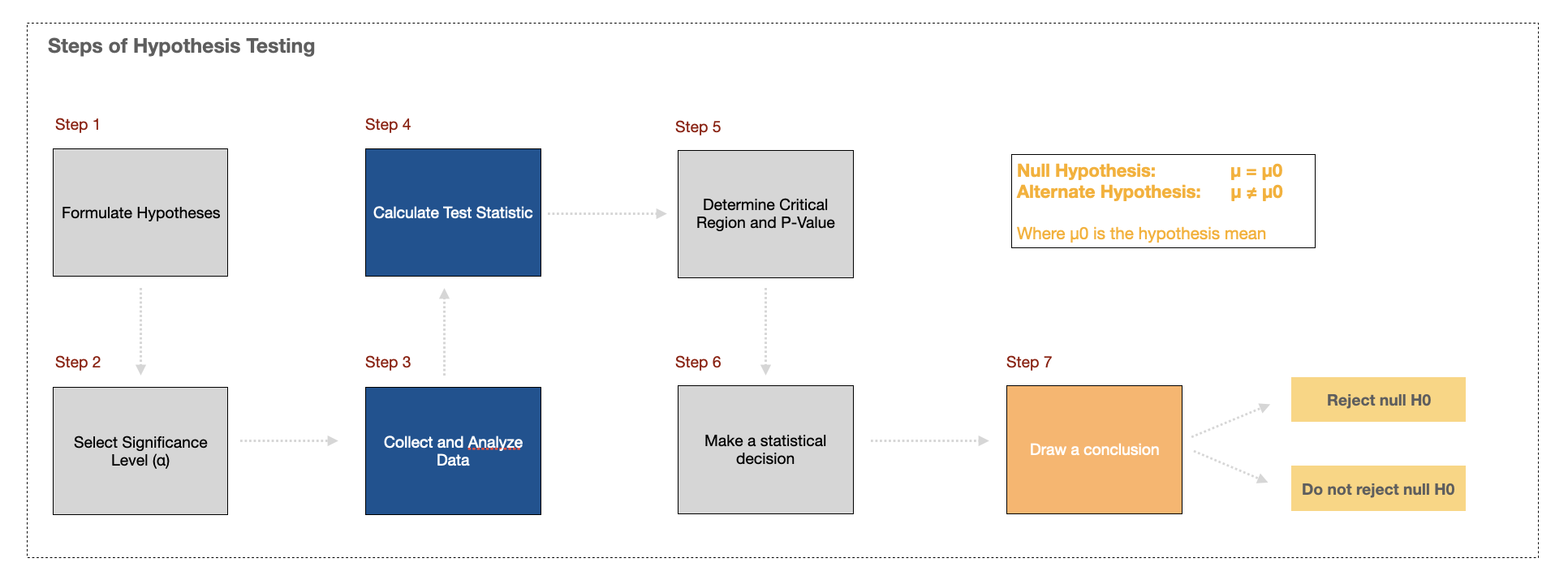
Hypothesis Testing
Statistical hypothesis testing, essential in validating machine learning models, often employs the binomial distribution to ascertain the significance of observed outcomes.
A typical process of hypothesis testing – Source: LinkedIn
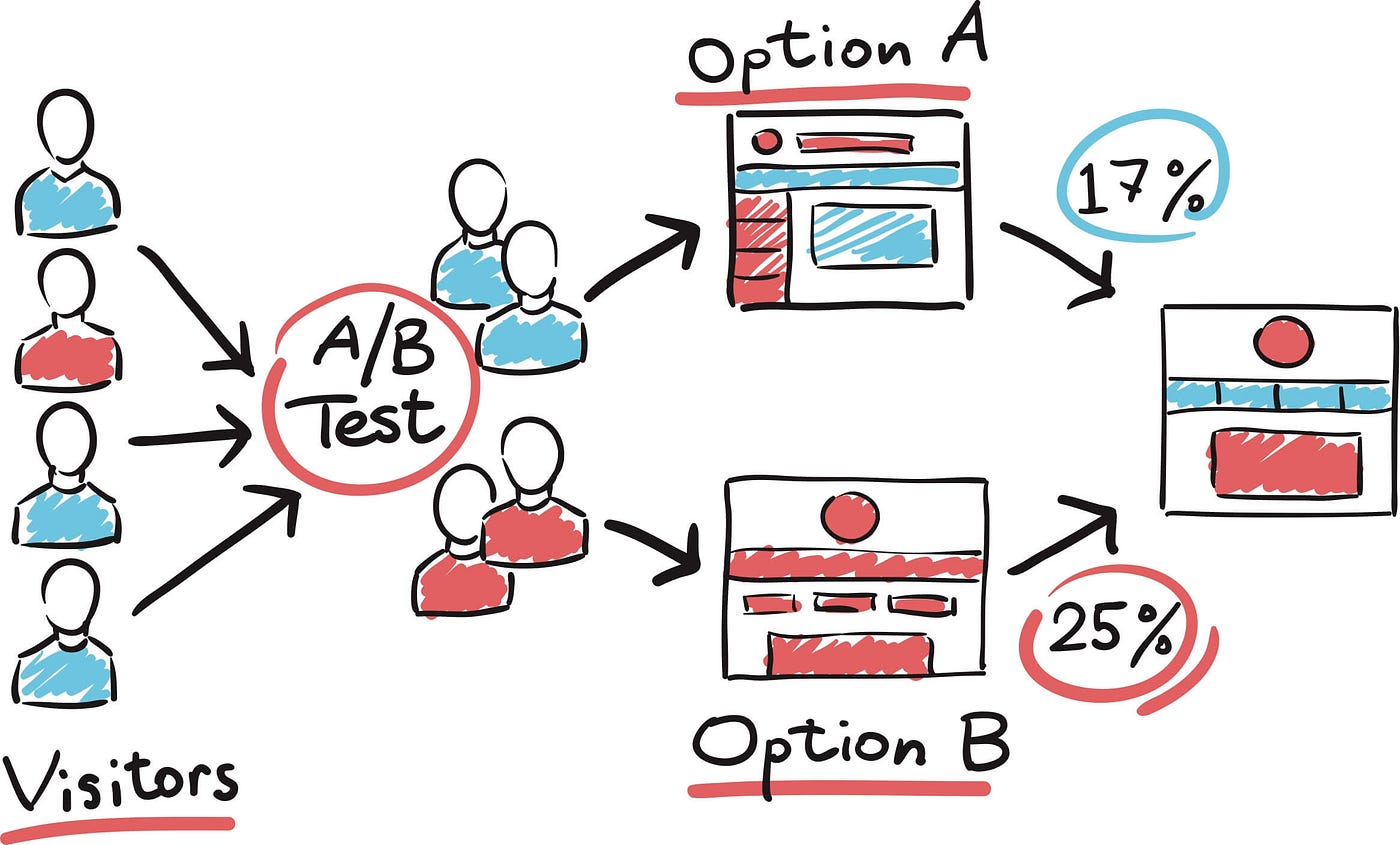
For instance, in A/B testing, which is widely used in machine learning for comparing model performance or feature impact, the binomial distribution helps in calculating p-values and confidence intervals.
Consider an example where we want to determine if a new feature in a recommendation system improves user click-through rates. By modeling the click events as a binomial distribution, we can perform a hypothesis test to evaluate if the observed improvement is statistically significant or just due to random chance.
Generative Models
Generative models such as Naive Bayes leverage binomial distributions to model the probability of observing certain classes given specific features. This is particularly useful when dealing with binary or categorical data.
An illustration of Naive Bayes classifier – Source: ResearchGate
In text classification tasks, for example, the presence or absence of certain words (features) in a document can be modeled using binomial distributions to predict the document’s category (class).
By understanding the binomial distribution, we can better grasp how these models work under the hood, leading to more effective feature engineering and model tuning.
Monte Carlo Simulations
Monte Carlo simulations, which are used in various machine learning applications for uncertainty estimation and decision-making, often rely on binomial distributions to model and simulate binary events over numerous trials.
These simulations can help in understanding the variability and uncertainty in model predictions, providing a robust framework for decision-making in the presence of randomness.
Practical Applications in Machine Learning
Quality Control in Manufacturing
In manufacturing, maintaining high-quality standards is crucial. Machine learning models are often deployed to predict the likelihood of defects in products.
Here, the binomial distribution is used to model the number of defective items in a batch. By understanding the distribution, we can set appropriate thresholds and confidence intervals to decide when to take corrective actions.
In medical diagnosis, machine learning models assist in predicting the presence or absence of a disease based on patient data. The binomial distribution provides a framework for understanding the probabilities of correct and incorrect diagnoses.
This is critical for evaluating the performance of diagnostic models and ensuring they meet the necessary accuracy and reliability standards.
Fraud Detection
Fraud detection systems in finance and e-commerce rely heavily on binary classification models to distinguish between legitimate and fraudulent transactions. The binomial distribution aids in modeling the occurrence of fraud and helps in setting detection thresholds that balance false positives and false negatives effectively.
Predicting customer churn is vital for businesses to retain their customer base. Machine learning models predict whether a customer will leave (churn) or stay (retain). The binomial distribution helps in understanding the probabilities of churn events and in setting up retention strategies based on these probabilities.
Why Use Binomial Distribution?
Binomial distribution is a fundamental concept that finds extensive application in machine learning. From binary classification to hypothesis testing and generative models, understanding and leveraging this distribution can significantly enhance the performance and interpretability of machine learning models.
By mastering the binomial distribution, you equip yourself with a powerful tool for tackling a wide range of problems in statistics and machine learning.
Feel free to dive deeper into this topic, experiment with different values, and explore the fascinating world of probability distributions in machine learning!
As the artificial intelligence landscape keeps rapidly changing, boosting algorithms have presented us with an advanced way of predictive modelling by allowing us to change how we approach complex data problems across numerous sectors.
These algorithms excel at creating powerful predictive models by combining multiple weak learners. These algorithms significantly enhance accuracy, reduce bias, and effectively handle complex data patterns.
Their ability to uncover feature importance makes them valuable tools for various ML tasks, including classification, regression, and ranking problems. As a result, boosting algorithms have become a staple in the machine learning toolkit.
In this article, we will explore the fundamentals of boosting algorithms and their applications in machine learning.
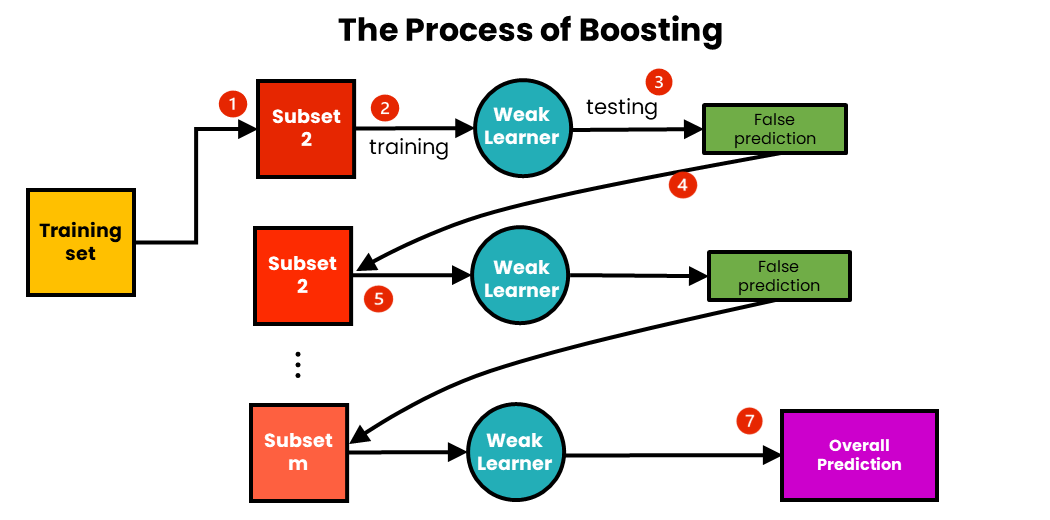
Understanding Boosting Algorithms Applications
Boosting algorithms applications are a subset of ensemble learning methods in machine learning that operate by combining multiple weak learners to construct robust predictive models. This approach can be likened to assembling a team of average performers who, through collaboration, achieve exceptional results.
A visual representation of boosting algorithms at work
Key Components of Boosting Algorithms
To accurately understand how boosting algorithms work, it’s important to examine their key elements:
Weak Learners: Simple models that perform marginally better than random assumptions.
Sequential Learning: Models are trained consecutively, each focusing on the mistakes of the previous weak learner.
Weighted Samples: Misclassified data points receive increased attention in subsequent rounds.
Ensemble Prediction: The final prediction integrates the outputs of all weak learners.
Boosting algorithms work with these components to enhance ML functionality and accuracy. While we understand the basics of boosting algorithm applications, let’s take a closer look into the boosting process.
Key Steps of the Boosting Process
Boosting algorithms applications typically follow this sequence:
Initialization: Assign equal weights to all data points.
Weak Learner Training: Train a weak learner on the weighted data.
Error Calculation: Calculate the error rate of the current weak learner.
Weight Adjustment: Increase the importance of misclassified points.
Iteration: Repeat steps 2-4 for an already predetermined number of cycles.
Ensemble Creation: Combine all weak learners into a robust final predictive model.
This iterative approach allows boosting algorithms to concentrate on the most challenging aspects of the data, resulting in highly accurate predictions.
Prominent Boosting Algorithms and Their Applications
Certain boosting algorithms have gained prominence in the machine-learning community:
AdaBoost (Adaptive Boosting)
AdaBoost, one of the pioneering boosting algorithms applications, is particularly effective for binary classification problems. It’s widely used in face detection and image recognition tasks.
Gradient Boosting
Gradient Boosting focuses on minimizing the loss function of the previous model. Its applications include predicting customer churn and sales forecasting in various industries.
XGBoost (Extreme Gradient Boosting)
XGBoost represents an advanced implementation of Gradient Boosting, offering enhanced speed and efficiency. It’s a popular choice in data science competitions and is used in fraud detection systems.
Boosting algorithms have transformed machine learning, offering robust solutions to complex challenges across diverse fields. Here are some key applications that demonstrate their versatility and impact:
Image Recognition and Computer Vision
Boosting algorithms significantly improve image recognition and computer vision by combining weak learners to achieve high accuracy. They are used in security surveillance for facial recognition and wildlife monitoring for species identification.
Natural Language Processing (NLP)
Boosting algorithms enhance NLP tasks such as sentiment analysis, language translation, and text summarization. They improve the accuracy of text sentiment classification, enhance the quality of machine translation, and generate concise summaries of large texts.
Finance
In finance, boosting algorithms improve stock price prediction, fraud detection, and credit risk assessment. They analyse large datasets to forecast market trends, identify unusual patterns to prevent fraud, and evaluate borrowers’ risk profiles to mitigate defaults.
Medical Diagnoses
In healthcare, boosting algorithms enhance predictive models for early disease detection, personalized treatment plans, and outcome predictions. They excel at identifying diseases from medical images and patient data, tailoring treatments to individual needs
Recommendation Systems
Boosting algorithms are used in e-commerce and streaming services to improve recommendation systems. By analysing user behaviour, they provide accurate, personalized content and handle large data volumes efficiently.
Key Advantages of Boosting
Some common benefits of boosting in ML include:
Implementation Ease: Boosting methods are user-friendly, particularly with tools like Python’s scikit-learn library, which includes popular algorithms like AdaBoost and XGBoost. These methods handle missing data with built-in routines and require minimal data preprocessing.
Bias Reduction: Boosting algorithms sequentially combine multiple weak learners, improving predictions iteratively. This process helps mitigate the high bias often seen in shallow decision trees and logistic regression models.
Increased Computational Efficiency: Boosting can enhance predictive performance during training, potentially reducing dimensionality and improving computational efficiency.
While boosting is a useful practice to enhance ML accuracy, it comes with its own set of hurdles. Some key challenges of the process are as follows:
Risk of Overfitting: The impact of boosting on overfitting is debated. When overfitting does occur, the model’s predictions may not generalize well to new datasets.
High Computational Demand: The sequential nature of boosting, where each estimator builds on its predecessors, can be computationally intensive. Although methods like XGBoost address some scalability concerns, boosting can still be slower than bagging due to its numerous parameters.
Sensitivity to Outliers: Boosting models are prone to being influenced by outliers. Each model attempts to correct the errors of the previous ones, making results susceptible to significant skewing in the presence of outlier data.
Challenges in Real-Time Applications: Boosting can be complex for real-time implementation. Its adaptability, with various model parameters affecting performance, adds to the difficulty of deploying boosting methods in real-time scenarios.
Value of Boosting Algorithms in ML
Boosting algorithm applications has significantly advanced the field of machine learning by enhancing model accuracy and tackling complex prediction tasks. Their ability to combine weak learners into powerful predictive models has made them invaluable across various industries.
As AI continues to evolve, these techniques will likely play an increasingly crucial role in developing sophisticated predictive models. By understanding and leveraging boosting algorithms applications, data scientists and machine learning practitioners can unlock new levels of performance in their predictive modelling endeavours.
Machine learning (ML) is a field where both art and science converge to create models that can predict outcomes based on data. One of the most effective strategies employed in ML to enhance model performance is ensemble methods.
Rather than relying on a single model, ensemble methods combine multiple models to produce better results. This approach can significantly boost accuracy, reduce overfitting, and improve generalization.
In this blog, we’ll explore various ensemble techniques, their working principles, and their applications in real-world scenarios.
What Are Ensemble Methods?
Ensemble methods are techniques that create multiple models and then combine them to produce a more accurate and robust final prediction. The idea is that by aggregating the predictions of several base models, the ensemble can capture the strengths of each individual model while mitigating their weaknesses.
Why Use Ensemble Methods?
Ensemble methods are used to improve the robustness and generalization of machine learning models by combining the predictions of multiple models. This can reduce overfitting and improve performance on unseen data.
There are three primary types of ensemble methods: Bagging, Boosting, and Stacking.
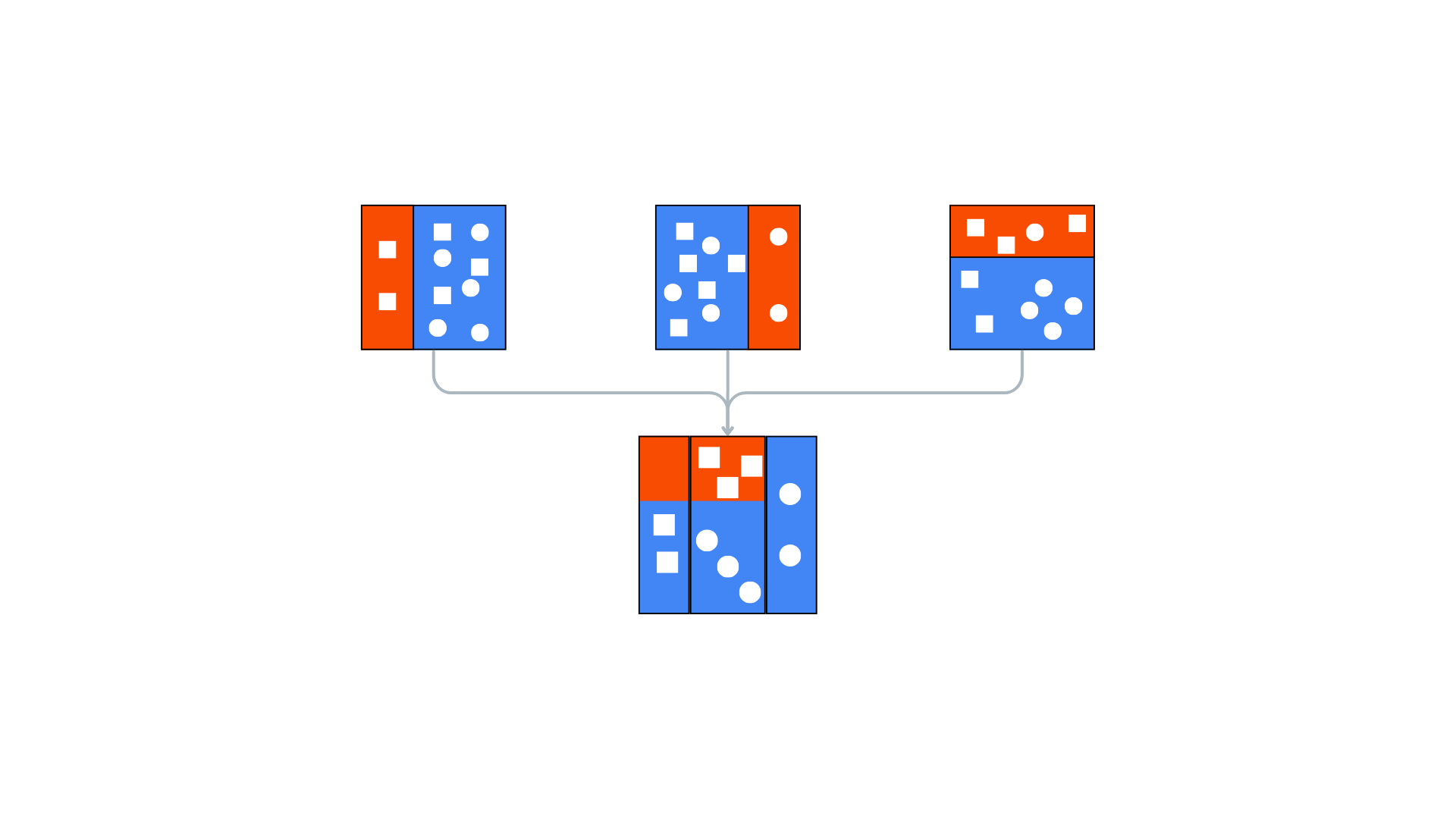
Bagging (Bootstrap Aggregating)
Bagging involves creating multiple subsets of the original dataset using bootstrap sampling (random sampling with replacement). Each subset is used to train a different model, typically of the same type, such as decision trees. The final prediction is made by averaging (for regression) or voting (for classification) the predictions of all models.
An outlook of bagging – Source: LinkedIn
How Bagging Works:
Bootstrap Sampling: Create multiple subsets from the original dataset by sampling with replacement.
Model Training: Train a separate model on each subset.
Aggregation: Combine the predictions of all models by averaging (regression) or majority voting (classification).
Random Forest
Random Forest is a popular bagging method where multiple decision trees are trained on different subsets of the data, and their predictions are averaged to get the final result.
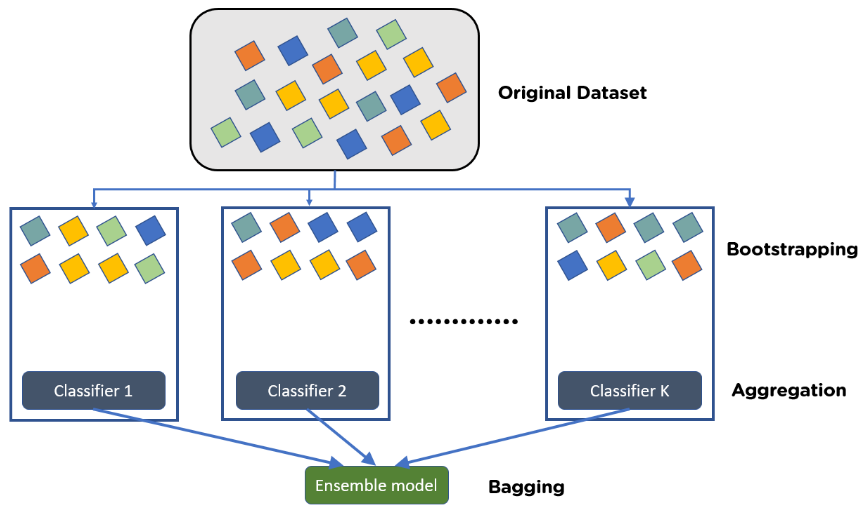
Boosting
Boosting is a sequential ensemble method where models are trained one after another, each new model focusing on the errors made by the previous models. The final prediction is a weighted sum of the individual model’s predictions.
A representation of boosting – Source: Medium
How Boosting Works:
Initialize Weights: Start with equal weights for all data points.
Sequential Training: Train a model and adjust weights to focus more on misclassified instances.
Aggregation: Combine the predictions of all models using a weighted sum.
AdaBoost (Adaptive Boosting)
It assigns weights to each instance, with higher weights given to misclassified instances. Subsequent models focus on these hard-to-predict instances, gradually improving the overall performance.
Gradient Boosting
It builds models sequentially, where each new model tries to minimize the residual errors of the combined ensemble of previous models using gradient descent.
XGBoost (Extreme Gradient Boosting)
An optimized version of Gradient Boosting, known for its speed and performance, is often used in competitions and real-world applications.
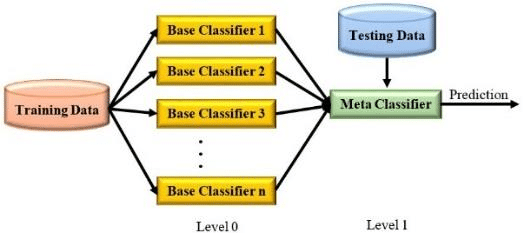
Stacking
Stacking, or stacked generalization, involves training multiple base models and then using their predictions as inputs to a higher-level meta-model. This meta-model is responsible for making the final prediction.
Visual concept of stacking – Source: ResearchGate
How Stacking Works:
Base Model Training: Train multiple base models on the training data.
Meta-Model Training: Use the predictions of the base models as features to train a meta-model.
Example:
A typical stacking ensemble might use logistic regression as the meta-model and decision trees, SVMs, and KNNs as base models.
Benefits of Ensemble Methods
Improved Accuracy
By combining multiple models, ensemble methods can significantly enhance prediction accuracy.
Robustness
Ensemble models are less sensitive to the peculiarities of a particular dataset, making them more robust and reliable.
Reduction of Overfitting
By averaging the predictions of multiple models, ensemble methods reduce the risk of overfitting, especially in high-variance models like decision trees.
Versatility
Ensemble methods can be applied to various types of data and problems, from classification to regression tasks.
Applications of Ensemble Methods
Ensemble methods have been successfully applied in various domains, including:
Healthcare: Improving the accuracy of disease diagnosis by combining different predictive models.
Finance: Enhancing stock price prediction by aggregating multiple financial models.
Computer Vision: Boosting the performance of image classification tasks with ensembles of CNNs.
Now let’s walk through the implementation of a Random Forest classifier in Python using the popular scikit-learn library. We’ll use the Iris dataset, a well-known dataset in the machine learning community, to demonstrate the steps involved in training and evaluating a Random Forest model.
Explanation of the Code
Import Necessary Libraries
We start by importing the necessary libraries. numpy is used for numerical operations, train_test_split for splitting the dataset, RandomForestClassifier for building the model, accuracy_score for evaluating the model, and load_iris to load the Iris dataset.
Load the Iris Dataset
The Iris dataset is loaded using load_iris(). The dataset contains four features (sepal length, sepal width, petal length, and petal width) and three classes (Iris setosa, Iris versicolor, and Iris virginica).
Split the Dataset
We split the dataset into training and testing sets using train_test_split(). Here, 30% of the data is used for testing, and the rest is used for training. The random_state parameter ensures the reproducibility of the results.
Initialize the RandomForestClassifier
We create an instance of the RandomForestClassifier with 100 decision trees (n_estimators=100). The random_state parameter ensures that the results are reproducible.
Train the Model
We train the Random Forest classifier on the training data using the fit() method.
Make Predictions
After training, we use the predict() method to make predictions on the testing data.
Evaluate the Model
Finally, we evaluate the model’s performance by calculating the accuracy using the accuracy_score() function. The accuracy score is printed to two decimal places.
Output Analysis
When you run this code, you should see an output similar to:
This output indicates that the Random Forest classifier achieved 100% accuracy on the testing set. This high accuracy is expected for the Iris dataset, as it is relatively small and simple, making it easy for many models to achieve perfect or near-perfect performance.
In practice, the accuracy may vary depending on the complexity and nature of the dataset, but Random Forests are generally robust and reliable classifiers.
By following this guided practice, you can see how straightforward it is to implement a Random Forest model in Python. This powerful ensemble method can be applied to various datasets and problems, offering significant improvements in predictive performance.
Summing it Up
To sum up, Ensemble methods are powerful tools in the machine learning toolkit, offering significant improvements in predictive performance and robustness. By understanding and applying techniques like bagging, boosting, and stacking, you can create models that are more accurate and reliable.
Ensemble methods are not just theoretical constructs; they have practical applications in various fields. By leveraging the strengths of multiple models, you can tackle complex problems with greater confidence and precision.
Data is a crucial element of modern-day businesses. With the growing use of machine learning (ML) models to handle, store, and manage data, the efficiency and impact of enterprises have also increased. It has led to advanced techniques for data management, where each tactic is based on the type of data and the way to handle it.
Categorical data is one such form of information that is handled by ML models using different methods. In this blog, we will explore the basics of categorical data. We will also explore the 7 main encoding methods used to process categorical data.
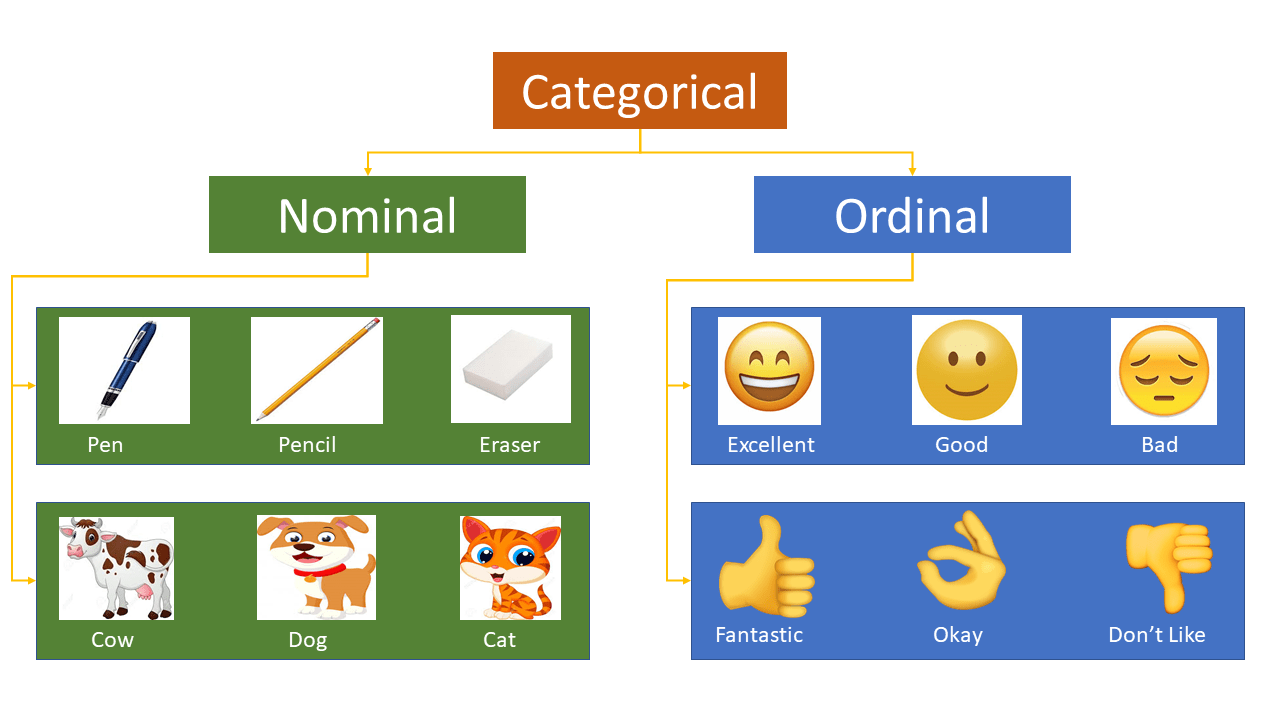
What is Categorical Data?
Categorical data, also known as nominal or ordinal data, consists of values that fall into distinct categories or groups. Unlike numerical data, which represents measurable quantities, categorical data represents qualitative or descriptive characteristics. These variables can be represented as strings or labels and have a finite number of possible values.
Examples of Categorical Data
Nominal Data: Categories that do not have an inherent order or ranking. For instance, the city where a person lives (e.g., Delhi, Mumbai, Ahmedabad, Bangalore).
Ordinal Data: Categories that have an inherent order or ranking. For example, the highest degree a person has (e.g., High School, Diploma, Bachelor’s, Master’s, Ph.D.).
Types of categorical data – Source: LinkedIn
Importance of Categorical Data in Machine Learning
Categorical data is crucial in machine learning for several reasons. ML models often require numerical input, so categorical data must be converted into a numerical format for effective processing and analysis. Here are some key points highlighting the importance of categorical data in machine learning:
1. Model Compatibility
Most machine learning algorithms work with numerical data, making it essential to transform categorical variables into numerical values. This conversion allows models to process the data and extract valuable information.
2. Pattern Recognition
Encoding categorical data helps models identify patterns within the data. For instance, specific categories might be strongly associated with particular outcomes, and recognizing these patterns can improve model accuracy and predictive power.
3. Bias Prevention
Proper encoding ensures that all features are equally weighted, preventing bias. For example, one-hot encoding and other methods help avoid unintended biases that might arise from the categorical nature of the data.
4. Feature Engineering
Encoding categorical data is a crucial part of feature engineering, which involves creating features that make ML models more effective. Effective feature engineering, including proper encoding, can significantly enhance model performance.
Advanced encoding techniques like target encoding and hashing are used to manage high cardinality features efficiently. These techniques help reduce dimensionality and computational complexity, making models more scalable and efficient.
6. Avoiding the Dummy Variable Trap
While techniques like one-hot encoding are popular, they can lead to issues like the dummy variable trap, where features become highly correlated. Understanding and addressing these issues through proper encoding methods is essential for robust model performance.
7. Improving Model Interpretability
Encoded categorical data can make models more interpretable. For example, target encoding provides a direct relationship between the categorical feature and the target variable, making it easier to understand how different categories influence the model’s predictions.
Let’s take a deeper look into 7 main encoding techniques for categorical data.
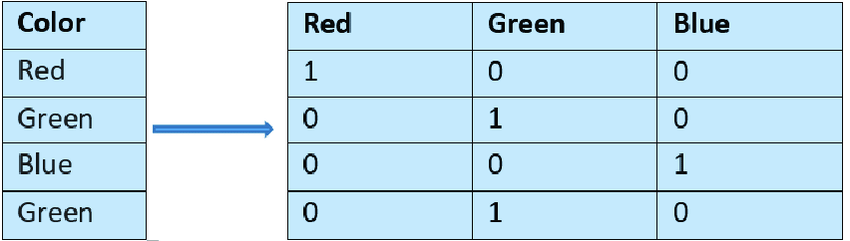
1. One-Hot Encoding
One-hot encoding, also known as dummy encoding, is a popular technique for converting categorical data into a numerical format. This technique is particularly suitable for nominal categorical features where the categories have no inherent order or ranking.
An example of one-hot encoding – Source: ResearchGate
How One-Hot Encoding Works?
Determine the categorical feature in your dataset that needs to be encoded.
For each unique category in the feature, create a new binary column.
Assign 1 to the column that corresponds to the category of the data point and 0 to all other new columns.
Advantages of One-Hot Encoding
Preserves Information: Maintains the distinctiveness of labels without implying any ordinality.
Compatibility: Provides a numerical representation of categorical data, making it suitable for many machine learning algorithms.
Use Cases
Nominal Data: When dealing with nominal data where categories have no meaningful order. For example, in a dataset containing the feature “Type of Animal” with categories like “Dog”, “Cat”, and “Bird”, one-hot encoding is ideal because there is no inherent ranking among the animals 2.
Machine Learning Models: Particularly beneficial for algorithms that cannot handle categorical data directly, such as linear regression, logistic regression, and neural networks.
Handling Missing Values: One-hot encoding handles missing values efficiently. If a category is absent, it results in all zeros in the one-hot encoded columns, which can be useful for certain ML models.
Challenges with One-Hot Encoding
Curse of Dimensionality: It can lead to a high number of new columns (dimensions) in your dataset, increasing computational complexity and storage requirements.
Multicollinearity: The newly created binary columns can be correlated, which can be problematic for some models that assume independence between features.
Data Sparsity: One-hot encoding can result in sparse matrices where most entries are zeros, which can be memory-inefficient and affect model performance.
Hence, one-hot encoding is a powerful and widely used technique for converting categorical data into a numerical format, especially for nominal data. Understanding when and how to use one-hot encoding is crucial for effective feature engineering in machine learning projects.
2. Dummy Encoding
Dummy encoding is a technique for converting categorical variables into a numerical format by transforming them into a set of binary variables.
It is similar to one-hot encoding but with a key distinction: dummy encoding uses (N-1) binary variables to represent (N) categories, which helps to avoid multicollinearity issues commonly known as the dummy variable trap.
An example of dummy encoding – Source: Medium
How Dummy Encoding Works?
Dummy encoding transforms each category in a categorical feature into a binary column, but it drops one category. The process can be explained as follows:
Determine the categorical feature in your dataset that needs to be encoded.
For each unique category in the feature (except one), create a new binary column.
Assign 1 to the column that corresponds to the category of the data point and 0 to all other new columns.
Advantages of Dummy Encoding
Avoids Multicollinearity: By dropping one category, dummy encoding prevents the dummy variable trap where one column can be perfectly predicted from the others.
Preserves Information: Maintains the distinctiveness of labels without implying any ordinality.
Use Cases
Regression Models: Suitable for regression models where multicollinearity can be a significant issue. By using (N-1) binary variables for (N) categories, dummy encoding helps to avoid this problem.
Nominal Data: When dealing with nominal data where categories have no meaningful order, dummy encoding is ideal. For example, in a dataset containing the feature “Department” with categories like “Finance”, “HR”, and “IT”, dummy encoding can be used to convert these categories into binary columns.
Challenges with Dummy Encoding
Curse of Dimensionality: Similar to one-hot encoding, dummy encoding can lead to a high number of new columns (dimensions) in your dataset, increasing computational complexity and storage requirements.
Data Sparsity: Dummy encoding can result in sparse matrices where most entries are zeros, which can be memory-inefficient and affect model performance.
However, dummy encoding is a useful technique for encoding categorical data. You must carefully choose this technique based on the details of your ML project.
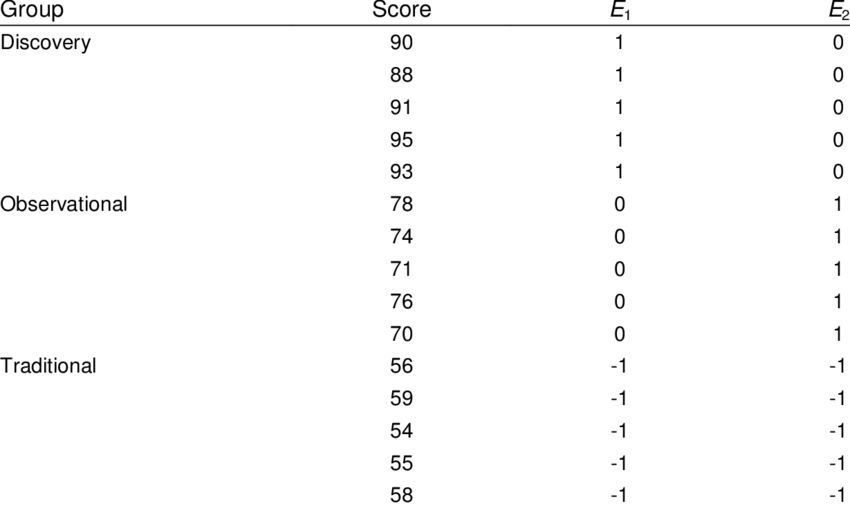
Effect encoding, also known as Deviation Encoding or Sum Encoding, is an advanced categorical data encoding technique. It is similar to dummy encoding but with a key difference: instead of using binary values (0 and 1), effect encoding uses three values: 1, 0, and -1.
This encoding is particularly useful when dealing with categorical variables in linear models because it helps to handle the multicollinearity issue more effectively.
An example of effect encoding – Source: ResearchGate
How Effect Encoding Works?
In effect encoding, the categories of a feature are represented using 1, 0, and -1. The idea is to represent the absence of the first category (baseline category) by -1 in all corresponding binary columns.
Determine the categorical feature in your dataset that needs to be encoded.
For each unique category in the feature (except one), create a new binary column.
Assign 1 to the column that corresponds to the category of the data point, 0 to all other new columns, and -1 to the row that would otherwise be all 0s in dummy encoding.
Advantages of Effect Encoding
Avoids Multicollinearity: By using -1 in place of the baseline category, effect encoding helps to handle multicollinearity better than dummy encoding.
Interpretable Coefficients: In linear models, the coefficients of effect-encoded variables are interpreted as deviations from the overall mean, which can sometimes make the model easier to interpret.
Use Cases
Linear Models: When using linear regression or other linear models, effect encoding helps to handle multicollinearity issues effectively and makes the coefficients more interpretable.
ANOVA (Analysis of Variance): Effect encoding is often used in ANOVA models for comparing group means.
Thus, effect encoding is an advanced technique for encoding categorical data, particularly beneficial for linear models due to its ability to handle multicollinearity and make coefficients interpretable.
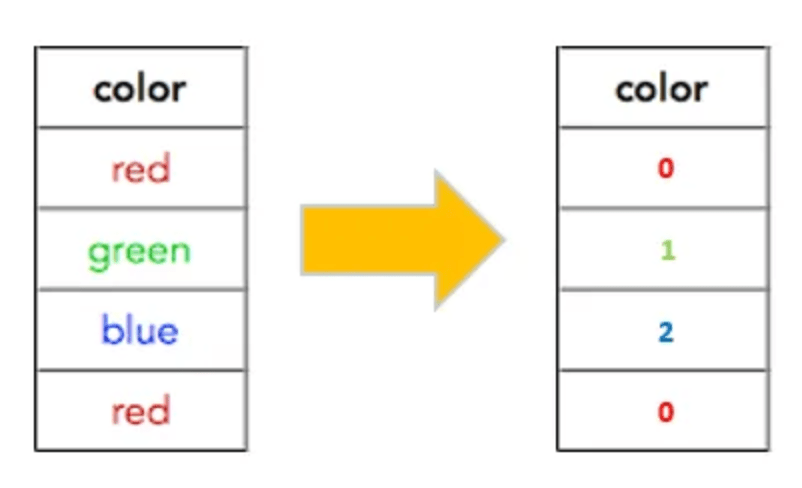
4. Label Encoding
Label encoding is a technique used to convert categorical data into numerical data by assigning a unique integer to each category within a feature. This method is particularly useful for ordinal categorical features where the categories have a meaningful order or ranking.
By converting categories to numbers, label encoding makes categorical data compatible with machine learning algorithms that require numerical input.
An example of label encoding – Source: Medium
How Label Encoding Works?
Label encoding assigns a unique integer to each category in a feature. The integers are typically assigned in alphabetical order or based on their appearance in the data. For ordinal features, the integers represent the order of the categories.
Determine the categorical feature in your dataset that needs to be encoded.
Assign a unique integer to each category in the feature.
Replace the original categories in the feature with their corresponding integer values.
Advantages of Label Encoding
Simple and Efficient: It is straightforward and computationally efficient.
Maintains Ordinality: It preserves the order of categories, which is essential for ordinal features.
Use Cases
Ordinal Data: When dealing with ordinal features where the categories have a meaningful order. For example, education levels such as “High School”, “Bachelor’s Degree”, “Master’s Degree”, and “PhD” can be encoded as 0, 1, 2, and 3, respectively.
Tree-Based Algorithms: Algorithms like decision trees and random forests can handle label-encoded data well because they can naturally work with the integer representation of categories.
Challenges with Label Encoding
Unintended Ordinality: When used with nominal data (categories without a meaningful order), label encoding can introduce unintended ordinality, misleading the model to assume some form of ranking among the categories.
Model Bias: Some machine learning algorithms might misinterpret the integer values as having a mathematical relationship, potentially leading to biased results.
Label encoding is a simple yet powerful technique for converting categorical data into numerical format, especially useful for ordinal features. However, it should be used with caution for nominal data to avoid introducing unintended relationships.
By following these guidelines and examples, you can effectively implement label encoding in your ML workflows to handle categorical data efficiently.
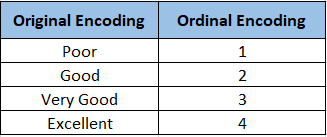
5. Ordinal Encoding
Ordinal encoding is a technique used to convert categorical data into numerical data by assigning a unique integer to each category within a feature, based on a meaningful order or ranking. This method is particularly useful for ordinal categorical features where the categories have a natural order.
An example of ordinal encoding – Source: Medium
How Ordinal Encoding Works
Ordinal encoding involves mapping each category to a unique integer value that reflects the order of the categories. This method ensures that the encoded values preserve the inherent order among the categories. It can be summed into the following steps
Determine the ordinal feature in your dataset that needs to be encoded.
Establish a meaningful order for the categories.
Assign a unique integer to each category based on their order.
Replace the original categories in the feature with their corresponding integer values.
Advantages of Ordinal Encoding
Preserves Order: It captures and preserves the ordinal relationships between categories, which can be valuable for certain types of analyses.
Reduces Dimensionality: It reduces the dimensionality of the dataset compared to one-hot encoding, making it more memory-efficient.
Compatible with Many Algorithms: It provides a numerical representation of the data, making it suitable for many machine learning algorithms.
Use Cases
Ordinal Data: When dealing with categorical features that exhibit a clear and meaningful order or ranking. For example, education levels, satisfaction ratings, or any other feature with an inherent order.
Machine Learning Models: Algorithms like linear regression, decision trees, and support vector machines can benefit from the ordered numerical representation of ordinal features.
Challenges with Ordinal Encoding
Assumption of Linear Relationships: Some machine learning algorithms might assume a linear relationship between the encoded integers, which might not always be appropriate for all ordinal features.
Not Suitable for Nominal Data: It should not be applied to nominal categorical features, where the categories do not have a meaningful order.
Ordinal encoding is especially useful for machine learning algorithms that need numerical input and can handle the ordered nature of the data.
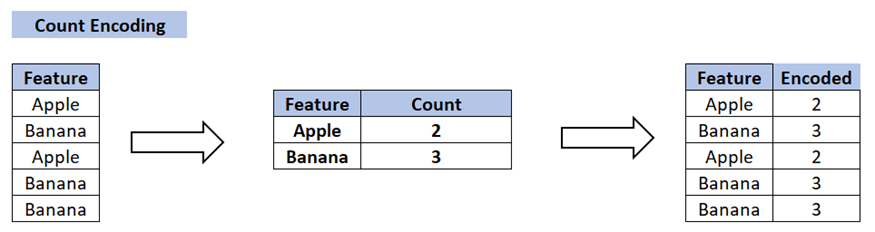
6. Count Encoding
Count encoding, also known as frequency encoding, is a technique used to convert categorical features into numerical values based on the frequency of each category in the dataset.
This method assigns each category a numerical value representing how often it appears, thereby providing a straightforward numerical representation of the categories.
An example of count encoding – Source: Medium
How Count Encoding Works
The process of count encoding involves mapping each category to its frequency or count within the dataset. Categories that appear more frequently receive higher values, while less common categories receive lower values. This can be particularly useful in scenarios where the frequency of categories carries significant information.
Determine the categorical feature in your dataset that needs to be encoded.
Calculate the frequency of each category within the feature.
Assign the calculated frequencies as numerical values to each corresponding category.
Replace the original categories in the feature with their corresponding frequency values.
Advantages of Count Encoding
Simple and Interpretable: It provides a straightforward and interpretable way to encode categorical data, preserving the count information.
Relevant for Frequency-Based Problems: Particularly useful when the frequency of categories is a relevant feature for the problem you’re solving.
Reduces Dimensionality: It reduces the dimensionality compared to one-hot encoding, which can be beneficial in high-cardinality scenarios.
Use Cases
Frequency-Relevant Features: When analyzing categorical features where the frequency of each category is relevant information for your model. For instance, in customer segmentation, the frequency of customer purchases might be crucial.
High-Cardinality Features: When dealing with high-cardinality categorical features, where one-hot encoding would result in a large number of columns, count encoding provides a more compact representation.
Challenges with Count Encoding
Loss of Category Information: It can lose some information about the distinctiveness of categories since categories with the same frequency will have the same encoded value.
Not Suitable for Ordinal Data: It should not be applied to ordinal categorical features where the order of categories is important.
Count encoding is a valuable technique for scenarios where category frequencies carry significant information and when dealing with high-cardinality features.
7. Binary Encoding
Binary encoding is a versatile technique for encoding categorical features, especially when dealing with high-cardinality data. It combines the benefits of one-hot and label encoding while reducing dimensionality.
An example of binary encoding – Source: ResearchGate
How Binary Encoding Works
Binary encoding involves converting each category into binary code and representing it as a sequence of binary digits (0s and 1s). Each binary digit is then placed in a separate column, effectively creating a set of binary columns for each category. The encoding process follows these steps:
Assign a unique integer to each category, similar to label encoding.
Convert the integer to binary code.
Create a set of binary columns to represent the binary code.
Advantages of Binary Encoding
Dimensionality Reduction: It reduces the dimensionality compared to one-hot encoding, especially for features with many unique categories.
Memory Efficient: It is memory-efficient and overcomes the curse of dimensionality.
Easy to Implement and Interpret: It is straightforward to implement and interpret.
Use Cases
High-Cardinality Features: When dealing with high-cardinality categorical features (features with a large number of unique categories), binary encoding helps reduce the dimensionality of the dataset.
Machine Learning Models: It is suitable for many machine learning algorithms that can handle binary input features effectively.
Challenges with Binary Encoding
Complexity: Although binary encoding reduces dimensionality, it might still introduce complexity for features with extremely high cardinality.
Handling Missing Values: Special care is needed to handle missing values during the encoding process.
Hence, binary encoding combines the advantages of one-hot encoding and label encoding, making it a suitable choice for many ML tasks.
Mastering Categorical Data Encoding for Enhanced Machine Learning
In summary, the effective handling of categorical data is a cornerstone of modern machine learning. With the growth of machine learning models, businesses can now manage data more efficiently, leading to improved enterprise performance.
This blog has delved into the basics of categorical data and outlined seven critical encoding methods. Each method has its unique advantages, challenges, and specific use cases, making it essential to choose the right technique based on the nature of the data and the requirements of the model.
Proper encoding not only ensures compatibility with various models but also enhances pattern recognition, prevents bias, and improves feature engineering. By mastering these encoding techniques, data scientists can significantly improve model performance and make more informed predictions, ultimately driving better business outcomes.
You can also join our Discord community to stay posted and participate in discussions around machine learning, AI, LLMs, and much more!
By understanding machine learning algorithms, you can appreciate the power of this technology and how it’s changing the world around you! It’s like having a super-powered tool to sort through information and make better sense of the world.
So, just like a super sorting system for your toys, machine learning algorithms can help you organize and understand massive amounts of data in many ways:
Recommend movies you might like by learning what kind of movies you watch already.
Spot suspicious activity on your credit card by learning what your normal spending patterns look like.
Help doctors diagnose diseases by analyzing medical scans and patient data.
Predict traffic jams by learning patterns in historical traffic data.
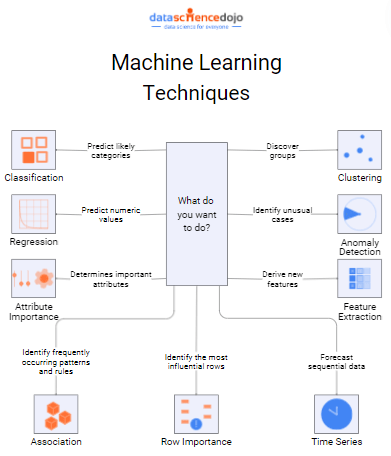
Major machine learning techniques
1. Regression
Regression, much like predicting how much popcorn you need for movie night, is a cornerstone of machine learning. It delves into the realm of continuous predictions, where the target variable you’re trying to estimate takes on numerical values. Let’s unravel the technicalities behind this technique:
The Core Function:
Regression algorithms learn from labeled data, similar to classification. However, in this case, the labels are continuous values. For example, you might have data on house size (features) and their corresponding sale prices (target variable).
The algorithm’s goal is to uncover the underlying relationship between the features and the target variable. This relationship is often depicted by a mathematical function (like a line or curve).
Once trained, the model can predict the target variable for new, unseen data points based on their features.
Types of Regression Problems:
Linear Regression: This is the simplest and most common form, where the relationship between features and the target variable is modeled by a straight line.
Polynomial Regression: When the linear relationship doesn’t suffice, polynomials (curved lines) are used to capture more complex relationships.
Non-linear Regression: There’s a vast array of non-linear models (e.g., decision trees, support vector regression) that can model even more intricate relationships between features and the target variable.
Technical Considerations:
Feature Engineering: As with classification, selecting and potentially transforming features significantly impacts model performance.
Evaluating Model Fit: Metrics like mean squared error (MSE) or R-squared are used to assess how well the model’s predictions align with the actual target values.
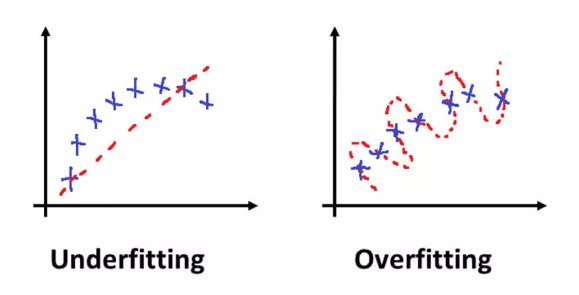
Overfitting and Underfitting: Similar to classification, achieving a balance between model complexity and generalizability is crucial. Techniques like regularization can help prevent over fitting.
Residual Analysis: Examining the residuals (differences between predicted and actual values) can reveal underlying patterns and potential issues with the model.
Real-world Applications:
Regression finds applications in various domains:
Weather Forecasting: Predicting future temperatures based on historical data and current conditions.
Stock Market Analysis: Forecasting future stock prices based on historical trends and market indicators.
Sales Prediction: Estimating future sales figures based on past sales data and marketing campaigns.
Customer Lifetime Value (CLV) Prediction: Forecasting the total revenue a customer will generate over their relationship with a company.
Technical Nuances:
While linear regression offers a good starting point, understanding advanced regression techniques allows you to model more complex relationships and create more accurate predictions in diverse scenarios. Additionally, addressing issues like multi-collinearity (correlated features) and hetero-scedasticity (unequal variance of errors) becomes crucial as regression models become more sophisticated.
By comprehending these technical aspects, you gain a deeper understanding of how regression algorithms unveil the hidden patterns within your data, enabling you to make informed predictions and solve real-world problems.
Classification algorithms learn from labeled data. This means each data point has a pre-defined category or class label attached to it. For example, in spam filtering, emails might be labeled as “spam” or “not-spam.”
It analyzes the features or attributes of the data (like word content in emails or image pixels in pictures).
Based on this analysis, it builds a model that can predict the class label for new, unseen data points.
Types of Classification Problems:
Binary Classification: This is the simplest case, where there are only two possible categories (spam/not-spam, cat/dog).
Multi-Class Classification: Here, there are more than two categories (e.g., classifying handwritten digits into 0, 1, 2, …, 9).
Multi-Label Classification: A data point can belong to multiple classes simultaneously (e.g., an image might contain both a cat and a dog).
Common Classification Algorithms:
Logistic Regression: A popular choice for binary classification, it uses a mathematical function to model the probability of a data point belonging to a particular class.
Support Vector Machines (SVM): This algorithm finds a hyperplane that best separates data points of different classes in high-dimensional space.
Decision Trees: These work by asking a series of yes/no questions based on data features to classify data points.
K-Nearest Neighbors (KNN): This method classifies a data point based on the majority class of its K nearest neighbors in the training data.
Technical aspects to consider:
Feature Engineering: Choosing the right features and potentially transforming them (e.g., converting text to numerical features) is crucial for model performance.
Overfitting and Underfitting: The model should neither be too specific to the training data (overfitting) nor too general (underfitting). Techniques like regularization can help balance this.
Evaluation Metrics: Performance is measured using metrics like accuracy, precision, recall, and F1-score, depending on the specific classification task.
Real-world Applications:
Classification is used extensively across various domains:
Fraud Detection: Identifying suspicious transactions on credit cards.
Medical Diagnosis: Classifying medical images or predicting disease risk factors.
Sentiment Analysis: Classifying text data as positive, negative, or neutral sentiment.
By understanding these technicalities, you gain a deeper appreciation for the power and complexities of classification algorithms in machine learning.
3. Attribute Importance
Just like understanding which features matter most when sorting your laundry, delves into the significance of individual features within your machine-learning model. Here’s a breakdown of the technicalities:
The Core Idea:
Machine learning models utilize various features (attributes) from your data to make predictions. Not all features, however, contribute equally. Attribute importance helps you quantify the relative influence of each feature on the model’s predictions.
Technical Approaches:
There are several techniques to assess attribute importance, each with its own strengths and weaknesses:
Feature Permutation: This method randomly shuffles the values of a single feature and observes the resulting change in model performance. A significant drop suggests that feature is important.
Feature Impurity Measures: This approach, commonly used in decision trees, calculates the average decrease in impurity (e.g., Gini index) when a split is made on a particular feature. Higher impurity reduction indicates greater importance.
Model-Specific Techniques: Some models have built-in methods for calculating attribute importance. For example, Random Forests track the improvement in prediction accuracy when features are included in splits.
Benefits of Understanding Attribute Importance:
Model Interpretability: By knowing which features are most important, you gain insights into how the model arrives at its predictions. This is crucial for understanding model behavior and building trust.
Feature Selection: Identifying irrelevant or redundant features allows you to streamline your data and potentially improve model performance by focusing on the most impactful features.
Domain Knowledge Integration: Attribute importance can highlight features that align with your domain expertise, validating the model’s reasoning or prompting further investigation.
Technical Considerations:
Choice of Technique: The most suitable method depends on the model you’re using and the type of data you have. Experimenting with different approaches may be necessary.
Normalization: The importance scores might need normalization across features for better comparison, especially when features have different scales.
Limitations: Importance scores can be influenced by interactions between features. A seemingly unimportant feature might play a crucial role in conjunction with others.
Real-world Applications:
Attribute importance finds applications in various domains:
Fraud Detection: Identifying the financial factors (e.g., transaction amount, location) that most influence fraud prediction allows for targeted risk mitigation strategies.
Medical Diagnosis: Understanding which symptoms are most crucial for disease prediction helps healthcare professionals prioritize tests and interventions.
Customer Churn Prediction: Knowing which customer attributes (e.g., purchase history, demographics) are most indicative of churn allows businesses to develop targeted retention strategies.
By understanding attribute importance, you gain valuable insights into the inner workings of your machine learning models. This empowers you to make informed decisions about feature selection, improve model interpretability, and ultimately, achieve better performance.
4. Association Learning
Akin to noticing your friend always buying peanut butter with jelly, is a technique in machine learning that uncovers hidden relationships between different features (attributes) within your data. Let’s delve into the technical aspects:
The Core Concept:
Association learning algorithms analyze large datasets to discover frequent patterns of co-occurrence between features. These patterns are often expressed as association rules, which take the form “if A, then B with confidence X%”. Here’s an example:
Rule: If a customer buys diapers (A), then they are also likely to buy wipes (B) with 80% confidence (X%).
Technical Approaches:
Apriori Algorithm: This is a foundational algorithm that employs a breadth-first search to identify frequent itemsets (groups of features that appear together frequently). These itemsets are then used to generate association rules with a minimum support (frequency) and confidence (correlation) threshold.
FP-Growth Algorithm: This is an optimization over Apriori that uses a frequent pattern tree structure to efficiently mine frequent itemsets, reducing the number of candidate rules generated.
Benefits of Association Learning:
Market Basket Analysis: Understanding buying patterns helps retailers recommend complementary products and optimize product placement in stores.
Customer Segmentation: Identifying groups of customers with similar purchasing behavior enables targeted marketing campaigns.
Fraud Detection: Discovering unusual co-occurrences in transactions can help identify potential fraudulent activities.
Technical Considerations:
Minimum Support and Confidence: Setting appropriate thresholds for both is crucial. A high support ensures the rule is not based on rare occurrences, while a high confidence guarantees a strong correlation between features.
Data Sparsity: Association learning often works best with large, dense datasets. Sparse data with many infrequent features can lead to unreliable results.
Lift: This metric goes beyond confidence and considers the baseline probability of feature B appearing independently. A lift value greater than 1 indicates a stronger association than random chance.
Real-world Applications:
Association learning finds applications in various domains:
Recommendation Systems: Online platforms leverage association rules to recommend products or content based on a user’s past purchases or browsing behavior.
Clickstream Analysis: Understanding how users navigate websites through association rules helps optimize website design and user experience.
Network Intrusion Detection: Identifying unusual patterns in network traffic can help detect potential security threats.
By understanding the technicalities of association learning, you can unlock valuable insights hidden within your data. These insights enable you to make informed decisions in areas like marketing, fraud prevention, and recommendation systems.
Row Importance
Unlike attribute importance which focuses on features, row importance delves into the significance of individual data points (rows) within your machine learning model. Imagine a student’s grades – some students might significantly influence understanding class performance compared to others. Row importance helps identify these influential data points.
The Core Idea:
Machine learning models are built on datasets containing numerous data points (rows). However, not all data points contribute equally to the model’s learning process. Row importance quantifies the influence of each row on the model’s predictions.
Technical Approaches:
Several techniques can be used to assess row importance, each with its own advantages and limitations:
Leave-One-Out (LOO) Cross-Validation: This method retrains the model leaving out each data point one at a time and observes the change in model performance (e.g., accuracy). A significant performance drop indicates that row’s importance. (Note: This can be computationally expensive for large datasets.)
Local Surrogate Models: This approach builds simpler models (surrogates) around each data point to understand its local influence on the overall model’s predictions.
SHAP (SHapley Additive exPlanations): This method distributes the prediction of a model among all data points, highlighting the contribution of each row.
Benefits of Understanding Row Importance:
Identifying Outliers: Row importance can help pinpoint outliers or anomalous data points that might significantly skew the model’s predictions.
Data Cleaning and Preprocessing: Focusing on cleaning or potentially removing highly influential data points with low quality can improve model robustness.
Understanding Model Behavior: By identifying the most influential rows, you can gain insights into which data points the model relies on heavily for making predictions.
Technical Considerations:
Choice of Technique: The most suitable method depends on the complexity of your model and the size of your dataset. LOO is computationally expensive, while SHAP can be complex to implement.
Interpretation: The importance scores themselves might not be readily interpretable. They often require additional analysis or domain knowledge to understand why a particular row is influential.
Limitations: Importance scores can be influenced by the specific model and training data. They might not always generalize perfectly to unseen data.
Real-world Applications:
Row importance finds applications in various domains:
Fraud Detection: Identifying the transactions with the highest likelihood of being fraudulent helps prioritize investigations for financial institutions.
Medical Diagnosis: Understanding which patient data points (e.g., symptoms, test results) most influence a disease prediction aids doctors in diagnosis and treatment planning.
Customer Segmentation: Identifying the most influential customers (high spenders, brand advocates) allows businesses to tailor marketing campaigns and loyalty programs.
By understanding row importance, you gain valuable insights into how individual data points influence your machine-learning models. This empowers you to make informed decisions about data cleaning, outlier handling, and ultimately, achieve better model performance and interpretability.
Time series data, like your daily steps or stock prices, unfolds over time. Machine learning unlocks the secrets within this data by analyzing its temporal patterns. Let’s delve into the technicalities of time series analysis:
The Core Idea:
Time series data consists of data points collected at uniform time intervals. These data points represent the value of a variable at a specific point in time.
Time series analysis focuses on modeling and understanding the trends, seasonality, and cyclical patterns within this data.
Machine learning algorithms can then be used to forecast future values based on the historical data and the underlying patterns.
Technical Approaches:
There are various models and techniques used for time series analysis:
Moving Average Models: These models take the average of past data points to predict future values. They are simple but effective for capturing short-term trends.
Exponential Smoothing: This builds on moving averages by giving more weight to recent data points, adapting to changing trends.
ARIMA (Autoregressive Integrated Moving Average): This is a powerful statistical model that captures autoregression (past values influencing future values) and seasonality.
Recurrent Neural Networks (RNNs): These powerful deep learning models can learn complex patterns and long-term dependencies within time series data, making them suitable for more intricate forecasting tasks.
Technical Considerations:
Stationarity: Many time series models assume the data is stationary, meaning the statistical properties (mean, variance) don’t change over time. Differencing techniques might be necessary to achieve stationarity.
Feature Engineering: Creating new features based on existing time series data (e.g., lags, rolling averages) can improve model performance.
Evaluation Metrics: Metrics like Mean Squared Error (MSE) or Mean Absolute Error (MAE) are used to assess the accuracy of forecasts generated by the model.
Real-world Applications:
Time series analysis finds applications in various domains:
Supply Chain Management: Forecasting demand for products to optimize inventory management.
Sales Forecasting: Predicting future sales figures to plan production and marketing strategies.
Weather Forecasting: Predicting future temperatures, precipitation, and other weather patterns.
By understanding the technicalities of time series analysis, you can unlock the power of time-based data for forecasting and making informed decisions in various domains. Machine learning offers sophisticated tools for extracting valuable insights from the ever-flowing stream of time series data.
6. Feature Extraction
Feature extraction, akin to summarizing a movie by its genre, actors, and director, plays a crucial role in machine learning. It involves transforming raw data into a more meaningful and informative representation for machine learning models to work with. Let’s delve into the technical aspects:
The Core Idea:
Raw data can be complex and high-dimensional. Machine learning models often struggle to directly process and learn from this raw data.
Feature extraction aims to extract a smaller set of features from the raw data that are more relevant to the machine learning task at hand. These features capture the essential information needed for the model to make predictions.
Technical Approaches:
There are various techniques for feature extraction, depending on the type of data you’re dealing with:
Feature Selection: This involves selecting a subset of existing features that are most informative and relevant to the prediction task. Techniques like correlation analysis and filter methods can be used for this purpose.
Dimensionality Reduction: Techniques like Principal Component Analysis (PCA) project high-dimensional data onto a lower-dimensional space while preserving most of the information. This reduces the complexity of the data and improves model efficiency.
Feature Engineering: This involves creating entirely new features from the existing data. This can be done through domain knowledge, mathematical transformations, or feature combinations. For example, creating new features like “day of the week” from a date column.
Benefits of Feature Extraction:
Improved Model Performance: By focusing on relevant features, the model can learn more effectively and make better predictions.
Reduced Training Time: Lower dimensional data allows for faster training of machine learning models.
Reduced Overfitting: Feature extraction can help prevent overfitting by reducing the number of features the model needs to learn from.
Technical Considerations:
Choosing the Right Technique: The best approach depends on the type of data and the machine learning task. Experimentation with different techniques might be necessary.
Domain Knowledge: Feature engineering often relies on your domain expertise to create meaningful features from the raw data.
Evaluation and Interpretation: It’s essential to evaluate the impact of feature extraction on model performance. Additionally, understanding the extracted features can provide insights into the model’s behavior.
Real-world Applications:
Feature extraction finds applications in various domains:
Image Recognition: Extracting features like edges, shapes, and colors from images helps models recognize objects.
Text Analysis: Feature extraction might involve extracting keywords, sentiment scores, or topic information from text data for tasks like sentiment analysis or document classification.
Sensor Data Analysis: Extracting relevant features from sensor data (e.g., temperature, pressure) helps models monitor equipment health or predict system failures.
By understanding the intricacies of feature extraction, you can transform raw data into a goldmine of information for your machine learning models. This empowers you to extract the essence of your data and unlock its full potential for accurate predictions and insightful analysis.
7. Anomaly Detection
Anomaly detection, like noticing a misspelled word in an essay, equips machine learning models to identify data points that deviate significantly from the norm. These anomalies can signal potential errors, fraud, or critical events that require attention. Let’s delve into the technical aspects:
The Core Idea:
Machine learning models learn the typical patterns and characteristics of data during the training phase.
Anomaly detection algorithms leverage this knowledge to identify data points that fall outside the expected range or exhibit unusual patterns.
Technical Approaches:
There are several approaches to anomaly detection, each suitable for different scenarios:
Statistical Methods: Techniques like outlier detection using standard deviation or z-scores can identify data points that statistically differ from the majority.
Distance-based Methods: These methods measure the distance of a data point from its nearest neighbors in the feature space. Points far away from others are considered anomalies.
Clustering Algorithms: Clustering algorithms can group data points with similar features. Points that don’t belong to any well-defined cluster might be anomalies.
Machine Learning Models: Techniques like One-Class Support Vector Machines (OCSVM) learn a model of “normal” data and then flag any points that deviate from this model as anomalies.
Technical Considerations:
Defining Normality: Clearly defining what constitutes “normal” data is crucial for effective anomaly detection. This often relies on historical data and domain knowledge.
False Positives and False Negatives: Anomaly detection algorithms can generate false positives (flagging normal data as anomalies) and false negatives (missing actual anomalies). Balancing these trade-offs is essential.
Threshold Selection: Setting appropriate thresholds for anomaly scores determines how sensitive the system is to detecting anomalies. A high threshold might miss critical events, while a low threshold can lead to many false positives.
Real-world Applications:
Anomaly detection finds applications in various domains:
Fraud Detection: Identifying unusual transactions in credit card usage patterns can help prevent fraudulent activities.
Network Intrusion Detection: Detecting anomalies in network traffic patterns can help identify potential cyberattacks.
Equipment Health Monitoring: Identifying anomalies in sensor data from machines can predict equipment failures and prevent costly downtime.
Medical Diagnosis: Detecting anomalies in medical scans or patient vitals can help diagnose potential health problems.
By understanding the technicalities of anomaly detection, you can equip your machine learning models with the ability to identify the unexpected. This proactive approach allows you to catch issues early on, improve system security, and optimize various processes across diverse domains.
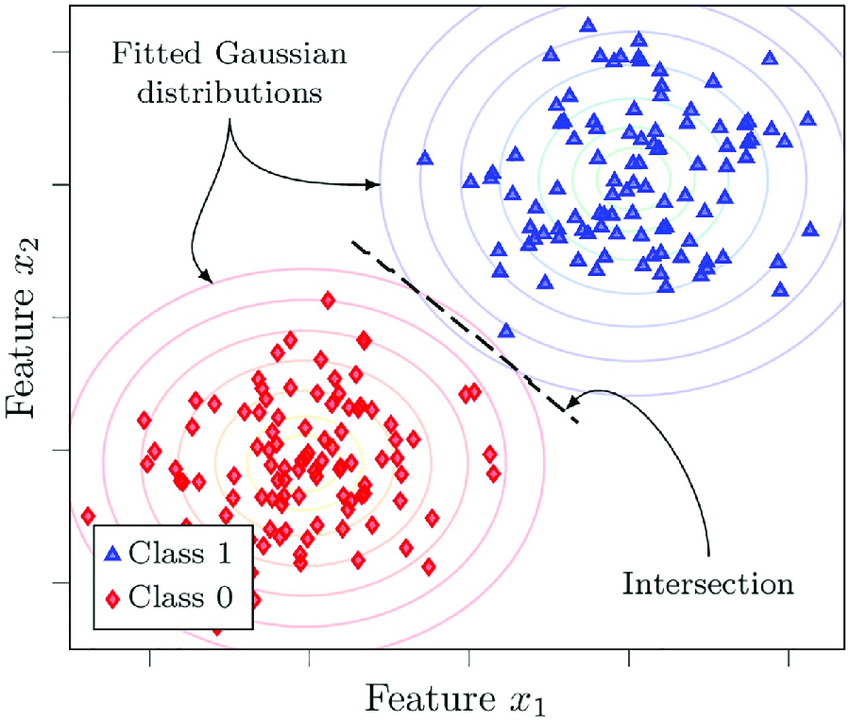
8. Clustering
Clustering, much like grouping similar-colored socks together, is a powerful unsupervised machine learning technique. It delves into the world of unlabeled data, where data points lack predefined categories.
Clustering algorithms automatically group data points with similar characteristics, forming meaningful clusters. Let’s explore the technical aspects:
The Core Idea:
Unsupervised learning means the data points don’t have pre-assigned labels (e.g., shirt, pants).
Clustering algorithms analyze the features (attributes) of data points and group them based on their similarity.
The similarity between data points is often measured using distance metrics like Euclidean distance (straight line distance) in a multi-dimensional feature space.
Types of Clustering Algorithms:
K-Means Clustering: This is a popular and efficient algorithm that partitions data points into a predefined number of clusters (k). It iteratively calculates the centroid (center) of each cluster and assigns data points to the closest centroid until convergence (stable clusters).
Hierarchical Clustering: This method builds a hierarchy of clusters, either in a top-down (divisive) fashion by splitting large clusters or a bottom-up (agglomerative) fashion by merging smaller clusters. The level of granularity in the hierarchy determines the final clustering results.
Density-Based Spatial Clustering of Applications with Noise (DBSCAN): This approach identifies clusters based on areas of high data point density, separated by areas of low density (noise). It doesn’t require predefining the number of clusters and can handle outliers effectively.
Technical Considerations:
Choosing the Right Algorithm: The optimal algorithm depends on the nature of your data, the desired number of clusters, and the presence of noise. Experimentation might be necessary.
Data Preprocessing: Feature scaling and normalization might be crucial for ensuring all features contribute equally to the distance calculations used in clustering.
Evaluating Clustering Results: Metrics like silhouette score or Calinski-Harabasz index can help assess the quality and separation between clusters, but domain knowledge is also valuable for interpreting the results.
Real-world Applications:
Clustering finds applications in various domains:
Customer Segmentation: Grouping customers with similar purchasing behavior allows for targeted marketing campaigns and loyalty programs.
Image Segmentation: Identifying objects or regions of interest within images by grouping pixels with similar color or texture.
Document Clustering: Grouping documents based on topic or content for efficient information retrieval.
Social Network Analysis: Identifying communities or groups of users with similar interests or connections.
By understanding the machine learning technique of clustering, you gain the ability to uncover hidden patterns within your unlabeled data. This allows you to segment data for further analysis, discover new customer groups, and gain valuable insights into the structure of your data.
Kickstart your Learning Journey Today!
In summary, learning machine learning algorithms equips you with valuable skills, opens up career opportunities, and empowers you to make a significant impact in today’s data-driven world. Whether you’re a student, professional, or entrepreneur, investing in ML knowledge can enhance your career prospects.
Machine learning models are algorithms designed to identify patterns and make predictions or decisions based on data. These models are trained using historical data to recognize underlying patterns and relationships. Once trained, they can be used to make predictions on new, unseen data.
Modern businesses are embracing machine learning (ML) models to gain a competitive edge. It enables them to personalize customer experience, detect fraud, predict equipment failures, and automate tasks. Hence, improving the overall efficiency of the business and allow them to make data-driven decisions.
Deploying ML models in their day-to-day processes allows businesses to adopt and integrate AI-powered solutions into their businesses. Since the impact and use of AI are growing drastically, it makes ML models a crucial element for modern businesses.
A PwC study on Global Artificial Intelligence states that the GDP for local economies will get a boost of 26% by 2030 due to the adoption of AI in businesses. This reiterates the increasing role of AI in modern businesses and consequently the need for ML models.
However, deploying ML models in businesses is a complex process and it requires proper testing methods to ensure successful deployment. In this blog, we will explore the 4 main methods to test ML models in the production phase.
What is Machine Learning Model Testing?
In the context of machine learning, model testing refers to a detailed process to ensure that it is robust, reliable, and free from biases. Each component of an ML model is verified, the integrity of data is checked, and the interaction among components is tested.
The main objective of model testing is to identify and fix flaws or vulnerabilities in the ML system. It aims to ensure that the model can handle unexpected inputs, mitigate biases, and remain consistent and robust in various scenarios, including real-world applications.
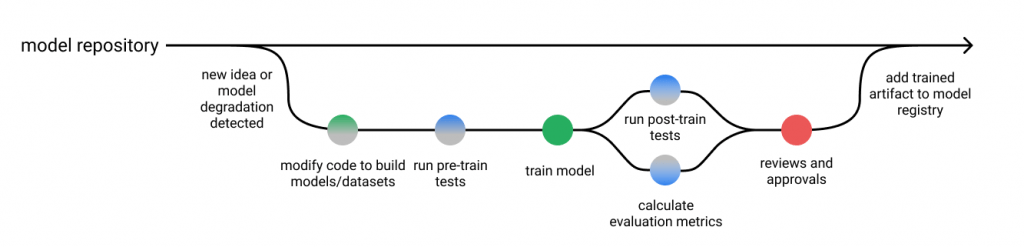
Workflow for model deployment with testing – Source: markovML
It is also important to note that ML model testing is different from model evaluation. Both are different processes and before we explore the different testing methods, let’s understand the difference between machine learning model evaluation and testing.
What is the Difference between Model Evaluation and Testing?
A quick overview of the basic difference between model evaluation and model testing is as follows:
From the above-mentioned details it can be concluded that while model evaluation gives a snapshot of how well a model performs, model testing ensures the model’s reliability, robustness, and fairness in real-world applications. Thus, it is important to test a machine learning model in its production to ensure its effectiveness and efficiency.
Since testing ML models is a very important task, it requires a thorough and efficient approach. Multiple frameworks in the market offer pre-built tools, enforce structured testing, provide diverse testing functionalities, and promote reproducibility. It results in faster and more reliable testing for robust models.
A list of frameworks to use for ML model testing
Here’s a list of key frameworks used for ML model testing.
TensorFlow
There are three main types of TensorFlow frameworks for testing:
TensorFlow Extended (TFX): This is designed for production pipeline testing, offering tools for data validation, model analysis, and deployment. It provides a comprehensive suite for defining, launching, and monitoring ML models in production.
TensorFlow Data Validation: Useful for testing data quality in ML pipelines.
TensorFlow Model Analysis: Used for in-depth model evaluation.
PyTorch
Known for its dynamic computation graph and ease of use, PyTorch provides model evaluation, debugging, and visualization tools. The torchvision package includes datasets and transformations for testing and validating computer vision models.
Scikit-learn
Scikit-learn is a versatile Python library that offers various algorithms and model evaluation metrics, including cross-validation and grid search for hyperparameter tuning. It is widely used for data mining, analysis, and machine learning tasks.
Fairlearn is a toolkit designed to assess and mitigate fairness and bias issues in ML models. It includes algorithms to reweight data and adjust predictions to achieve fairness, ensuring that models treat all individuals fairly and equitably.
Evidently AI
Evidently AI is an open-source Python tool that is used to analyze, monitor, and debug machine learning models in a production environment. It helps implement testing and monitoring for different model types and data types.
Amazon SageMaker Model Monitor
Amazon SageMaker is a tool that can alert developers of any deviations in model quality so that corrective actions can be taken. It supports no-code monitoring capabilities and custom analysis through coding.
These frameworks provide a comprehensive approach to testing machine learning models, ensuring they are reliable, fair, and well-performing in production environments.
4 Ways to Test ML Models in Production
Now that we have explored the basics of ML model testing, let’s look at the 4 main testing methods for ML models in their production phase.
1. A/B Testing
A visual representation of A/B testing – Source: Medium
This is used to compare two versions of an ML model to determine which one performs better in a real-world setting. This approach is essential for validating the effectiveness of a new model before fully deploying it into production. This helps in understanding the impact of the new model and ensuring it does not introduce unexpected issues.
It works by distributing the incoming requests non-uniformly between the two models. A smaller portion of the traffic is directed to the new model that is being tested to minimize potential risks. The performance of both models is measured and compared based on predefined metrics.
Benefits of A/B Testing
Risk Mitigation: By limiting the exposure of the candidate model, A/B testing helps in identifying any issues in the new model without affecting a large portion of users.
Performance Validation: It allows teams to validate that the new model performs at least as well as, if not better than, the legacy model in a production environment.
Data-Driven Decisions: The results from A/B testing provide concrete data to support decisions on whether to fully deploy the candidate model or make further improvements.
Thus, it is a critical testing step in ML model testing, ensuring that a new model is thoroughly vetted in a real-world environment, thereby maintaining model reliability and performance while minimizing risks associated with deploying untested models.
The canary testing method is used to gradually deploy a new ML model to a small subset of users in production to minimize risks and ensure that the new model performs as expected before rolling it out to a broader audience. This smaller subset of users is often referred to as the ‘canary’ group.
The main goal of this method is to limit the exposure of the new ML model initially. This incremental approach helps in identifying and mitigating any potential issues without affecting the entire user base. The performance of the ML model is monitored in the canary group.
If the model performs well in the canary group, it is gradually rolled out to a larger user base. This process continues incrementally until the new model is fully deployed to all users.
Benefits of Canary Testing
Risk Reduction: By initially limiting the exposure of the new model, canary testing reduces the risk of widespread issues affecting all users. Any problems detected can be addressed before a full-scale deployment.
Controlled Environment: This method provides a controlled environment to observe the new model’s behavior and make necessary adjustments based on real-world data.
User Impact Minimization: Users in the canary group serve as an early indicator of potential issues, allowing teams to respond quickly and minimize the impact on the broader user base.
Canary testing is an effective strategy for deploying new ML models in production. It ensures that potential issues are identified and resolved early, thereby maintaining the stability and reliability of the service while introducing new features or improvements.
3. Interleaved Testing
A display of how interleaving works – Source: Medium
It is used to evaluate multiple ML models by mixing their outputs in real-time within the same user interface or service. This type of testing is particularly useful when you want to compare the performance of different models without exposing users to only one model at a time.
Users interact with the integrated output without knowing which model generated which part of the response. This helps in gathering unbiased user feedback and performance metrics for both models, allowing for a direct comparison under the same conditions and identifying which model performs better in real-world scenarios.
The performance of each model is tracked based on user interactions. Metrics such as click-through rates, engagement, and conversion rates are analyzed to determine which model is more effective.
Benefits of Interleaved Testing
Direct Comparison: Interleaved testing allows for a direct, side-by-side comparison of multiple models under the same conditions, providing more accurate insights into their performance.
User Experience Consistency: Since users are exposed to outputs from both models simultaneously, the overall user experience remains consistent, reducing the risk of user dissatisfaction.
Detailed Feedback: This method provides detailed feedback on how users interact with different model outputs, helping in fine-tuning and improving model performance.
Interleaved testing is a useful testing strategy that ensures a direct comparison, providing valuable insights into model performance. It helps data scientists and engineers to make informed decisions about which model to deploy.
4. Shadow Testing
A glimpse of how shadow testing is implemented – Source: Medium
Shadow testing, also known as dark launching, is a technique used for real-world testing of a new ML model alongside the existing one, providing a risk-free way to gather performance data and insights.
It works by deploying both the new and old ML models in parallel. For each incoming request, the data is sent to both models simultaneously. Both models generate predictions, but only the output from the older model is served to the user. Predictions from the new ML model are logged for later analysis.
These predictions are then compared against the results of the older ML model and any available ground truth data to evaluate the performance of the new model.
Benefits of Shadow Testing
Risk-Free Evaluation: Since the candidate model’s predictions are not served to the users, any errors or issues in the new model do not affect the user experience. This makes shadow testing a safe way to test new models.
Real-World Data: Shadow testing provides insights based on real-world data and conditions, offering a more accurate assessment of the model’s performance compared to offline testing.
Benchmarking: It allows for direct comparison between the legacy and candidate models, making it easier to benchmark the new model’s performance and identify areas for improvement.
Hence, it is a robust technique for evaluating new ML models in a live production environment without impacting the user experience. It provides valuable performance insights, ensures safe testing, and helps in making informed decisions about model deployment.
How to Choose a Testing Technique for Your ML Model Testing?
Choosing the appropriate testing technique for your machine learning models in production depends on several factors, including the nature of your model, the risks associated with its deployment, and the specific requirements of your application.
Here are some key considerations and steps to help you decide on the right testing technique:
Understand the Nature and Requirements of Your Model
Different models (classification, regression, recommendation, etc.) require different testing approaches. Complex models may benefit from more rigorous testing techniques like shadow testing or interleaved testing. Hence, you must understand the nature of your model and its complexity.
Moreover, it is crucial to assess the potential impact of model errors. High-stakes applications, such as financial services or healthcare, may necessitate more conservative and thorough testing techniques.
Evaluate Common Testing Techniques
Review and evaluate the pros and cons of the testing techniques, like the 4 methods discussed earlier in the blog. A thorough understanding of the techniques can make your decision easier and more informed.
While you have multiple options available, the state of your infrastructure and available resources are strong parameters for your final decision. Ensure that your production environment can support the chosen testing technique. For example, shadow testing requires infrastructure capable of parallel processing.
You must also evaluate the available resources, including computational power, storage, and monitoring tools. Techniques like shadow testing and interleaved testing can be resource-intensive. Hence, you must consider both factors when choosing a testing technique for your ML model.
Consider Ethical and Regulatory Constraints
Data privacy and digital ethics are important parameters for modern-day businesses and users. Hence, you must ensure compliance with data privacy regulations such as GDPR or CCPA, especially when handling sensitive data. You must choose techniques that allow for the mitigation of model bias, ensuring fairness in predictions.
Monitor and Iterate
Testing ML models in production is a continuous process. You must continuously track your model performance, data drift, and prediction accuracy over time. This must link to an iterative model improvement process. You can establish a feedback loop to retrain and update the model based on the gathered performance data.
Hence, you must carefully select the model technique for your ML model. You can consider techniques like A/B testing for direct performance comparison, canary testing for gradual rollout, interleaved testing for simultaneous output assessment, and shadow testing for risk-free evaluation.
To Sum it Up…
ML model testing when in production is a critical step. You must ensure your model’s reliability, performance, and safety in real-world scenarios. You can do that by evaluating the model’s performance in a live environment, identifying potential issues, and finding ways to resolve them.
We have explored 4 different methods to test ML models where way offers unique benefits and is suited to different scenarios and business needs. By carefully selecting the appropriate technique, you can ensure your ML models perform as expected, maintain user satisfaction, and uphold high standards of reliability and safety.
If you are interested in learning how to build ML models from scratch, here’s a video for a more engaging learning experience:
The modern era of generative AI is now talking about machine unlearning. It is time to understand that unlearning information is as important for machines as for humans to progress in this rapidly advancing world. This blog explores the impact of machine unlearning in improving the results of generative AI.
However, before we dig deeper into the details, let’s understand what is machine unlearning and its benefits.
What is machine unlearning?
As the name indicates, it is the opposite of machine learning. Hence, it refers to the process of getting a trained model to forget information and specific knowledge it has learned during the training phase.
During machine unlearning, an ML model discards previously learned information and or patterns from its knowledge base. The concept is fairly new and still under research in an attempt to improve the overall ML training process.
A comment on the relevant research
A research paper published by the University of Texas presents machine learning as a paradigm to improve image-to-image generative models. It addresses the gap with a unifying framework focused on implementing machine unlearning to image-specific generative models.
The proposed approach uses encoders in its architecture to enable the model to only unlearn specific information without the need to manipulate the entire model. The research also claims the framework to be generalizable in its application, where the same infrastructure can also be implemented in an encoder-decoder architecture.
A glance at the proposed encoder-only machine unlearning architecture – Source: arXiv
The research also highlights that the proposed framework presents negligible performance degradation and produces effective results from their experiments. This highlights the potential of the concept in refining machine-learning processes and generative AI applications.
Benefits of machine unlearning in generative AI
Machine unlearning is a promising aspect for improving generative AI, empowering it to create enhanced results when creating new things like text, images, or music.
Below are some of the key advantages associated with the introduction of the unlearning concept in generative AI.
Ensuring privacy
With a constantly growing digital database, the security and privacy of sensitive information have become a constant point of concern for individuals and organizations. This issue of data privacy also extends to the process of training ML models where the training data might contain some crucial or private data.
In this dilemma, unlearning is a concept that enables an ML model to forget any sensitive information in its database without the need to remove the complete set of knowledge it trained on. Hence, it ensures that the concerns of data privacy are addressed without impacting the integrity of the ML model.
In extension, it also results in updating the training data for machine-learning models to remove any sources of error. It ensures that a more accurate dataset is available for the model, improving the overall accuracy of the results.
For instance, if a generative AI model produced images based on any inaccurate information it had learned during the training phase, unlearning can remove that data from its database. Removing that association will ensure that the model outputs are refined and more accurate.
Keeping up-to-date
Another crucial aspect of modern-day information is that it is constantly evolving. Hence, the knowledge is updated and new information comes to light. While it highlights the constant development of data, it also results in producing outdated information.
However, success is ensured in keeping up-to-date with the latest trends of information available in the market. With the machine unlearning concept, these updates can be incorporated into the training data for applications without rebooting the existing training models.
Benefits of machine unlearning
Improved control
Unlearning also allows better control over the training data. It is particularly useful in artistic applications of generative AI. Artists can use the concept to ensure that the AI application unlearns certain styles or influences.
As a result, it offers greater freedom of exploration of artistic expression to create more personalized outputs, promising increased innovation and creativity in the results of generative AI applications.
Controlling misinformation
Generative AI is a powerful tool to spread misinformation through the creation of realistic deepfakes and synthetic data. Machine unlearning provides a potential countermeasure that can be used to identify and remove data linked to known misinformation tactics from generative AI models.
This would make it significantly harder for them to be used to create deceptive content, providing increased control over spreading misinformation on digital channels. It is particularly useful in mitigating biases and stereotypical information in datasets.
Hence, the concept of unlearning opens new horizons of exploration in generative AI, empowering players in the world of AI and technology to reap its benefits.
Here’s a comprehensive guide to build, deploy, and manage ML models
Who can benefit from machine unlearning?
A broad categorization of entities and individuals who can benefit from machine unlearning include:
Privacy advocates
In today’s digital world, individual concern for privacy concern is constantly on the rise. Hence, people are constantly advocating their right to keep personal or crucial information private. These advocates for privacy and data security can benefit from unlearning as it addresses their concerns about data privacy.
Tech companies
Digital progress and development are marked by several regulations like GDPR and CCPA. These standards are set in place to ensure data security and companies must abide by these laws to avoid legal repercussions. Unlearning assists tech companies in abiding by these laws, enhancing their credibility among users as well.
Financial institutions
Financial enterprises and institutions deal with huge amounts of personal information and sensitive data of their users. Unlearning empowers them to remove specific data points from their database without impacting the accuracy and model performance.
AI researchers
AI researchers are frequently facing the impacts of their applications creating biased or inaccurate results. With unlearning, they can target such sources of data points that introduce bias and misinformation into the model results. Hence, enabling them to create more equitable AI systems.
Policymakers
A significant impact of unlearning can come from the work of policymakers. Since the concept opens up new ways to handle information and training datasets, policymakers can develop new regulations to mitigate bias and address privacy concerns. Hence, leading the way for responsible AI development.
Thus, machine unlearning can produce positive changes in the world of generative AI, aiding different players to ensure the development of more responsible and equitable AI systems.
Future of machine unlearning
To sum it up, machine unlearning is a new concept in the world of generative AI with promising potential for advancement. Unlearning is a powerful tool for developing AI applications and systems but lacks finesse. Researchers are developing ways to target specific information for removal.
For instance, it can assist the development of an improved text-to-image generator to forget a biased stereotype, leading to fairer and more accurate results. Improved techniques allow the isolation and removal of unwanted data points, giving finer control over what the AI forgets.
Overall, unlearning holds immense potential for shaping the future of generative AI. With more targeted techniques and a deeper understanding of these models, unlearning can ensure responsible use of generative AI, promote artistic freedom, and safeguard against the misuse of this powerful technology.
Feature Engineering is a process of using domain knowledge to extract and transform features from raw data. These features can be used to improve the performance of Machine Learning Algorithms.
Feature Engineering encompasses a diverse array of techniques, including Feature Transformation, Feature Construction, Feature Selection, Feature Scaling, and Feature Extraction, each playing a crucial role in refining and optimizing the representation of data for machine learning tasks.
In this blog, we will discuss one of the feature transformation techniques called feature scaling with examples and see how it will be the game changer for our machine learning model accuracy.
In the world of data science and machine learning, feature transformation plays a crucial role in achieving accurate and reliable results. By manipulating the input features of a dataset, we can enhance their quality, extract meaningful information, and improve the performance of predictive models. Python, with its extensive libraries and tools, offers a streamlined and efficient process for simplifying feature scaling.
What is feature scaling?
Feature scaling is a crucial step in the feature transformation process that ensures all features are on a similar scale. It is the process that normalizes the range of input columns and makes it useful for further visualization and machine learning model training. The figure below shows a quick representation of feature scaling techniques that we will discuss in this blog.
A visual representation of feature scaling techniques – Source: someka.net
Why feature scaling is important?
Feature scaling is important because of several factors:
It improves the machine learning model’s accuracy
It enhances the interpretability of data by transforming features on a common scale, without scaling, it is difficult to make comparisons of two features because of scale difference
It speeds up the convergence in optimization algorithms like gradient descent algorithms
It reduces the computational resources required for training the model
For better accuracy, it is essential for the algorithms that rely on distance measures, such as K-nearest neighbors (KNN) and Support Vector Machines (SVM), to be sensitive to feature scales
Now let’s dive into some important methods of feature scaling and see how they impact data understanding and machine learning model performance.
Normalization
A feature scaling technique is often applied as part of data preparation for machine learning. The goal of normalization is to change the value of numeric columns in the dataset to use a common scale, without distorting differences in the range of values or losing any information.
Min-Max Scaler
The most commonly used normalization technique is min-max scaling, which transforms the features to a specific range, typically between 0 and 1. Scikit-learn has a built-in class available named MinMaxScaler that we can use directly for normalization. It involves subtracting the minimum value and dividing by the range of the feature using this formula.
Where,
Xi is the value we want to normalize.
Xmaxis the maximum value of the feature.
Xminis the minimum value of the feature.
In this transformation, the mean and standard deviation of the feature may behave differently. Our main focus in this normalization is on the minimum and maximum values. Outliers may disrupt our data pattern, so taking care of them is necessary.
Let’s take an example of a wine dataset that contains various ingredients of wine as features. We take two input features: the quantity of alcohol and malic acid and create a scatter plot as shown below.
Scatter plot from the wine dataset
When we create a scatter plot between alcohol and malic acid quantities, we can see that min-max scaling simply compresses our dataset into the range of zero to one, while keeping the distribution unchanged.
Standardization
Standardization is a feature scaling technique in which values of features are centered around the mean with unit variance. It is also called Z-Score Normalization. It subtracts the mean value of the feature and divides by the standard deviation (σ) of the feature using the formula:
Here we leverage a dataset on social network ads to gain a practical understanding of the concept. This dataset includes four input features: User ID, Gender, Age, and Salary. Based on this information, it determines whether the user made a purchase or not (where zero indicates not purchased, and one indicates purchased).
The first five rows of the dataset appear as follows:
Dataset for the standardization example
In this example, we extract only two input features (Age and Salary) and use them to determine whether the output indicates a purchase or not as shown below.
Standard Scaler
We use Standard-Scaler from the Scikit-learn preprocessing module to standardize the input features for this feature scaling technique. The following code demonstrates this as shown.
We can see how our features look before and after standardization below.
Although it appears that the distribution changes after scaling,let’s visualize both distributions through a scatter plot.
Visual representation of the impact of scaling on data
So, when we visualize these distributions through plots, we observe that they remain the same as before. This indicates that scaling doesn’t alter the distribution; it simply centers it around the origin.
Now let’s see what happens when we create a density plot between Age and Estimated Salary with and without scaled features as shown below.
Graphical representation of data standardization
In the first plot, we can observe that we are unable to visualize the plot effectively and are not able to draw any conclusions or insights between age and estimated salary due to scale differences. However, in the second plot, we can visualize it and discern how age and estimated salary relate to each other.
This illustrates how scaling assists us by placing the features on similar scales. Note that this technique does not have any impact on outliers. So, if an outlier is present in the dataset, it remains as it is even after standardization. Therefore, we need to address outliers separately.
Model’s performance comparison
Now we use the logistic regression technique to predict whether a person will make a purchase after seeing an advertisement and observe how the model behaves with scaled features compared to without scaled features.
Here, we can observe a drastic improvement in our model accuracy when we apply the same algorithm to standardized features. Initially, our model accuracy is around 65.8%, and after standardization, it improves to 86.7%
When does it matter?
Note that standardization does not always improve your model accuracy; its effectiveness depends on your dataset and the algorithms you are using. However, it can be very effective when you are working with multivariate analysis and similar methods, such as Principal Component Analysis (PCA), Support Vector Machine (SVM), K-means, Gradient Descent, Artificial Neural Networks (ANN), and K-nearest neighbors (KNN).
However, when you are working with algorithms like decision trees, random forest, Gradient Boosting (G-Boost), and (X-Boost), standardization may not have any impact on improving your model accuracy as these algorithms work on different principles and are not affected by differences in feature scales
To sum it up
We have covered standardization and normalization as two methods of feature scaling, including important techniques like Standard Scaler and Min-Max Scaler. These methods play a crucial role in preparing data for machine learning models, ensuring features are on a consistent scale. By standardizing or normalizing data, we enhance model performance and interpretability, paving the way for more accurate predictions and insights.
The development of generative AI relies on important machine-learning techniques in today’s technological advancement. It makes machine learning (ML) a critical component of data science where algorithms are statistically trained on data.
An ML model learns iteratively to make accurate predictions and take actions. It enables computer programs to perform tasks without depending on programming. Today’s recommendation engines are one of the most innovative products based on machine learning.
Exploring important machine-learning techniques
The realm of ML is defined by several learning methods, each aiming to improve the overall performance of a model. Technological advancement has resulted in highly sophisticated algorithms that require enhanced strategies for training models.
Let’s look at some of the critical and cutting-edge machine-learning techniques of today.
Transfer learning
This technique is based on training a neural network on a base model and using the learning to apply the same model to a new task of interest. Here, the base model represents a task similar to that of interest, enabling the model to learn the major data patterns.
A visual understanding of transfer learning – Source: Medium
Why use transfer learning?It leverages knowledge gained from the first (source) task to improve the performance of the second (target) task. As a result, you can avoid training a model from scratch for related tasks. It is also a useful machine-learning technique when data for the task of interest is limited.
ProsTransfer learning enhances the efficiency of computational resources as the model trains on target tasks with pre-learned patterns. Moreover, it offers improved model performance and allows the reusability of features in similar tasks.
ConsThis machine-learning technique is highly dependent on the similarity of two tasks. Hence, it cannot be used for extremely dissimilar and if applied to such tasks, it risks overfitting the source task during the model training phase.
Fine-tuning
Fine-tuning is a machine-learning technique that aims to support the process of transfer learning. It updates the weights of a model trained on a source task to enhance its adaptability to the new target task. While it looks similar to transfer learning, it does not involve replacing all the layers of a pre-trained network.
Fine-tuning: Improving model performance in transfer learning – Source: Analytics Yogi
Why use fine-tuning?It is useful to enhance the adaptability of a pre-trained model on a new task. It enables the ML model to refine its parameters and learn task-specific patterns needed for improved performance on the target task.
ProsThis machine-learning technique is computationally efficient and offers improved adaptability to an ML model when dealing with transfer learning. The utilization of pre-learned features becomes beneficial when the target task has a limited amount of data.
ConsFine-tuning is sensitive to the choice of hyperparameters and you cannot find the optimal settings right away. It requires experimenting with the model training process to ensure optimal results. Moreover, it also has the risk of overfitting and limited adaptation in case of high dissimilarity in source and target tasks.
Multitask learning
As the name indicates, the multitask machine-learning technique unlocks the power of simultaneity. Here, a model is trained to perform multiple tasks at the same time, sharing the knowledge across these tasks.
Why use multitask learning?It is useful in sharing common representations across multiple tasks, offering improved generalization. You can use it in cases where several related ML tasks can benefit from shared representations.
ProsThe enhanced generalization capability of models ensures the efficient use of data. Leveraging information results in improved model performance and regularization of training. Hence, it results in the creation of more robust training models.
ConsThe increased complexity of this machine-learning technique requires advanced architecture and informed weightage of different tasks. It also depends on the availability of large and diverse datasets for effective results. Moreover, the dissimilarity of tasks can result in unwanted interference in the model performance of other tasks.
Federated learning
It is one of the most advanced machine-learning techniques that focuses on decentralized model training. As a result, the data remains on the user-end devices, and the model is trained locally. It is a revolutionized ML methodology that enhances collaboration among decentralized devices.
Federated learning: A revolutionary ML technique – Source: Sony AI
Why use federated learning?Federated learning is focused on locally trained models that do not require the sharing of raw data of end-user devices. It enables the sharing of key parameters through ML models while not requiring an exchange of sensitive data.
ProsThis machine-learning technique addresses the privacy concerns in ML training. The decentralized approach enables increased collaborative learning with reduced reliance on central servers for ML processes. Moreover, this method is energy-efficient as models are trained locally.
ConsIt cannot be implemented in resource-constrained environments due to large communication overhead. Moreover, it requires compatibility between local data and the global model at the central server, limiting its ability to handle heterogeneous datasets.
Factors determining the best machine-learning technique
While there are numerous machine-learning techniques available for model training today, it is crucial to make the right choice for your business. Below is a list of important factors that you must consider when selecting an ML method for your processes.
Context matters!
Context refers to the type of problem or task at hand. The requirements and constraints of the model-training process is pivotal in choosing an ML technique. For instance, transfer learning and fine-tuning promote knowledge sharing, multitask learning promotes simultaneity, and federated learning supports decentralization.
Data availability and complexity
ML processes require large datasets to develop high-performing models. Hence, the amount and complexity of data determine the choice of method. While transfer learning and multitask learning need large amounts of data, fine-tuning is suitable for a limited dataset. Moreover, data complexity determines knowledge sharing and feature interactions.
Computational resources
Large neural networks and complex machine-learning techniques require large computational power. The availability of hardware resources and time required for training are important measures of consideration when making your choice of the right ML method.
Data privacy considerations
With rapidly advancing technological processes, ML and AI have emerged as major tools that heavily rely on available datasets. It makes data a highly important part of the process, leading to an increase in privacy concerns and protection of critical information. Hence, your choice of machine-learning technique must fulfill your data privacy demands.
Make an informed choice!
An outlook of important machine-learning techniques
In conclusion, it is important to understand the specifications of the four important machine-learning techniques before making a choice. Each method has its requirements and offers unique benefits. It is crucial to understand the dimensions of each technique in the light of key considerations discussed above. Hence, make an informed choice for your ML training processes.
In this blog, we’re diving into a new approach called rank-based encoding that promises not just to shake things up but to guarantee top-notch results.
Rank-based encoding – a breakthrough?
Say hello to rank-based encoding – a technique you probably haven’t heard much about yet, but one that’s about to change the game.
An example illustrating rank-based encoding – Source: ResearchGate
In the vast world of machine learning, getting your data ready is like laying the groundwork for success. One key step in this process is encoding – a way of turning non-numeric information into something our machine models can understand. This is particularly important for categorical features – data that is not in numbers.
Join us as we explore the tricky parts of dealing with non-numeric features, and how rank-based encoding steps in as a unique and effective solution. Get ready for a breakthrough that could redefine your machine-learning adventures – making them not just smoother but significantly more impactful.
Problem under consideration
In our blog, we’re utilizing a dataset focused on House Price Prediction to illustrate various encoding techniques with examples. In this context, we’re treating the city categorical feature as our input, while the output feature is represented by the price.
Some common techniques
The following section will cover some of the commonly used techniques and their challenges. We will conclude by digging deeper into rank-based encoding and how it overcomes these challenges.
One-hot encoding
In One-hot encoding, each category value is represented as an n-dimensional, sparse vector with zero entries except for one of the dimensions. For example, if there are three values for the categorical feature City, i.e. Chicago, Boston, Washington DC, the one-hot encoded version of the city will be as depicted in Table 1.
If there is a wide range of categories present in a categorical feature, one-hot encoding increases the number of columns(features) linearly which requires high computational power during the training phase.
City
City Chicago
City Boston
Washington DC
Chicago
1
0
0
Boston
0
1
0
Washington DC
0
0
1
Table 1
Label encoding
This technique assigns a label to each value of a categorical column based on alphabetical order. For example, if there are three values for the categorical feature City, i.e. Chicago, Boston, Washington DC, the label encoded version will be as depicted in Table 2.
Since B comes first in alphabetical order, this technique assigns Boston the label 0, which leads to meaningless learning of parameters.
City
City Label Encoding
Chicago
1
Boston
0
Washington DC
2
Table 2
Binary encoding
It involves converting each category into a binary code and then splitting the resulting binary string into columns. For example, if there are three values for the categorical feature City, i.e. Chicago, Boston, Washington DC, the binary encoded version of a city can be observed from Table 3.
Since there are 3 cities, two bits would be enough to uniquely represent each category. Therefore, two columns will be constructed which increases dimensions. However, this is not meaningful learning as we are assigning more weightage to one category than others.
Chicago is assigned 00, so our model would give it less weightage during the learning phase. If any categorical column has a wide range of unique values, this technique requires a large amount of computational power, as an increase in the number of bits results in an increase in the number of dimensions (features) significantly.
City
City 0
City 1
Chicago
0
0
Boston
0
1
Washington DC
1
0
Table 3
Hash encoding
It uses the hashing function to convert category data into numerical values. Using hashed functions solves the problem of a high number of columns if the categorical feature has a large number of categories. We can define how many numerical columns we want to encode our feature into.
However, in the case of high cardinality of a categorical feature, while mapping it into a lower number of numerical columns, loss of information is inevitable. If we use a hash function with one-to-one mapping, the result would be the same as one-hot encoding.
Rank-based Encoding:
In this blog, we propose rank-based encoding which aims to encode the data in a meaningful manner with no increase in dimensions. Thus, eliminating the increased computational complexity of the algorithm as well as preserving all the information of the feature.
Rank-based encoding works by computing the average of the target variable against each category of the feature under consideration. This average is then sorted in decreasing order from high to low and each category is assigned a rank based on the corresponding average of a target variable. An example is illustrated in Table 4 which is explained below:
The average price of Washington DC = (60 + 55)/2 = 57.5 Million
The average price of Boston = (20 +12+18)/3 = 16.666 Million
The average price of Chicago = (40 + 35)/2 = 37.5 Million
In the rank-based encoding process, each average value is assigned a rank in descending order.
For instance, Washington DC is given rank 1, Chicago gets rank 2, and Boston is assigned rank 3. This technique significantly enhances the correlation between the city (input feature) and price variable (output feature), ensuring more efficient model learning.
In my evaluation, I assessed model metrics such as R2 and RMSE. The results demonstrated significantly lower values compared to other techniques discussed earlier, affirming the effectiveness of this approach in improving overall model performance.
City
Price
City Rank
Washington DC
60 Million
1
Boston
20 Million
3
Chicago
40 Million
2
Chicago
35 Million
2
Boston
12 Million
3
Washington DC
55 Million
1
Boston
18 Million
3
Table 4
Results
We summarize the pros and cons of each technique in Table 5. Rank-based encoding emerges to be the best in all aspects. Effective data preprocessing is crucial for the optimal performance of machine learning models. Among the various techniques, rank-based encoding is a powerful method that contributes to enhanced model learning.
Rank-based encoding technique facilitates a stronger correlation between input and output variables, leading to improved model performance. The positive impact is evident when evaluating the model using metrics like RMSE and R2 etc. In our case, these enhancements reflect a notable boost in overall model performance.
In today’s world of AI, we’re seeing a big push from both new and established tech companies to build the most powerful language models. Startups like OpenAI and big tech like Google are all part of this competition.
They are creating huge models, like OpenAI’s GPT-4, which has an impressive 1.76 trillion parameters, and Google’s Gemini, which also has a ton of parameters.
But the question arises, is it optimal to always increase the size of the model to make it function well? In other words, is scaling the model always the most helpful choice given how expensive it is to train the model on such huge amounts of data?
Well, this question isn’t as simple as it sounds because making a model better doesn’t just come down to adding more training data.
There have been different studies that show that increasing the size of the model leads to different challenges altogether. In this blog, we’ll be mainly focusing on the inverse scaling.
The Allure of Big Models
Perception of large models equating to better models
The general perception that larger models equate to better performance stems from observed trends in AI and machine learning. As language models increase in size – through more extensive training data, advanced algorithms, and greater computational power – they often demonstrate enhanced capabilities in understanding and generating human language.
This improvement is typically seen in their ability to grasp nuanced context, generate more coherent and contextually appropriate responses, and perform a wider array of complex language tasks.
Consequently, the AI field has often operated under the assumption that scaling up model size is a straightforward path to improved performance. This belief has driven much of the development and investment in ever-larger language models.
However, there are several theories that challenge this notion. Let us explore the concept of inverse scaling and different scenarios where inverse scaling is in action.
Inverse Scaling in Language Models
Inverse scaling is a phenomenon observed in language models. It is a situation where the performance of a model improves with the increase in the scale of data and model size, but beyond a certain point, further scaling leads to a decrease in performance.
Several reasons fuel the inverse scaling process including:
Strong Prior
Strong Prior is a key reason for inverse scaling in larger language models. It refers to the tendency of these models to heavily rely on patterns and information they have learned during training.
This can lead to issues such as the Memo Trap, where the model prefers repeating memorized sequences rather than following new instructions.
A strong prior in large language models makes them more susceptible to being tricked due to their over-reliance on patterns learned during training. This reliance can lead to predictable responses, making it easier for users to manipulate the model to generate specific or even inappropriate outputs.
For instance, the model might be more prone to following familiar patterns or repeating memorized sequences, even when these responses are not relevant or appropriate to the given task or context. This can result in the model deviating from its intended function, demonstrating a vulnerability in its ability to adapt to new and varied inputs.
Memo Trap
Source: Inverse Scaling: When Bigger Isn’t Better
Example of Memo Trap
Source: Inverse Scaling: When Bigger Isn’t Better
This task examines if larger language models are more prone to “memorization traps,” where relying on memorized text hinders performance on specific tasks.
Larger models, being more proficient at modeling their training data, might default to producing familiar word sequences or revisiting common concepts, even when prompted otherwise.
This issue is significant as it highlights how strong memorization can lead to failures in basic reasoning and instruction-following. A notable example is when a model, despite being asked to generate positive content, ends up reproducing harmful or biased material due to its reliance on memorization. This demonstrates a practical downside where larger LMs might unintentionally perpetuate undesirable behavior.
Unwanted Imitation
“Unwanted Imitation” in larger language models refers to the models’ tendency to replicate undesirable patterns or biases present in their training data.
As these models are trained on vast and diverse datasets, they often inadvertently learn and reproduce negative or inappropriate behaviors and biases found in the data.
This replication can manifest in various ways, such as perpetuating stereotypes, generating biased or insensitive responses, or reinforcing incorrect information.
The larger the model, the more data it has been exposed to, potentially amplifying this issue. This makes it increasingly challenging to ensure that the model’s outputs remain unbiased and appropriate, particularly in complex or sensitive contexts.
Distractor Task
The concept of “Distractor Task” refers to a situation where the model opts for an easier subtask that appears related but does not directly address the main objective.
In such cases, the model might produce outputs that seem relevant but are actually off-topic or incorrect for the given task.
This tendency can be a significant issue in larger models, as their extensive training might make them more prone to finding and following these simpler paths or patterns, leading to outputs that are misaligned with the user’s actual request or intention. Here’s an example:
Source: Inverse Scaling: When Bigger Isn’t Better
The correct answer should be ‘pigeon’ because a beagle is indeed a type of dog.
This mistake happens because, even though these larger programs can understand the question format, they fail to grasp the ‘not’ part of the question. So, they’re getting distracted by the easier task of associating ‘beagle’ with ‘dog’ and missing the actual point of the question, which is to identify what a beagle is not.
4. Spurious Few-Shot:
Source: Inverse Scaling: When Bigger Isn’t Better
In few-shot learning, a model is given a small number of examples (shots) to learn from and generalize its understanding to new, unseen data. The idea is to teach the model to perform a task with as little prior information as possible.
However, “Spurious Few-Shot” occurs when the few examples provided to the model are misleading in some way, leading the model to form incorrect generalizations or outputs. These examples might be atypical, biased, or just not representative enough of the broader task or dataset. As a result, the model learns the wrong patterns or rules from these examples, causing it to perform poorly or inaccurately when applied to other data.
In this task, the few-shot examples are designed with a correct answer but include a misleading pattern: the sign of the outcome of a bet always matches the sign of the expected value of the bet. This pattern, however, does not apply across all possible examples within the broader task set
Beyond size: future of intelligent learning models
Diving into machine learning, we’ve seen that bigger isn’t always better with something called inverse scaling. Think about it like this: even with super smart computer programs, doing tasks like spotting distractions, remembering quotes wrong on purpose, or copying bad habits can really trip them up. This shows us that even the fanciest programs have their limits and it’s not just about making them bigger. It’s about finding the right mix of size, smarts, and the ability to adapt.
Imagine a world where your business could make smarter decisions, predict customer behavior with astonishing accuracy, and automate tasks that used to take hours of manual labor. That world is not science fiction—it’s the reality of machine learning (ML).
In this blog post, we’ll break down the end-to-end ML process in business, guiding you through each stage with examples and insights that make it easy to grasp. Whether you’re new to ML or looking to deepen your understanding, this guide will equip you to harness its transformative power.
1. Defining the problem and goals: Setting the course for success
Every ML journey begins with a clear understanding of the problem you want to solve. Are you aiming to:
Personalize customer experiences like Netflix’s recommendation engine?
Optimize supply chains like Walmart’s inventory management.
Predict maintenance needs like GE’s predictive maintenance for aircraft engines?
Detect fraud like PayPal’s fraud detection system?
Articulating your goals with precision ensures you’ll choose the right ML approach and measure success effectively.
2. Data collection and preparation: The foundation for insights
ML thrives on data, so gathering and preparing high-quality data is crucial. This involves:
Collecting relevant data from various sources, such as customer transactions, sensor readings, or social media interactions.
Cleaning the data to remove errors and inconsistencies.
Formatting the data in a way that ML algorithms can understand.
Think of this stage as building the sturdy foundation upon which your ML models will stand.
3. Model selection and training: Teaching machines to learn
With your data ready, it’s time to select an appropriate ML algorithm. Popular choices include:
Supervised learning algorithms like linear regression or decision trees for problems with labeled data.
Unsupervised learning algorithms like clustering solve problems without labeled data.
Once you’ve chosen your algorithm, you’ll train the model using your prepared data. This process involves the model “learning” patterns and relationships within the data, enabling it to make predictions or decisions on new, unseen data.
Before deploying your ML model into the real world, it’s essential to evaluate its performance. This involves testing it on a separate dataset to assess its accuracy, precision, and recall. If the model’s performance isn’t up to par, you’ll need to refine it through techniques like:
Adjusting hyperparameters (settings that control the learning process).
Gathering more data.
Trying different algorithms.
5. Deployment: Putting ML into action
Once you’re confident in your model’s accuracy, it’s time to integrate it into your business operations. This could involve:
Embedding the model into a web or mobile application.
Integrating it into a decision-making system.
Using it to automate tasks.
6. Monitoring and maintenance: Keeping ML on track
ML models aren’t set-and-forget solutions. They require ongoing monitoring to ensure they continue to perform as expected. Over time, data patterns may shift or new business needs may emerge, necessitating model updates or retraining.
Leading businesses using machine learning applications
Airbnb:
Predictive search: Analyzing guest preferences and property features to rank listings that are most likely to be booked.
Image classification: Automatically classifying photos to showcase the most attractive aspects of a property.
Dynamic pricing: Suggesting optimal prices for hosts based on demand, seasonality, and other factors
Tinder:
Personalized recommendations: Using algorithms to suggest potential matches based on user preferences and behavior
Image recognition: Automatically identifying and classifying photos to improve matching accuracy
Fraud detection: Identifying fake profiles and preventing scams
Spotify:
Personalized playlists: Recommending songs and artists based on user listening habits
Discover Weekly: Generating a unique playlist of new music discoveries for each user every week
Audio feature analysis: Recommending music based on similarities in audio features, such as tempo, rhythm, and mood. (Source)
Walmart:
Inventory management: Predicting demand for products and optimizing inventory levels to reduce waste and stockouts.
Pricing optimization: Dynamically adjusting prices based on competition, customer demand, and other factors
Personalized recommendations: Recommending products to customers based on their purchase history and browsing behavior
Google:
Search engine ranking: Ranking search results based on relevance and quality using algorithms like PageRank
Ad targeting: Delivering personalized ads to users based on their interests, demographics, and online behavior
Image recognition: Identifying objects, faces, and scenes in photos and videos
Language translation: Translating text between languages with high accuracy
By following these steps and embracing a continuous learning approach, you can unlock the remarkable potential of ML to drive innovation, efficiency, and growth in your business.
Acquiring and preparing real-world data for machine learning is costly and time-consuming. Synthetic data in machine learning offers an innovative solution.
To train machine learning models, you need data. However, collecting and labeling real-world data can be costly, time-consuming, and inaccurate. Synthetic data offers a solution to these challenges.
Scalability: Easily generate synthetic data for large-scale projects.
Accuracy: Synthetic data can match real data quality.
Privacy: No need to collect personal information.
Safety: Generate safe data for accident prevention.
Why you need synthetic data in machine learning?
In the realm of machine learning, the foundation of successful models lies in high-quality, diverse, and well-balanced datasets. To achieve accuracy, models need data that mirrors real-world scenarios accurately.
Synthetic data, which replicates the statistical properties of real data, serves as a crucial solution to address the challenges posed by data scarcity and imbalance. This article delves into the pivotal role that synthetic data plays in enhancing model performance, enabling data augmentation, and tackling issues arising from imbalanced datasets.
Improving model performance
Synthetic data acts as a catalyst in elevating model performance. It enriches existing datasets by introducing artificial samples that closely resemble real-world data. By generating synthetic samples with statistical patterns akin to genuine data, machine learning models become less prone to overfitting, more adept at generalization, and capable of achieving higher accuracy rates.
Data augmentation is a widely practiced technique in machine learning aimed at expanding training datasets. It involves creating diverse variations of existing samples to equip models with a more comprehensive understanding of the data distribution.
Synthetic data plays a pivotal role in data augmentation by introducing fresh and varied samples into the training dataset. For example, in tasks such as image classification, synthetic data can produce augmented images with different lighting conditions, rotations, or distortions. This empowers models to acquire robust features and adapt effectively to the myriad real-world data variations.
Handling imbalanced datasets
Imbalanced datasets, characterized by a significant disparity in the number of samples across different classes, pose a significant challenge to machine learning models.
Synthetic data offers a valuable solution to address this issue. By generating synthetic samples specifically for the underrepresented classes, it rectifies the imbalance within the dataset. This ensures that the model does not favor the majority class, facilitating the accurate prediction of all classes and ultimately leading to superior overall performance.
Benefits and considerations
Leveraging synthetic data presents a multitude of benefits. It reduces reliance on scarce or sensitive real data, enabling researchers and practitioners to work with more extensive and diverse datasets. This, in turn, leads to improved model performance, shorter development cycles, and reduced data collection costs. Furthermore, synthetic data can simulate rare or extreme events, allowing models to learn and respond effectively in challenging scenarios.
However, it is imperative to consider the limitations and potential pitfalls associated with the use of synthetic data. The synthetic data generated must faithfully replicate the statistical characteristics of real data to ensure models generalize effectively.
Rigorous evaluation metrics and techniques should be employed to assess the quality and utility of synthetic datasets. Ethical concerns, including privacy preservation and the inadvertent introduction of biases, demand meticulous attention when both generating and utilizing synthetic data.
Applications for synthetic data
Synthetic data finds applications across diverse domains. It can be instrumental in training machine learning models for self-driving cars, aiding them in recognizing objects and navigating safely. In the field of medical diagnosis, synthetic data can train models to identify various diseases accurately.
In fraud detection, synthetic data assists in training models to identify and flag fraudulent transactions promptly. Finally, in risk assessment, synthetic data empowers models to predict the likelihood of events such as natural disasters or financial crises with greater precision.
In conclusion, synthetic data emerges as a potent tool in machine learning, addressing the challenges posed by data scarcity, diversity, and class imbalance. It unlocks the potential for heightened accuracy, robustness, and generalization in machine learning models.
Nevertheless, a meticulous evaluation process, rigorous validation, and an unwavering commitment to ethical considerations are indispensable to ensure the responsible and effective use of synthetic data in real-world applications.
Conclusion
Synthetic data enhances machine learning models by addressing data scarcity, diversity, and class imbalance. It unlocks potential accuracy, robustness, and generalization. However, rigorous evaluation, validation, and ethical considerations are essential for responsible real-world use.
ML models have grown significantly in recent years, and businesses increasingly rely on them to automate and optimize their operations. However, managing ML models can be challenging, especially as models become more complex and require more resources to train and deploy. This has led to the emergence of MLOps as a way to standardize and streamline the ML workflow.
MLOps emphasizes the need for continuous integration and continuous deployment (CI/CD) in the ML workflow, ensuring that models are updated in real-time to reflect changes in data or ML algorithms. This infrastructure is valuable in areas where accuracy, reproducibility, and reliability are critical, such as healthcare, finance, and self-driving cars.
By implementing MLOps, organizations can ensure that their ML models are continuously updated and accurate, helping to drive innovation, reduce costs, and improve efficiency.
What is MLOps?
MLOps is a methodology combining ML and DevOps practices to streamline developing, deploying, and maintaining ML models. MLOps share several key characteristics with DevOps, including:
CI/CD: MLOps emphasizes the need for a continuous cycle of code, data, and model updates in ML workflows. This approach requires automating as much as possible to ensure consistent and reliable results.
Automation: Like DevOps, MLOps stresses the importance of automation throughout the ML lifecycle. Automating critical steps in the ML workflow, such as data processing, model training, and deployment, results in a more efficient and reliable workflow.
Collaboration and transparency: MLOps encourages a collaborative and transparent culture of shared knowledge and expertise across teams developing and deploying ML models. This helps to ensure a streamlined process, as handoff expectations will be more standardized.
Infrastructure as Code (IaC): DevOps and MLOps employ an “infrastructure as code” approach, in which infrastructure is treated as code and managed through version control systems. This approach allows teams to manage infrastructure changes more efficiently and reproducibly.
Testing and monitoring: MLOps and DevOps emphasize the importance of testing and monitoring to ensure consistent and reliable results. In MLOps, this involves testing and monitoring the accuracy and performance of ML models over time.
Flexibility and agility: DevOps and MLOps emphasize flexibility and agility in response to changing business needs and requirements. This means being able to rapidly deploy and iterate on ML models to keep up with evolving business demands.
The bottom line is that ML has a lot of variability in its behavior, given that models are essentially a black box used to generate some prediction. While DevOps and MLOps share many similarities, MLOps requires a more specialized set of tools and practices to address the unique challenges posed by data-driven and computationally intensive ML workflows.
ML workflows often require a broad range of technical skills that go beyond traditional software development, and they may involve specialized infrastructure components, such as accelerators, GPUs, and clusters, to manage the computational demands of training and deploying ML models.
Nevertheless, taking the best practices of DevOps and applying them across the ML workflow will significantly reduce project times and provide the structure ML needs to be effective in production.
Importance and benefits of MLOps in modern business
ML has revolutionized how businesses analyze data, make decisions, and optimize operations. It enables organizations to create powerful, data-driven models that reveal patterns, trends, and insights, leading to more informed decision-making and more effective automation.
However, effectively deploying and managing ML models can be challenging, which is where MLOps comes into play. MLOps is becoming increasingly important for modern businesses because it offers a range of benefits, including:
Faster development time: It allows organizations to accelerate the development life-cycle of ML models, reducing the time to market and enabling businesses to respond quickly to changing market demands. Furthermore, MLOps can help automate many tasks in data collection, model training, and deployment, freeing up resources and speeding up the overall process.
Better model performance: With MLOps, businesses can continuously monitor and improve the performance of their ML models. MLOps facilitates automated testing mechanisms for ML models, which detects problems related to model accuracy, model drift, and data quality. Organizations can improve their ML models’ overall performance and accuracy by addressing these issues early, translating into better business outcomes.
More Reliable Deployments: It allows businesses to deploy ML models more reliably and consistently across different production environments. By automating the deployment process, MLOps reduces the risk of deployment errors and inconsistencies between different environments when running in production.
Reduced costs and Improved Efficiency: Implementing MLOps can help organizations reduce costs and improve overall efficiency. By automating many tasks involved in data processing, model training, and deployment, organizations can reduce the need for manual intervention, resulting in a more efficient and cost-effective workflow.
In summary, MLOps is essential for modern businesses looking to leverage the transformative power of ML to drive innovation, stay ahead of the competition, and improve business outcomes.
By enabling faster development time, better model performance, more reliable deployments, and enhanced efficiency, MLOps is instrumental in unlocking the full potential of harnessing ML for business intelligence and strategy.
Utilizing MLOps tools will also allow team members to focus on more important matters and businesses to save on having large dedicated teams to maintain redundant workflows.
The MLOps lifecycle
Whether creating your own MLOps infrastructure or selecting from various available MLOps platforms online, ensuring your infrastructure encompasses the four features mentioned below is critical to success. By selecting MLOps tools that address these vital aspects, you will create a continuous cycle from data scientists to deployment engineers to deploy models quickly without sacrificing quality.
Continuous Integration (CI)
Continuous Integration (CI) involves constantly testing and validating changes made to code and data to ensure they meet a set of defined standards. In MLOps, CI integrates new data and updates to ML models and supporting code. CI helps teams catch issues early in the development process, enabling them to collaborate more effectively and maintain high-quality ML models. Examples of CI practices in MLOps include:
Automated data validation checks to ensure data integrity and quality.
Model version control to track changes in model architecture and hyperparameters.
Automated unit testing of model code to catch issues before the code is merged into the production repository.
Continuous Deployment (CD)
Continuous Deployment (CD) is the automated release of software updates to production environments, such as ML models or applications. In MLOps, CD focuses on ensuring that the deployment of ML models is seamless, reliable, and consistent.
CD reduces the risk of errors during deployment and makes it easier to maintain and update ML models in response to changing business requirements. Examples of CD practices in MLOps include:
Automated ML pipeline with continuous deployment tools like Jenkins or CircleCI for integrating and testing model updates, then deploying them to production.
Containerization of ML models using technologies like Docker to achieve a consistent deployment environment, reducing potential deployment issues.
Implementing rolling deployments or blue-green deployments minimizes downtime and allows for an easy rollback of problematic updates.
Continuous Training (CT)
Continuous Training (CT) involves updating ML models as new data becomes available or as existing data changes over time. This essential aspect of MLOps ensures that ML models remain accurate and effective while considering the latest data and preventing model drift. Regularly training models with new data helps maintain optimal performance and achieve better business outcomes. Examples of CT practices in MLOps include:
Setting policies (i.e., accuracy thresholds) that trigger model retraining to maintain up-to-date accuracy.
Using active learning strategies to prioritize collecting valuable new data for training.
Employing ensemble methods to combine multiple models trained on different subsets of data, allowing for continuous model improvement and adaptation to changing data patterns.
Continuous Monitoring (CM)
Continuous Monitoring (CM) involves constantly analyzing the performance of ML models in production environments to identify potential issues, verify that models meet defined standards, and maintain overall model effectiveness. MLOps practitioners use CM to detect issues like model drift or performance degradation, which can compromise the accuracy and reliability of predictions.
By regularly monitoring the performance of their models, organizations can proactively address any problems, ensuring that their ML models remain effective and generate the desired results. Examples of CM practices in MLOps include:
Tracking key performance indicators (KPIs) of models in production, such as precision, recall, or other domain-specific metrics.
Implementing model performance monitoring dashboards for real-time visualization of model health.
Applying anomaly detection techniques to identify and handle concept drift, ensuring that the model can adapt to changing data patterns and maintain its accuracy over time.
How do MLOps benefit the ML lifecycle?
Managing and deploying ML models can be time-consuming and challenging, primarily due to the complexity of ML workflows, data variability, the need for iterative experimentation, and the continuous monitoring and updating of deployed models.
When the ML lifecycle is not properly streamlined with MLOps, organizations face issues such as inconsistent results due to varying data quality, slower deployment as manual processes become bottlenecks, and difficulty maintaining and updating models rapidly enough to react to changing business conditions. MLOps brings efficiency, automation, and best practices that facilitate each stage of the ML lifecycle.
Consider a scenario where a data science team without dedicated MLOps practices is developing an ML model for sales forecasting. In this scenario, the team may encounter the following challenges:
Data preprocessing and cleansing tasks are time-consuming due to the lack of standardized practices or automated data validation tools.
Difficulty in reproducibility and traceability of experiments due to inadequate versioning of model architecture, hyperparameters, and data sets.
Manual and inefficient deployment processes lead to delays in releasing models to production and the increased risk of errors in production environments.
Manual deployments can also add many failures in automatically scaling deployments across multiple servers online, affecting redundancy and uptime.
Inability to rapidly adjust deployed models to changes in data patterns, potentially leading to performance degradation and model drift.
There are five stages in the ML lifecycle, which are directly improved with MLOps tooling mentioned below.
Data collection and preprocessing
The first stage of the ML lifecycle involves the collection and preprocessing of data. Organizations can ensure data quality, consistency, and manageability by implementing best practices at this stage. Data versioning, automated data validation checks, and collaboration within the team lead to better accuracy and effectiveness of ML models. Examples include:
Data versioning to track changes in the datasets used for modeling.
Automated data validation checks to maintain data quality and integrity.
Collaboration tools within the team to share and manage data sources effectively.
Model development
MLOps helps teams follow standardized practices during the model development stage while selecting algorithms, features, and tuning hyperparameters. This reduces inefficiencies and duplicated efforts, which improves overall model performance. Implementing version control, automated experimentation tracking, and collaboration tools significantly streamline this stage of the ML Lifecycle. Examples include:
Implementing version control for model architecture and hyperparameters.
Establishing a central hub for automated experimentation tracking to reduce repeating experiments and encourage easy comparisons and discussions.
Visualization tools and metric tracking to foster collaboration and monitor the performance of models during development.
Model training and validation
In the training and validation stage, MLOps ensures organizations use reliable processes for training and evaluating their ML models. Organizations can effectively optimize their models’ accuracy by leveraging automation and best practices in training. MLOps practices include cross-validation, training pipeline management, and continuous integration to automatically test and validate model updates. Examples include:
Cross-validation techniques for better model evaluation.
Managing training pipelines and workflows for a more efficient and streamlined process.
Continuous integration workflows to automatically test and validate model updates.
Model deployment
The fourth stage is model deployment to production environments. MLOps practices in this stage help organizations deploy models more reliably and consistently, reducing the risk of errors and inconsistencies during deployment. Techniques such as containerization using Docker and automated deployment pipelines enable seamless integration of models into production environments, facilitating rollback and monitoring capabilities. Examples include:
Containerization using Docker for consistent deployment environments.
Automated deployment pipelines to handle model releases without manual intervention.
Rollback and monitoring capabilities for quick identification and remediation of deployment issues.
Model monitoring and maintenance
The fifth stage involves ongoing monitoring and maintenance of ML models in production. Utilizing MLOps principles for this stage allows organizations to evaluate and adjust models as needed consistently. Regular monitoring helps detect issues like model drift or performance degradation, which can compromise the accuracy and reliability of predictions. Key performance indicators, model performance dashboards, and alerting mechanisms ensure organizations can proactively address any problems and maintain the effectiveness of their ML models. Examples include:
Key performance indicators for tracking the performance of models in production.
Model performance dashboards for real-time visualization of the model’s health.
Alerting mechanisms to notify teams of sudden or gradual changes in model performance, enabling quick intervention and remediation.
MLOps tools and technologies
Adopting the right tools and technologies is crucial to implement MLOps practices and managing end-to-end ML workflows successfully. Many MLOps solutions offer many features, from data management and experimentation tracking to model deployment and monitoring. From an MLOps tool that advertises a whole ML lifecycle workflow, you should expect these features to be implemented in some manner:
End-to-end ML lifecycle management: All these tools are designed to support various stages of the ML lifecycle, from data preprocessing and model training to deployment and monitoring.
Experiment tracking and versioning: These tools provide some mechanism for tracking experiments, model versions, and pipeline runs, enabling reproducibility and comparing different approaches. Some tools might show reproducibility using other abstractions but nevertheless have some form of version control.
Model deployment: While the specifics differ among the tools, they all offer some model deployment functionality to help users transition their models to production environments or to provide a quick deployment endpoint to test with applications requesting model inference.
Integration with popular ML libraries and frameworks: These tools are compatible with popular ML libraries such as TensorFlow, PyTorch, and Scikit-learn, allowing users to leverage their existing ML tools and skills. However, the amount of support each framework has differs across tooling.
Scalability: Each platform provides ways to scale workflows, either horizontally, vertically, or both, enabling users to work with large data sets and train more complex models efficiently.
Extensibility and customization: These tools offer varying extensibility and customization, enabling users to tailor the platform to their specific needs and integrate it with other tools or services as required.
Collaboration and multi-user support: Each platform typically accommodates collaboration among team members, allowing them to share resources, code, data, and experimental results, fostering more effective teamwork and a shared understanding throughout the ML lifecycle.
Environment and dependency handling: Most of these tools include features addressing consistent and reproducible environment handling. This can involve dependency management using containers (i.e., Docker) or virtual environments (i.e., Conda) or providing preconfigured settings with popular data science libraries and tools pre-installed.
Monitoring and alerting: End-to-end MLOps tooling could also offer some form of performance monitoring, anomaly detection, or alerting functionality. This helps users maintain high-performing models, identify potential issues, and ensure their ML solutions remain reliable and efficient in production.
Although there is substantial overlap in the core functionalities provided by these tools, their unique implementations, execution methods, and focus areas set them apart. In other words, judging an MLOps tool at face value might be difficult when comparing their offering on paper. All of these tools provide a different workflow experience.
In the following sections, we’ll showcase some notable MLOps tools designed to provide a complete end-to-end MLOps experience and highlight the differences in how they approach and execute standard MLOps features.
MLFlow
MLflow has unique features and characteristics that differentiate it from other MLOps tools, making it appealing to users with specific requirements or preferences:
Modularity: One of MLflow’s most significant advantages is its modular architecture. It consists of independent components (Tracking, Projects, Models, and Registry) that can be used separately or in combination, enabling users to tailor the platform to their precise needs without being forced to adopt all components.
Language Agnostic: MLflow supports multiple programming languages, including Python, R, and Java, which makes it accessible to a wide range of users with diverse skill sets. This primarily benefits teams with members who prefer different programming languages for their ML workloads.
Integration with Popular Libraries: MLflow is designed to work with popular ML libraries such as TensorFlow, PyTorch, and Scikit-learn. This compatibility allows users to integrate MLflow seamlessly into their existing workflows, taking advantage of its management features without adopting an entirely new ecosystem or changing their current tools.
Active, Open-source Community: MLflow has a vibrant open-source community that contributes to its development and keeps the platform up-to-date with new trends and requirements in the MLOps space. This active community support ensures that MLflow remains a cutting-edge and relevant ML lifecycle management solution.
While MLflow is a versatile and modular tool for managing various aspects of the ML lifecycle, it has some limitations compared to other MLOps platforms. One notable area where MLflow falls short is its need for an integrated, built-in pipeline orchestration and execution feature, such as those provided by TFX or Kubeflow Pipelines.
While MLflow can structure and manage your pipeline steps using its tracking, projects, and model components, users may need to rely on external tools or custom scripting to coordinate complex end-to-end workflows and automate the execution of pipeline tasks.
As a result, organizations seeking more streamlined, out-of-the-box support for complex pipeline orchestration may find that MLflow’s capabilities need improvement and explore alternative platforms or integrations to address their pipeline management needs.
Kubeflow
While Kubeflow is a comprehensive MLOps platform with a suite of components tailored to cater to various aspects of the ML lifecycle, it has some limitations compared to other MLOps tools. Some of the areas where Kubeflow may fall short include:
Steeper Learning Curve: Kubeflow’s strong coupling with Kubernetes may result in a steeper learning curve for users who need to become more familiar with Kubernetes concepts and tooling. This might increase the time required to onboard new users and could be a barrier to adoption for teams without Kubernetes experience.
Limited Language Support: Kubeflow was initially developed with a primary focus on TensorFlow, and although it has expanded support for other ML frameworks like PyTorch and MXNet, it still has a more substantial bias towards the TensorFlow ecosystem. Organizations working with other languages or frameworks may require additional effort to adopt and integrate Kubeflow into their workflows.
Infrastructure Complexity: Kubeflow’s reliance on Kubernetes might introduce additional infrastructure management complexity for organizations without an existing Kubernetes setup. Smaller teams or projects that don’t require the full capabilities of Kubernetes might find Kubeflow’s infrastructure requirements to be an unnecessary overhead.
Less Focus on Experiment Tracking: While Kubeflow does offer experiment tracking functionalities through its Kubeflow Pipelines component, it may not be as extensive or user-friendly as dedicated experiment tracking tools like MLflow or Weights & Biases, another end-to-end MLOps tool with emphasis on real-time model observability tools. Teams with a strong focus on experiment tracking and comparison might find this aspect of Kubeflow needs improvement compared to other MLOps platforms with more advanced tracking features.
Integration with Non-Kubernetes Systems: Kubeflow’s Kubernetes-native design may limit its integration capabilities with other non-Kubernetes-based systems or proprietary infrastructure. In contrast, more flexible or agnostic MLOps tools like MLflow might offer more accessible integration options with various data sources and tools, regardless of the underlying infrastructure.
Kubeflow is an MLOps platform designed as a wrapper around Kubernetes, streamlining deployment, scaling, and managing ML workloads while converting them into Kubernetes-native workloads. This close relationship with Kubernetes offers advantages, such as the efficient orchestration of complex ML workflows.
Still, it might introduce complexities for users lacking Kubernetes expertise, those using a wide range of languages or frameworks, or organizations with non-Kubernetes-based infrastructure. Overall, Kubeflow’s Kubernetes-centric nature provides significant benefits for deployment and orchestration, and organizations should consider these trade-offs and compatibility factors when assessing Kubeflow for their MLOps needs.
TensorFlow Extended (TFX)
TensorFlow Extended (TFX) is an end-to-end platform designed explicitly for TensorFlow users, providing a comprehensive and tightly integrated solution for managing TensorFlow-based ML workflows. TFX excels in areas like:
TensorFlow Integration: TFX’s most notable strength is its seamless integration with the TensorFlow ecosystem. It offers a complete set of components tailored for TensorFlow, making it easier for users already invested in TensorFlow to build, test, deploy, and monitor their ML models without switching to other tools or frameworks.
Production Readiness: TFX is built with production environments in mind, emphasizing robustness, scalability, and the ability to support mission-critical ML workloads. It handles everything from data validation and preprocessing to model deployment and monitoring, ensuring that models are production-ready and can deliver reliable performance at scale.
End-to-end Workflows: TFX provides extensive components for handling various stages of the ML lifecycle. With support for data ingestion, transformation, model training, validation, and serving, TFX enables users to build end-to-end pipelines that ensure the reproducibility and consistency of their workflows.
Extensibility: TFX’s components are customizable and allow users to create and integrate their own components if needed. This extensibility enables organizations to tailor TFX to their specific requirements, incorporate their preferred tools, or implement custom solutions for unique challenges they might encounter in their ML workflows.
However, it’s worth noting that TFX’s primary focus on TensorFlow can be a limitation for organizations that rely on other ML frameworks or prefer a more language-agnostic solution. While TFX delivers a powerful and comprehensive platform for TensorFlow-based workloads, users working with frameworks like PyTorch or Scikit-learn may need to consider other MLOps tools that better suit their requirements.
TFX’s strong TensorFlow integration, production readiness, and extensible components make it an attractive MLOps platform for organizations heavily invested in the TensorFlow ecosystem. Organizations can assess the compatibility of their current tools and frameworks and decide whether TFX’s features align well with their specific use cases and needs in managing their ML workflows.
MetaFlow
Metaflow is an MLOps platform developed by Netflix, designed to streamline and simplify complex, real-world data science projects. Metaflow shines in several aspects due to its focus on handling real-world data science projects and simplifying complex ML workflows. Here are some areas where Metaflow excels:
Workflow Management: Metaflow’s primary strength lies in managing complex, real-world ML workflows effectively. Users can design, organize, and execute intricate processing and model training steps with built-in versioning, dependency management, and a Python-based domain-specific language.
Observable: Metaflow provides functionality to observe inputs and outputs after each pipeline step, making it easy to track the data at various stages of the pipeline.
Scalability: Metaflow easily scales workflows from local environments to the cloud and has tight integration with AWS services like AWS Batch, S3, and Step Functions. This makes it simple for users to run and deploy their workloads at scale without worrying about the underlying resources.
Built-in Data Management: Metaflow provides tools for efficient data management and versioning by automatically keeping track of datasets used by the workflows. It ensures data consistency across different pipeline runs and allows users to access historical data and artifacts, contributing to reproducibility and reliable experimentation.
Fault-Tolerance and Resilience: Metaflow is designed to handle the challenges that arise in real-world ML projects, such as unexpected failures, resource constraints, and changing requirements. It offers features like automatic error handling, retry mechanisms, and the ability to resume failed or halted steps, ensuring that workflows can be executed reliably and efficiently in various situations.
AWS Integration: As Netflix developed Metaflow, it closely integrates with Amazon Web Services (AWS) infrastructure. This makes it significantly easier for users already invested in the AWS ecosystem to leverage existing AWS resources and services in their ML workloads managed by Metaflow. This integration allows for seamless data storage, retrieval, processing, and control access to AWS resources, further streamlining the management of ML workflows.
While Metaflow has several strengths, there are certain areas where it may lack or fall short when compared to other MLOps tools:
Limited deep learning support: Metaflow was initially developed to focus on typical data science workflows and traditional ML methods rather than deep learning. This might make it less suitable for teams or projects primarily working with deep learning frameworks like TensorFlow or PyTorch.
Experiment tracking: Metaflow offers some experiment-tracking functionalities. Its focus on workflow management and infrastructural simplicity might make its tracking capabilities less comprehensive than dedicated experiment-tracking platforms like MLflow or Weights & Biases.
Kubernetes-native orchestration: Metaflow is a versatile platform that can be deployed on various backend solutions, such as AWS Batch and container orchestration systems. However, it lacks the Kubernetes-native pipeline orchestration found in tools like Kubeflow, which allows running entire ML pipelines as Kubernetes resources.
Language support: Metaflow primarily supports Python, which is advantageous for most data science practitioners but might be a limitation for teams using other programming languages, such as R or Java, in their ML projects.
ZenML
ZenML is an extensible, open-source MLOps framework designed to make ML reproducible, maintainable, and scalable. ZenML is intended to be a highly extensible and adaptable MLOps framework.
Its main value proposition is that it allows you to easily integrate and “glue” together various machine learning components, libraries, and frameworks to build end-to-end pipelines. ZenML’s modular design makes it easier for data scientists and engineers to mix and match different ML frameworks and tools for specific tasks within the pipeline, reducing the complexity of integrating various tools and frameworks.
Here are some areas where ZenML excels:
ML pipeline abstraction: ZenML offers a clean, Pythonic way to define ML pipelines using simple abstractions, making it easy to create and manage different stages of the ML lifecycle, such as data ingestion, preprocessing, training, and evaluation.
Reproducibility: ZenML strongly emphasizes reproducibility, ensuring pipeline components are versioned and tracked through a precise metadata system. This guarantees that ML experiments can be replicated consistently, preventing issues related to unstable environments, data, or dependencies.
Backend orchestrator integration: ZenML supports different backend orchestrators, such as Apache Airflow, Kubeflow, and others. This flexibility lets users choose the backend that best fits their needs and infrastructure, whether managing pipelines on their local machines, Kubernetes, or a cloud environment.
Extensibility: ZenML offers a highly extensible architecture that allows users to write custom logic for different pipeline steps and easily integrate with their preferred tools or libraries. This enables organizations to tailor ZenML to their specific requirements and workflows.
Dataset Versioning: ZenML focuses on efficient data management and versioning, ensuring pipelines have access to the correct versions of data and artifacts. This built-in data management system allows users to maintain data consistency across various pipeline runs and fosters transparency in the ML workflows.
High integration with ML frameworks: ZenML offers smooth integration with popular ML frameworks, including TensorFlow, PyTorch, and Scikit-learn. Its ability to work with these ML libraries allows practitioners to leverage their existing skills and tools while utilizing ZenML’s pipeline management.
In summary, ZenML excels in providing a clean pipeline abstraction, fostering reproducibility, supporting various backend orchestrators, offering extensibility, maintaining efficient dataset versioning, and integrating with popular ML libraries. Its focus on these aspects makes ZenML particularly suitable for organizations seeking to improve the maintainability, reproducibility, and scalability of their ML workflows without shifting too much of their infrastructure to new tooling.
What’s the right tool for me?
With so many MLOps tools available, how do you know which one is for you and your team? When evaluating potential MLOps solutions, several factors come into play. Here are some key aspects to consider when choosing MLOps tools tailored to your organization’s specific needs and goals:
Organization Size and Team Structure: Consider the size of your data science and engineering teams, their level of expertise, and the extent to which they need to collaborate. Larger groups or more complex hierarchical structures might benefit from tools with robust collaboration and communication features.
Complexity and Diversity of ML Models: Evaluate the range of algorithms, model architectures, and technologies used in your organization. Some MLOps tools cater to specific frameworks or libraries, while others offer more extensive and versatile support.
Level of Automation and Scalability: Determine the extent to which you require automation for tasks like data preprocessing, model training, deployment, and monitoring. Also, understand the importance of scalability in your organization, as some MLOps tools provide better support for scaling up computations and handling large amounts of data.
Integration and Compatibility: Consider the compatibility of MLOps tools with your existing technology stack, infrastructure, and workflows. Seamless integration with your current systems will ensure a smoother adoption process and minimize disruptions to ongoing projects.
Customization and Extensibility: Assess the level of customization and extensibility needed for your ML workflows, as some tools provide more flexible APIs or plugin architectures that enable the creation of custom components to meet specific requirements.
Cost and Licensing: Keep in mind the pricing structures and licensing options of the MLOps tools, ensuring that they fit within your organization’s budget and resource constraints.
Security and Compliance: Evaluate how well the MLOps tools address security, data privacy, and compliance requirements. This is especially important for organizations operating in regulated industries or dealing with sensitive data.
Support and Community: Consider the quality of documentation, community support, and the availability of professional assistance when needed. Active communities and responsive support can be valuable when navigating challenges or seeking best practices.
By carefully examining these factors and aligning them with your organization’s needs and goals, you can make informed decisions when selecting MLOps tools that best support your ML workflows and enable a successful MLOps strategy.
MLOps best practices
Establishing best practices in MLOps is crucial for organizations looking to develop, deploy, and maintain high-quality ML models that drive value and positively impact their business outcomes. By implementing the following practices, organizations can ensure that their ML projects are efficient, collaborative, and maintainable while minimizing the risk of potential issues arising from inconsistent data, outdated models, or slow and error-prone development:
Ensuring data quality and consistency: Establish robust preprocessing pipelines, use tools for automated data validation checks like Great Expectations or TensorFlow Data Validation, and implement data governance policies that define data storage, access, and processing rules. A lack of data quality control can lead to inaccurate or biased model results, causing poor decision-making and potential business losses.
Version control for data and models: Use version control systems like Git or DVC to track changes made to data and models, improving collaboration and reducing confusion among team members. For example, DVC can manage different versions of datasets and model experiments, allowing easy switching, sharing, and reproduction. With version control, teams can manage multiple iterations and reproduce past results for analysis.
Collaborative and reproducible workflows: Encourage collaboration by implementing clear documentation, code review processes, standardized data management, and collaborative tools and platforms like Jupyter Notebooks and Saturn Cloud. Supporting team members to work together efficiently and effectively helps accelerate the development of high-quality models. On the other hand, ignoring collaborative and reproducible workflows results in slower development, increased risk of errors, and hindered knowledge sharing.
Automated testing and validation: Adopt a rigorous testing strategy by integrating automated testing and validation techniques (e.g., unit tests with Pytest, integration tests) into your ML pipeline, leveraging continuous integration tools like GitHub Actions or Jenkins to test model functionality regularly.
Automated tests help identify and fix issues before deployment, ensuring a high-quality and reliable model performance in production. Skipping automated testing increases the risk of undetected problems, compromising model performance and ultimately hurting business outcomes.
Monitoring and alerting systems: Use tools like Amazon SageMaker Model Monitor, MLflow, or custom solutions to track key performance metrics and set up alerts to detect potential issues early. For example, configure alerts in MLflow when model drift is detected or specific performance thresholds are breached.
Not implementing monitoring and alerting systems delays the detection of problems like model drift or performance degradation, resulting in suboptimal decisions based on outdated or inaccurate model predictions, negatively affecting the overall business performance.
By adhering to these MLOps best practices, organizations can efficiently develop, deploy, and maintain ML models while minimizing potential issues and maximizing model effectiveness and overall business impact.
MLOps and data security
Data security plays a vital role in the successful implementation of MLOps. Organizations must take necessary precautions to guarantee that their data and models remain secure and protected at every stage of the ML lifecycle. Critical considerations for ensuring data security in MLOps include:
Model Robustness: Ensure your ML models can withstand adversarial attacks or perform reliably in noisy or unexpected conditions. For instance, you can incorporate techniques like adversarial training, which involves injecting adversarial examples into the training process to increase model resilience against malicious attacks.
Regularly evaluating model robustness helps prevent potential exploitation that could lead to incorrect predictions or system failures.
Data privacy and compliance: To safeguard sensitive data, organizations must adhere to relevant data privacy and compliance regulations, such as the General Data Protection Regulation (GDPR) or the Health Insurance Portability and Accountability Act (HIPAA). This may involve implementing robust data governance policies, anonymizing sensitive information, or utilizing techniques like data masking or pseudonymization.
Model security and integrity: Ensuring the security and integrity of ML models helps protect them from unauthorized access, tampering, or theft. Organizations can implement measures like encryption of model artifacts, secure storage, and model signing to validate authenticity, thereby minimizing the risk of compromise or manipulation by outside parties.
Secure deployment and access control: When deploying ML models to production environments, organizations must follow best practices for fast deployment. This includes identifying and fixing potential vulnerabilities, implementing secure communication channels (e.g., HTTPS or TLS), and enforcing strict access control mechanisms to restrict only model access to authorized users.
Organizations can prevent unauthorized access and maintain model security using role-based access control and authentication protocols like OAuth or SAML.
Involving security teams like red teams in the MLOps cycle can also significantly enhance overall system security. Red teams, for instance, can simulate adversarial attacks on models and infrastructure, helping identify vulnerabilities and weaknesses that might otherwise go unnoticed.
This proactive security approach enables organizations to address issues before they become threats, ensuring compliance with regulations and enhancing their ML solutions’ overall reliability and trustworthiness. Collaborating with dedicated security teams during the MLOps cycle fosters a robust security culture that ultimately contributes to the success of ML projects.
MLOps out in the industry
MLOps has been successfully implemented across various industries, driving significant improvements in efficiency, automation, and overall business performance. The following are real-world examples showcasing the potential and effectiveness of MLOps in different sectors:
CareSource is one of the largest Medicaid providers in the United States focusing on triaging high-risk pregnancies and partnering with medical providers to proactively provide lifesaving obstetrics care. However, some data bottlenecks needed to be solved. CareSource’s data was siloed in different systems and was not always up to date, which made it difficult to access and analyze. When it came to model training, data was not always in a consistent format, which made it difficult to clean and prepare for analysis.
To address these challenges, CareSource implemented an MLOps framework that uses Databricks Feature Store, MLflow, and Hyperopt to develop, tune, and track ML models to predict obstetrics risk. They then used Stacks to help instantiate a production-ready template for deployment and send prediction results at a timely schedule to medical partners.
The accelerated transition between ML development and production-ready deployment enabled CareSource to directly impact patients’ health and lives before it was too late. For example, CareSource identified high-risk pregnancies earlier, leading to better outcomes for mothers and babies. They also reduced the cost of care by preventing unnecessary hospitalizations.
Moody’s Analytics, a leader in financial modeling, encountered challenges such as limited access to tools and infrastructure, friction in model development and delivery, and knowledge silos across distributed teams. They developed and utilized ML models for various applications, including credit risk assessment and financial statement analysis. In response to these challenges, they implemented the Domino data science platform to streamline their end-to-end workflow and enable efficient collaboration among data scientists.
By leveraging Domino, Moody’s Analytics accelerated model development, reduced a nine-month project to four months, and significantly improved its model monitoring capabilities. This transformation allowed the company to efficiently develop and deliver customized, high-quality models for clients’ needs, like risk evaluation and financial analysis.
Netflix utilized Metaflow to streamline the development, deployment, and management of ML workloads for various applications, such as personalized content recommendations, optimizing streaming experiences, content demand forecasting, and sentiment analysis for social media engagement. By fostering efficient MLOps practices and tailoring a human-centric framework for their internal workflows, Netflix empowered its data scientists to experiment and iterate rapidly, leading to a more nimble and effective data science practice.
According to Ville Tuulos, a former manager of machine learning infrastructure at Netflix, implementing Metaflow reduced the average time from project idea to deployment from four months to just one week.
This accelerated workflow highlights the transformative impact of MLOps and dedicated ML infrastructure, enabling ML teams to operate more quickly and efficiently. By integrating machine learning into various aspects of their business, Netflix showcases the value and potential of MLOps practices to revolutionize industries and improve overall business operations, providing a substantial advantage to fast-paced companies.
MLOps lessons learned
As we’ve seen in the aforementioned cases, the successful implementation of MLOps showcased how effective MLOps practices can drive substantial improvements in different aspects of the business. Thanks to the lessons learned from real-world experiences like this, we can derive key insights into the importance of MLOps for organizations:
Standardization, unified APIs, and abstractions to simplify the ML lifecycle.
Integration of multiple ML tools into a single coherent framework to streamline processes and reduce complexity.
Addressing critical issues like reproducibility, versioning, and experiment tracking to improve efficiency and collaboration.
Developing a human-centric framework that caters to the specific needs of data scientists, reducing friction and fostering rapid experimentation and iteration.
Monitoring models in production and maintaining proper feedback loops to ensure models remain relevant, accurate, and effective.
The lessons from Netflix and other real-world MLOps implementations can provide valuable insights to organizations looking to enhance their own ML capabilities. They emphasize the importance of having a well-thought-out strategy and investing in robust MLOps practices to develop, deploy, and maintain high-quality ML models that drive value while scaling and adapting to evolving business needs.
Future trends and challenges in MLOps
As MLOps continues to evolve and mature, organizations must stay aware of the emerging trends and challenges they may face when implementing MLOps practices. A few notable trends and potential obstacles include:
Edge Computing: The rise of edge computing presents opportunities for organizations to deploy ML models on edge devices, enabling faster and localized decision-making, reducing latency, and lowering bandwidth costs. Implementing MLOps in edge computing environments requires new strategies for model training, deployment, and monitoring to account for limited device resources, security, and connectivity constraints.
Explainable AI: As AI systems play a more significant role in everyday processes and decision-making, organizations must ensure that their ML models are explainable, transparent, and unbiased. This requires integrating tools for model interpretability, visualization, and techniques to mitigate bias. Incorporating explainable and responsible AI principles into MLOps practices helps increase stakeholder trust, comply with regulatory requirements, and uphold ethical standards.
Sophisticated Monitoring and Alerting: As the complexity and scale of ML models increase, organizations may require more advanced monitoring and alerting systems to maintain adequate performance. Anomaly detection, real-time feedback, and adaptive alert thresholds are some of the techniques that can help quickly identify and diagnose issues like model drift, performance degradation, or data quality problems.
Integrating these advanced monitoring and alerting techniques into MLOps practices can ensure that organizations can proactively address issues as they arise and maintain consistently high levels of accuracy and reliability in their ML models.
Federated Learning: This approach enables training ML models on decentralized data sources while maintaining data privacy. Organizations can benefit from federated learning by implementing MLOps practices for distributed training and collaboration among multiple stakeholders without exposing sensitive data.
Human-in-the-loop Processes: There is a growing interest in incorporating human expertise in many ML applications, especially those that involve subjective decision-making or complex contexts that cannot be fully encoded. Integrating human-in-the-loop processes within MLOps workflows demands effective collaboration tools and strategies for seamlessly combining human and machine intelligence.
Quantum ML: Quantum computing is an emerging field that shows potential in solving complex problems and speeding up specific ML processes. As this technology matures, MLOps frameworks and tools may need to evolve to accommodate quantum-based ML models and handle new data management, training, and deployment challenges.
Robustness and Resilience: Ensuring the robustness and resilience of ML models in the face of adversarial circumstances, such as noisy inputs or malicious attacks, is a growing concern. Organizations will need to incorporate strategies and techniques for robust ML into their MLOps practices to guarantee the safety and stability of their models. This may involve adversarial training, input validation, or deploying monitoring systems to identify and alert when models encounter unexpected inputs or behaviors.
Conclusion
In today’s world, implementing MLOps has become crucial for organizations looking to unleash the full potential of ML, streamline workflows, and maintain high-performing models throughout their lifecycles. This article explores MLOps practices and tools, use cases across various industries, the importance of data security, and the opportunities and challenges ahead as the field continues to evolve.
To recap, we have discussed the following:
The stages of the MLOps lifecycle.
Popular open-source MLOps tools that can be deployed to your infrastructure of choice.
Best practices for MLOps implementations.
MLOps use cases in different industries and valuable MLOps lessons learned.
Future trends and challenges, such as edge computing, explainable and responsible AI, and human-in-the-loop processes.
As the landscape of MLOps keeps evolving, organizations and practitioners must stay up to date with the latest practices, tools, and research. Emphasizing continued learning and adaptation will enable businesses to stay ahead of the curve, refine their MLOps strategies, and effectively address emerging trends and challenges.
The dynamic nature of ML and the rapid pace of technology means that organizations must be prepared to iterate and evolve with their MLOps solutions. This entails adopting new techniques and tools, fostering a collaborative learning culture within the team, sharing knowledge, and seeking insights from the broader community.
Organizations that embrace MLOps best practices, maintain a strong focus on data security and ethical AI, and remain agile in response to emerging trends will be better positioned to maximize the value of their ML investments.
As businesses across industries leverage ML, MLOps will be increasingly vital in ensuring the successful, responsible, and sustainable deployment of AI-driven solutions. By adopting a robust and future-proof MLOps strategy, organizations can unlock the true potential of ML and drive transformative change in their respective fields.
Regularization in machine learning is a technique that is used to prevent over fitting in ML models. In this article, we’ll explore what overfitting is and how regularization works to mitigate it, as well as the different types of regularization techniques used in machine learning.
Before we dive into the concept of regularization in machine learning, it’s important to first understand the related concepts of OVERFITTING and UNDERFITTING. These concepts are crucial for building accurate and reliable machine-learning models. If you want to know about machine learning in a layman manner please visit the below link as well.
What is Overfitting?
In machine learning, models are trained on a set of data called the training set. The goal is to create a model that can accurately predict outcomes on new data, called the test set. However, sometimes a model may become too complex and start fitting the training data too closely, essentially memorizing the data instead of learning from it. This is called overfitting, and it can lead to poor performance on new data.
Regularization in machine learning – Source: Aiex.AI
What is Underfitting?
On the other hand, Underfitting occurs when a machine learning model is too simple to capture the complexity of the data it is trying to model. This can happen when the model is not trained for long enough, or when the training data is not diverse enough to capture all the variations in the data.
The ultimate goal of machine learning is to find the right balance between overfitting and underfitting, achieving a model that can generalize well to new data while still capturing the underlying patterns in the training data. This is known as achieving a “GENERALIZED” model.
How does regularization in machine learning work?
Regularization works by adding a penalty term to the loss function during training. The penalty term discourages the model from creating complex relationships between the input features and the output variable. Essentially, it encourages the model to choose simpler solutions that generalize better to new data. By doing so, regularization can help prevent overfitting.
L1 regularization, commonly referred to as Lasso regularization, is a regularization technique extensively utilized in machine learning. It introduces a penalty term into the model’s cost function that is directly proportional to the absolute value of its weights. Consequently, larger weights incur a higher penalty.
By promoting the reduction of non-zero weights, L1 regularization facilitates feature selection. This approach effectively simplifies the model by prioritizing significant features while eliminating irrelevant ones. Through penalizing large weights, the model is compelled to reduce their magnitudes, resulting in a less complex and more interpretable model. Ultimately, L1 regularization serves as a potent tool for enhancing the performance and interpretability of machine learning models.
Code snippet for L1 regularization using Python and scikit-learn:
One noteworthy advantage of L1 regularization is its ability to streamline the model by reducing the number of utilized features. This can lead to faster training and improved generalization performance. However, it is essential to acknowledge that L1 regularization may not universally suit all data types and models, and alternative regularization techniques such as L2 regularization may be more suitable in certain scenarios.
All in all, L1 regularization significantly contributes to improving model performance and interpretability, making it a valuable asset in the realm of data science.
2. Ridge regularization (L2)
L2 regularization, commonly referred to as Ridge regularization, is a highly effective approach that enhances the performance of machine learning models. It achieves this by incorporating a penalty term that is directly proportional to the square of the model’s weights. This encourages the model to minimize the weight magnitudes, thereby preventing excessive complexity. As a result, L2 regularization effectively addresses the issue of overfitting and significantly improves the model’s ability to generalize to unseen data.
Code snippet for L2 regularization using Python and scikit-learn:
Compared to L1 regularization, L2 regularization does not perform feature selection by reducing the number of non-zero weights. Instead, it shrinks all the weights towards zero by a constant factor, thus making the model less sensitive to small fluctuations in the data. This technique is particularly useful when dealing with high-dimensional data, where the number of features is much larger than the number of observations, as it helps to avoid overfitting and improve the model’s generalization performance.
Benefits of regularization
Regularization offers several advantages for machine learning models. Firstly, it effectively combats overfitting, allowing for better generalization on unseen data. This improves the model’s accuracy and enhances its practical applicability.
Secondly, regularization aids in simplifying the model, making it more comprehensible and interpretable. This aspect is particularly valuable in domains like healthcare and finance, where model decisions have significant implications.
Lastly, regularization mitigates the risk of biases in the model. By encouraging simpler solutions, it prevents the model from capturing spurious correlations in the data, which can lead to biased predictions.
Conclusion
In a nutshell, regularization in machine learning plays a crucial role in machine learning as it helps address overfitting issues and enhances model accuracy, simplicity, and interpretability. It achieves this by introducing a penalty term to the loss function during training, promoting the selection of simpler solutions that can generalize well to unseen data.
Among the various regularization techniques, L2 regularization is widely employed in practice. In summary, regularization is an invaluable asset for machine learning practitioners and is expected to gain further prominence as the field advances.
Machine Learning (ML) is a powerful tool that can be used to solve a wide variety of problems. However, building and deploying a machine-learning model is not a simple task. It requires a comprehensive understanding of the end-to-end machine learning lifecycle.
The development of a Machine Learning Model can be divided into three main stages:
Building your ML data pipeline: This stage involves gathering data, cleaning it, and preparing it for modeling.
Getting your ML model ready for action: This stage involves building and training a machine learning model using efficient machine learning algorithms.
Making sense of your ML model: This stage involves deploying the model into production and using it to make predictions.
Machine Learning Model Deployment
Building your ML data pipeline
The first step of crafting a Machine Learning Model is to develop a pipeline for gathering, cleaning, and preparing data. This pipeline should be designed to ensure that the data is of high quality and that it is ready for modeling.
The following steps are involved in pipeline development:
Gathering data: The first step is to gather the data that will be used to train the model. For data scrapping a variety of sources, such as online databases, sensor data, or social media.
Cleaning data: Once the data has been gathered, it needs to be cleaned. This involves removing any errors or inconsistencies in the data.
Exploratory data analysis (EDA): EDA is a process of exploring data to gain insights into its distribution, relationships, and patterns. This information can be used to inform the design of the model.
Model design: Once the data has been cleaned and explored, it is time to design the model. This involves choosing the right machine-learning algorithm and tuning the model’s hyperparameters.
Training and validation: The next step is to train the model on a subset of the data. Once the model has been trained, it can be evaluated on a holdout set of data to measure its performance.
Getting your machine learning model ready for action
Once the pipeline has been developed, the next step is to train the model. This involves using a machine learning algorithm to learn the relationship between the features and the target variable.
The following steps are involved in training:
Choosing a machine learning algorithm: There are many different machine learning algorithms available. The choice of algorithm will depend on the specific problem that is being solved.
Tuning hyperparameters: Hyperparameters are parameters that control the behavior of the machine learning algorithm. These parameters need to be tuned to achieve the best performance.
Training the model: Once the algorithm and hyperparameters have been chosen, the model can be trained on a dataset.
Evaluating the model: Once the model has been trained, it can be evaluated on a holdout set of data to measure its performance.
Making sense of ML model’s predictions
Once the model has been trained, it can be deployed into production and used to make predictions.
The following steps are involved in inference:
Deploying the model: The model can be deployed in a variety of ways, such as a web service, a mobile app, or a desktop application.
Making predictions: Once the model has been deployed, it can be used to make predictions on new data.
Monitoring the model: It is important to monitor the model’s performance in production to ensure that it is still performing as expected.
Conclusion
Developing a Machine Learning Model is a complex process, but it is essential for building and deploying successful machine-learning applications. By following the steps outlined in this blog, you can increase your chances of success.
Here are some additional tips for building and deploying machine-learning models:
Establish a strong baseline model. Before you deploy a machine learning model, it is important to have a baseline model that you can use to measure the performance of your deployed model.
Use a production-ready machine learning framework. There are a number of machine learning frameworks available, but not all of them are suitable for production deployment. When choosing a machine learning framework for production deployment, it is important to consider factors such as scalability, performance, and ease of maintenance.
Use a continuous integration and continuous delivery (CI/CD) pipeline. A CI/CD pipeline automates the process of building, testing, and deploying your machine-learning model. This can help to ensure that your model is always up-to-date and that it is deployed in a consistent and reliable manner.
Monitor your deployed model. Once your model is deployed, it is important to monitor its performance. This will help you to identify any problems with your model and to make necessary adjustments
Using visualizations to understand the insights better. With the help of the model many insights can be drawn, and they can be visualized using software like Power BI.
Learn how the synergy of AI and Machine Learning algorithms in paraphrasing tools is redefining communication through intelligent algorithms that enhance language expression.
Artificial intelligence or AI as it is commonly called is a vast field of study that deals with empowering computers to be “Intelligent”. This intelligence can manifest in different ways, but typically, it results in the automation of mundane tasks. However, the advancements in AI have led to automation in more sophisticated tasks as well.
One of the most common applications of AI in a sophisticated task is text processing and manipulation. Which is also our topic today. Specifically, the paraphrasing of text with the help of AI. The most revolutionary technology that enables this is called machine learning.
Machine learning algorithms
Machine learning is a subset of AI. So, when you say AI, it automatically includes machine learning as well. Now, we will take a look at how machine learning works in Paraphrasing tools.
Role of machine learning algorithms in paraphrasing tools
Machine learning by itself is also a vast field. There are a lot of ways in which a computer can process and manipulate text with machine learning algorithms.
You must have heard the name GPT if you are interested in text processing. GPT is one of the most popular machine-learning models used for text processing. It belongs to a class of models called “Transformers” which are classified among deep learning models.
And that was just one model. Transformers are the most popular when it comes to text processing and programmers have a lot of options to choose from. Many paraphrase generators nowadays utilize transformers in their back end for changing the given text.
Most paraphrasing tools that are powered by AI are developed using Python because Python has a lot of prebuilt libraries for NLP (natural language processing).
NLP is yet another application of machine learning algorithms. It allows computer systems to parse and understand text much in the same way a human would. So, let’s take a look at how a paraphrase generator works with these NLP libraries.We will check out a few different libraries and as such different transformers that are used nowadays for paraphrasing text.
1. Pegasus Transformer
This is a part of the Transformers library available in Python 3. You can download Pegasus using pip with simple instructions. Machine learning algorithms will transform our lives, from autonomous vehicles to personalized medicine.
Pegasus was originally created for summarizing, however, the good thing about machine learning is that models can be tuned to do different things. So even though Pegasus is for summarizing, it can still be used for paraphrasing.
Here’s how it works for paraphrasing.
The transformer is trained on a large database of text, such a database is called a “corpus”. This corpus contains sentence pairs and each pair includes an original sentence and its paraphrased version.By training on such a corpus, the transformer learns how different sentences mean the same thing. Then it can create new paraphrases of any given sentence, even the ones it did not train on.
2. T5 Transformer
T5 or text-to-text transfer transformer is a neural network architecture that can do a lot of things:
Summarizing
Translating
Question and answering
And of course, paraphrasing
A paraphrasing tool that uses the T5 transformer can give a variety of different results because it is trained on a massive amount of data. According to Google (the creators of T5), the T5 transformer was trained on Wikipedia, books, articles, and plenty of online web pages.
T5 uses unsupervised learning which means it’s not told what is what, and it is allowed to draw its own conclusions. While that gives it extreme flexibility, it also gives more room for making errors. That’s why always proofread any text you get from a paraphrasing tool as it could have mistakes.
3. Parrot Library
This particular library is not a transformer, but it uses similar techniques. It uses the same type of sequence-to-sequence architecture that is used in the T5 transformer.
Another similarity between the two is that Parrot is also trained on a corpus of sentence pairs where one sentence is original and the other is paraphrased. This allows it to find patterns and realize that different syntax can still have the same meaning.
Parrot uses a mix of supervised and unsupervised learning techniques. However, what sets Parrot apart from other models of paraphrasing is that it has two steps.
Step one creates a bunch of paraphrases for the given text. However, it does not finalize them right away.
Step 2 ranks the generated paraphrases and only selects the most highly ranked output. It uses a variety of factors to calculate rank and it is widely touted as one of the most accurate and fluent paraphrasing models available.
Conclusion
So, now you know something about how machine learning algorithms work in paraphrasing tools. These models are running on the server side of these tools, so the end user cannot see what is happening.
The tool forwards the input to the models, and they generate an output which is shown to the user. And that is the simplest description of paraphrasing with machine learning.
Machine learning courses are not just a buzzword anymore; they are reshaping the careers of many people who want their breakthrough in tech. From revolutionizing healthcare and finance to propelling us towards autonomous systems and intelligent robots, the transformative impact of machine learning knows no bounds.
Safe to say that the demand for skilled machine learning professionals is skyrocketing, and many are turning to online courses to upskill and stay competitive in the job market. Fortunately, there are many great resources available for those looking to dive into the world of machine learning.
If you are interested in learning more about machine learning courses, there are many free ones available online.
Machine learning courses
Top free machine learning courses
Here are 9 free machine learning courses from top universities that you can take online to upgrade your skills:
1. Machine Learning with TensorFlow by Google AI
This is a beginner-level course that teaches you the basics of machine learning using TensorFlow, a popular machine-learning library. The course covers topics such as linear regression, logistic regression, and decision trees.
2. Machine Learning for Absolute Beginners by Kirill Eremenko and Hadelin de Ponteves
This is another beginner-level course that teaches you the basics of machine learning using Python. The course covers topics such as supervised learning, unsupervised learning, and reinforcement learning.
3. Machine Learning with Python by Andrew Ng
This is an intermediate-level course that teaches you more advanced machine-learning concepts using Python. The course covers topics such as deep learning and reinforcement learning.
4. Machine Learning for Data Science by Carlos Guestrin
This is an intermediate-level course that teaches you how to use machine learning for data science tasks. The course covers topics such as data wrangling, feature engineering, and model selection.
5. Machine Learning for Natural Language Processing by Christopher Manning, Jurafsky and Schütze
This is an advanced-level course that teaches you how to use machine learning for natural language processing tasks. The course covers topics such as text classification, sentiment analysis, and machine translation.
6. Machine Learning for Computer Vision by Andrew Zisserman
This is an advanced-level course that teaches you how to use machine learning for computer vision tasks. The course covers topics such as image classification, object detection, and image segmentation.
7. Machine Learning for Robotics by Ken Goldberg
This is an advanced-level course that teaches you how to use machine learning for robotics tasks. The course covers topics such as motion planning, control, and perception.
8. Machine Learning: A Probabilistic Perspective by Kevin P. Murphy
This is a graduate-level course that teaches you machine learning from a probabilistic perspective. The course covers topics such as Bayesian inference and Markov chain Monte Carlo methods.
9. Deep Learning by Ian Goodfellow, Yoshua Bengio and Aaron Courville
This is a graduate-level course that teaches you deep learning. The course covers topics such as neural networks, convolutional neural networks, and recurrent neural networks.
Are you interested in machine learning, data science, and analytics? Take the first step by enrolling in our comprehensivedata science course.
Each course is carefully crafted and delivered by world-renowned experts, covering everything from the fundamentals to advanced techniques. Gain expertise in data analysis, deep learning, neural networks, and more. Step up your game and make accurate predictions based on vast datasets.
Decoding the popularity of ML among students and professional
Among the wave of high-paying tech jobs, there are several reasons for the growing interest in machine learning, including:
High Demand: As the world becomes more data-driven, the demand for professionals with expertise in machine learning has grown. Companies across all industries are looking for people who can leverage machine-learning techniques to solve complex problems and make data-driven decisions.
Career Opportunities: With the high demand for machine learning professionals comes a plethora of career opportunities. Jobs in the field of machine learning are high-paying, challenging, and provide room for growth and development.
Real-World Applications: Machine learning has numerous real-world applications, ranging from fraud detection and risk analysis to personalized advertising and natural language processing. As more people become aware of the practical applications of machine learning, their interest in learning more about the technology grows.
Advancements in Technology: With the advances in technology, access to machine learning tools has become easier than ever. There are numerous open-source machine-learning tools and libraries available that make it easy for anyone to get started with machine learning.
Intellectual Stimulation: Learning about machine learning can be an intellectually stimulating experience. Machine learning involves the study of complex algorithms and models that can make sense of large amounts of data.
Enroll yourself in these courses now
In conclusion, if you’re looking to improve your skills, taking advantage of these free machine learning courses from top universities is a great way to get started. By investing the time and effort required to complete these courses, you’ll be well on your way to building a successful career in this exciting and rapidly evolving field.
Machine learning practices are the guiding principles that transform raw data into powerful insights. By following best practices in algorithm selection, data preprocessing, model evaluation, and deployment, we unlock the true potential of machine learning and pave the way for innovation and success.
In this blog, we focus on machine learning practices—the essential steps that unlock the potential of this transformative technology. By adhering to best practices, such as selecting the right machine learning algorithms, gathering high-quality data, performing effective preprocessing, evaluating models, and deploying them strategically, we pave the path toward accurate and impactful results.
5 essential machine learning practices
Join us as we explore these key machine learning practices and uncover the secrets to optimizing machine-learning models for revolutionary advancements in diverse domains.
1. Choose the right algorithm
When choosing an algorithm, it is important to consider the following factors:
The type of problem you are trying to solve. Some algorithms are better suited for classification tasks, while others are better suited for regression tasks.
The amount of data you have. Some algorithms require a lot of data to train, while others can be trained with less data.
The desired accuracy. Some algorithms are more accurate than others
The computational resources you have available. Some algorithms are more computationally expensive than others.
Once you have considered these factors, you can start to narrow down your choices of algorithms. You can then read more about each algorithm and experiment with different algorithms to see which one works best for your problem.
2. Get enough data
Machine learning models are only as good as the data they are trained on. If you don’t have enough data, your models will not be able to learn effectively. It is important to collect as much data as possible that is relevant to your problem. The more data you have, the better your models will be.
There are a number of different ways to collect data for machine learning projects. Some common techniques include:
Web scraping: Web scraping is the process of extracting data from websites. This can be done using a variety of tools and techniques.
Social media: Social media platforms can be a great source of data for machine learning projects. This data can be used to train models for tasks such as sentiment analysis and topic modeling.
Sensor data: Sensor data can be used to train models for tasks such as object detection and anomaly detection. This data can be collected from a variety of sources, such as smartphones, wearable devices, and traffic cameras.
Machine learning practices for data scientists
3. Clean your data
Even if you have a lot of data, it is important to make sure that it is clean. This means removing any errors or outliers from your data. If your data is dirty, it will make it difficult for your models to learn effectively. There are a number of different ways to clean your data. Some common techniques include:
Identifying and removing errors: This can be done by looking for data that is missing, incorrect, or inconsistent.
Identifying and removing outliers: Outliers are data points that are significantly different from the rest of the data. They can be removed by identifying them and then removing them from the dataset.
Imputing missing values: Missing values can be imputed by filling them in with the mean, median, or mode of the other values in the column.
Transforming categorical data: Categorical data can be transformed into numerical data by using a process called one-hot encoding.
Once you have cleaned your data, you can then proceed to train your machine learning models.
4. Evaluate your models
Once you have trained your models, it is important to evaluate their performance. This can be done by using a holdout set of data that was not used to train the models. The holdout set can be used to measure the accuracy, precision, and recall of the models.
Accuracy: Accuracy is the percentage of data points that are correctly classified by the model.
Precision: Precision is the percentage of data points that are classified as positive that are actually positive.
Recall: Recall is the percentage of positive data points that are correctly classified as positive.
The ideal model would have high accuracy, precision, and recall. However, in practice, it is often necessary to trade-off between these three metrics. For example, a model with high accuracy may have low precision or recall.
Once you have evaluated your models, you can then choose the model that has the best performance. You can then deploy the model to production and use it to make predictions.
5. Deploy your models
Once you are satisfied with the performance of your models, it is time to deploy them. This means making them available to users so that they can use them to make predictions. There are many different ways to deploy machine learning models, such as through a web service or a mobile app.
Deploying your machine learning models is considered a good practice because it enables the practical utilization of your models by making them accessible to users. Also, it has the potential to reach a broader audience, maximizing its impact.
By making your models accessible, you enable a wider range of users to benefit from the predictive capabilities of machine learning, driving decision-making processes and generating valuable outcomes.
Popular machine-learning algorithms
Here are some of the most popular machine-learning algorithms:
Decision trees: Decision trees are a simple but effective algorithm for classification tasks. They work by dividing the data into smaller and smaller groups until each group can be classified with a high degree of accuracy.
Linear regression: Linear regression is a simple but effective algorithm for regression tasks. It works by finding a line that best fits the data.
Support vector machines: Support vector machines are a more complex algorithm that can be used for both classification and regression tasks. They work by finding a hyperplane that separates the data into two groups.
Neural networks: Neural networks are powerful but complex algorithms that can be used for a variety of tasks, including classification, regression, and natural language processing.
It is important to note that there are no single “best” machine learning practices or algorithms. The best algorithm for a particular problem will depend on the specific factors of that problem.
In a nutshell
Machine learning practices are essential for accurate and reliable results. Choose the right algorithm, gather quality data, clean and preprocess it, evaluate model performance, and deploy it effectively. These practices optimize algorithm selection, data quality, accuracy, decision-making, and practical utilization. By following these practices, you improve accuracy and solve real-world problems.
Drag and drop tools have revolutionized the way we approach machine learning (ML) workflows. Gone are the days of manually coding every step of the process – now, with drag-and-drop interfaces, streamlining your ML pipeline has become more accessible and efficient than ever before.
Machine learning is a powerful tool that helps organizations make informed decisions based on data. However, building and deploying machine learning models can be a complex and time-consuming process. This is where drag-and-drop tools come in. These tools provide a visual interface for building machine learning pipelines, making the process easier and more efficient for data scientists.
Below, we will cover the different components of a machine learning pipeline, including data inputs, preprocessing steps, and models, and how they can be easily connected using drag-and-drop tools. We will also examine the benefits of using these tools, including ease of use, improved accuracy, and faster deployment.
Enhance ML efficiency with drag and drop tools
What are drag and drop tools?
Drag and drop tools are user-friendly software that allows users to build machine learning pipelines by simply dragging and dropping components onto a canvas. These tools let users visualize the workflow and track the pipeline’s progress. The benefits of using drag-and-drop tools in machine learning pipelines include quick model development, improved accuracy, and improved productivity.
How do drag and drop tools work?
Drag and drop tools for machine learning pipelines work by providing a visual interface for building and managing the pipeline. The interface typically consists of a canvas on which components, such as data inputs, preprocessing steps, and models, are represented as blocks that can be dragged and dropped into place. The user can then easily connect these blocks to define the flow of the pipeline.
The process of building a machine learning pipeline with a drag-and-drop tool usually starts with selecting the data source. Once the data source is selected, the user can then add preprocessing steps to clean and prepare the data. The next step is to select the machine learning algorithm to be used for the model. Finally, the user can deploy the model and monitor its performance.
One of the main benefits of using drag-and-drop tools in machine learning pipelines is the ease of use. These tools are designed to be user-friendly and do not require any coding skills, making it easier for data scientists to build models quickly and efficiently.
Explore the top 10 machine learning demos and discover cutting-edge techniques that will take your skills to the next level.
Additionally, the visual representation of the pipeline provided by these tools makes it easier to identify potential errors and improve the accuracy of the models. In summary, drag-and-drop tools provide a visual and intuitive way to build and manage machine learning pipelines, making the process easier and more efficient for data scientists.
Popular drag and drop tools for ML pipeline
Here are some popular drag-and-drop tools for machine learning pipelines:
Drag and drop tools for streamlining your ML pipeline – Data Science Dojo
1. Data Robot
Data Robot is an automated machine learning platform that allows users to build, test, and deploy ML models with just a few clicks. It offers a wide range of pre-built models, which can be easily selected and configured using the drag-and-drop interface. Data Robot also provides visualizations and diagnostic tools to help users understand their models’ performance.
2. H2O.ai
H2O.ai is an open-source platform that provides drag-and-drop functionality for building ML pipelines. It offers a wide range of pre-built models, including deep learning and gradient boosting, that can be easily selected and configured using the drag-and-drop interface. H2O.ai also provides various visualizations and diagnostic tools to help users understand their models’ performance.
3. RapidMiner
RapidMiner is a data science platform that provides a drag-and-drop interface for building ML pipelines. It offers a wide range of pre-built models, including deep learning and gradient boosting, that can be easily selected and configured using the drag-and-drop interface. RapidMiner also provides a variety of visualizations and diagnostic tools to help users understand their models’ performance.
4. KNIME
KNIME is an open-source platform that provides drag-and-drop functionality for building ML pipelines. It offers a wide range of pre-built models, including deep learning and gradient boosting, that can be easily selected and configured using the drag-and-drop interface. KNIME also provides a variety of visualizations and diagnostic tools to help users understand their models’ performance.
5. Azure ML
Azure ML Designer is a visual interface in Microsoft Azure Machine Learning Studio that allows data scientists and developers to create and deploy machine learning models without having to write code. It provides a drag-and-drop interface for building workflows that include data preparation, feature engineering, model training, and deployment. Azure ML Designer supports popular machine learning algorithms and libraries and allows users to easily track experiments, monitor model performance, and collaborate with other team members.
Case Studies: Success stories of using drag and drop tools
There are numerous success stories of organizations using drag-and-drop tools to improve their machine-learning pipelines. These success stories range from improved accuracy to increased productivity. For instance, one company could build and deploy models in a fraction of the time it took them before, while another company could improve its accuracy. These case studies provide valuable insights into the real-life benefits of using drag-and-drop tools in machine learning pipelines.
Comparison of drag and drop tools for ML pipelines
When evaluating drag-and-drop tools for machine learning pipelines, it is important to consider factors such as features, user experience, and cost. A comparison of these factors can help organizations figure out which tool is the best fit for their needs. Some of the popular drag-and-drop tools in the market include Alteryx, Knime, and DataRobot.
Benefits of drag and drop tools for ML Pipelines
Easy to use: These tools are very user-friendly, as they allow users to create pipelines without writing code. This makes it easier for non-technical users to get involved in the machine learning process and speeds up development for technical users.
Faster Development: By using drag and drop tools, users can quickly and easily create pipelines, which speeds up the development process. This is especially important for machine learning projects, where the iterative process of testing and adjusting models is critical to success.
Improved Collaboration: Drag and Drop tools make it easier for teams to collaborate on machine learning projects. With visual pipelines, it is easier for team members to understand each other’s work and make changes together.
Better Model Management: Drag and Drop Tools provide a visual representation of pipelines, which makes it easier to manage and maintain machine learning models. This helps to ensure that models are consistent, accurate, and up-to-date.
Conclusion
In conclusion, drag-and-drop tools for machine learning pipelines supply a simple and intuitive way for data scientists to build, manage, and deploy models. These tools offer many benefits, including quick model development, improved accuracy, and improved productivity. When evaluating drag-and-drop tools, it is important to consider factors such as features, user experience, and cost. With the growing popularity of drag-and-drop tools, organizations can expect to see a continued improvement in their machine learning pipelines.