面向开发者的 NVIDIA NeMo Curator
NVIDIA NeMo™Curator 通过大规模处理用于训练和定制的文本、图像和视频数据,提高生成式 AI 模型的准确性。它还提供用于生成合成数据的预构建流程,以定制和评估生成式 AI 系统。
借助 NeMo Curator,开发者可以为金融、零售、电信、汽车 (AV) 和机器人等各行各业整理高质量数据并训练高度准确的生成式 AI 模型。NeMo Curator 是 NVIDIA Cosmos 平台的一部分,提供用于构建或定制世界基础模型 (WFM) 的视频处理流程。
NVIDIA NeMo Curator 的工作原理
NeMo Curator 可将数据下载、提取、清理、质量过滤、重复数据删除、混合或混洗等数据处理任务简化为 Pythonic API,使开发者能够更轻松地构建数据处理流程。通过 NeMo Curator 处理的高质量数据,您可以使用更少的数据实现更高的准确性,并加快模型收速度,从而减少训练时间。
NeMo Curator 支持文本、图像和视频模式的处理,并且可以将数据扩展至 100 PB 以上。
NeMo Curator 提供可定制的模块化界面,允许您为数据处理流程选择构建块。请参阅下方的架构图,了解如何构建数据处理工作流。
文本数据管护
此架构图展示了可用于处理文本的各种功能。总体而言,典型的文本处理工作流首先从公共来源或私有存储库下载数据,然后执行清理步骤,例如修复 Unicode 字符。接下来,应用启发式过滤器 (例如词数统计),然后使用分类器模型质量和领域,最后是数据混合。

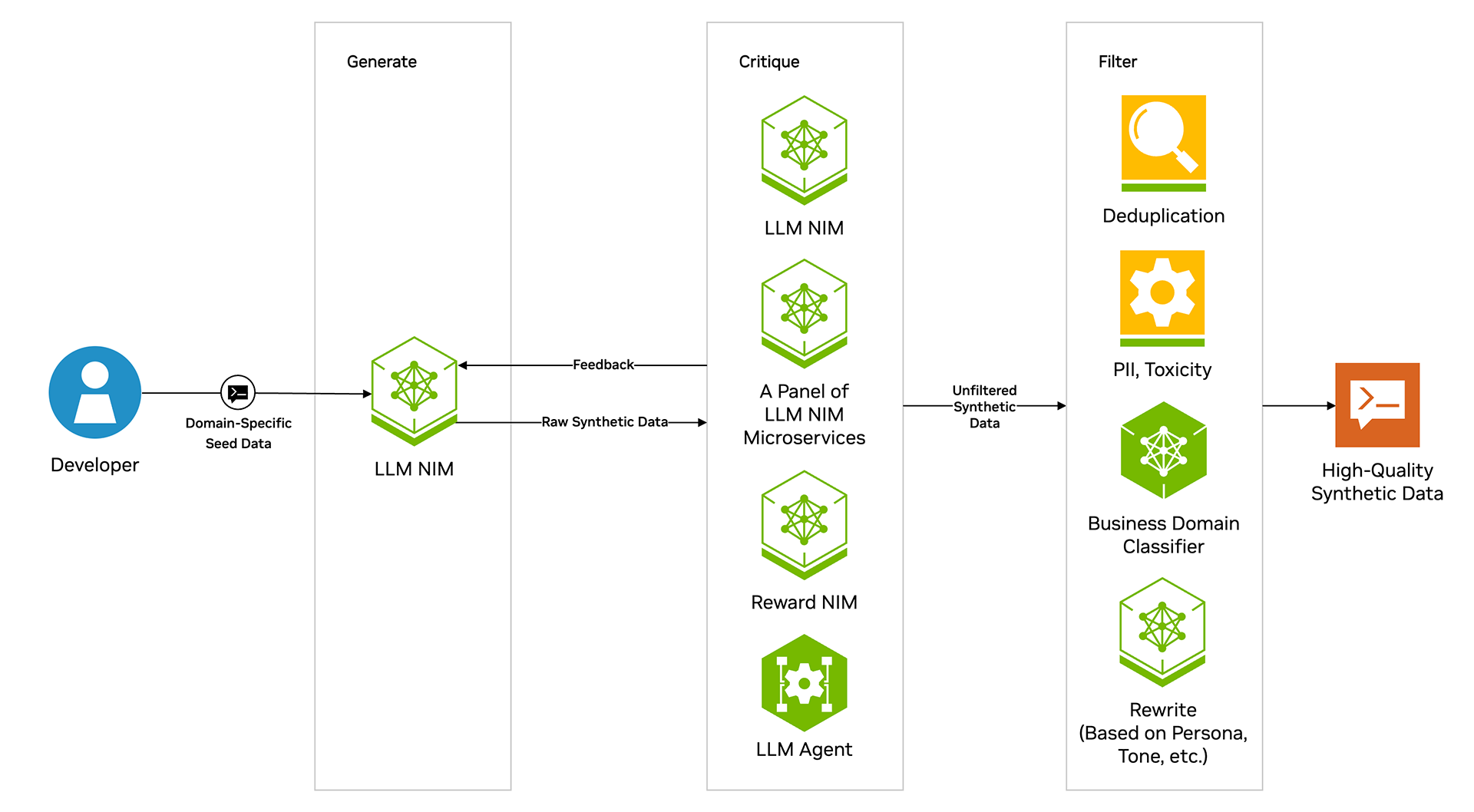
合成数据生成
NeMo Curator 提供了一套简单易用的工具,可让您使用预构建工具合成数据生成管道或构建自己的管道。任何使用 OpenAI API 的模型推理服务都与合成数据生成模块兼容,允许您从任何模型生成数据。
NeMo Curator 提供适用于多个用例的预构建工作流,帮助您轻松入门,包括提示生成 (开放式问答、封闭式问答、编写、数学/编码)、合成两回合提示生成、对话生成和实体分类。
视频数据处理
此架构图展示了抢先体验计划用于处理高质量视频的各种功能。通过 Cosmos 平台,可以使用过滤后的视频来训练或微调 WFM。
典型的管道包含以下步骤
- 视频解码和分割:对长视频进行解码,并将其拆分成语义更短的视频片段。
转码:将所有短视频转换为一致的格式。
添加说明:使用特定领域的先进视觉语言模型 (VLM) 来描述视频片段的说明。
- 文本嵌入:为下游语义搜索和重复数据消除创建文本描述的嵌入。


图像数据处理
此架构图展示了可用于处理图像的各种功能。
典型的工作流首先需要下载 WebDataset 格式的数据集,然后创建 CLIP 嵌入。接下来,使用 NSFW 和 Aesthetic 滤镜对图像进行高质量过滤。然后,使用语义重复数据删除重复图像,最后创建高质量数据集。
入门资源
开始使用 NVIDIA NeMo Curator 的方法
使用合适的工具和技术为 LLM 训练生成高质量数据集。
下载
对于希望使用 NeMo 框架进行开发的用户,可在 NGC 目录上免费下载该容器。您还可以申请免费许可证 NVIDIA AI Enterprise 使用现有基础架构在生产环境中运行 90 天。
拉取容器申请 90 天许可证性能
NeMo Curator 利用 cuDF、cuML 和 cuGraph 等 NVIDIA RAPIDS™ 库以及 Dask,在多节点、多 GPU 环境中扩展工作负载,从而大幅缩短数据处理时间。对于视频处理,它结合使用硬件解码器 (NVDEC) 和硬件编码器 (NVENC) 以及 Ray 来避免瓶颈并确保高性能。与替代方案相比,借助 NeMo Curator,开发者可以将文本处理速度提高 16 倍,将视频处理速度提高 89 倍。请参阅以下图表,了解更多详情。
使用 NeMo Curator 将视频处理速度从几年缩短到几天
2000 万小时视频的处理时间
.svg)
借助 NeMo Curator,文本处理速度提高 16 倍
RedPajama-v2 子集的模糊复制处理时间 (8 TB)

“关闭”:使用领先的备用库在 CPU 上处理的数据
入门套件
通过访问以下资源教程,最佳实践和文档各种用例,开始使用 NeMo Curator 开发您的生成式 AI 应用。
文本处理
利用重复数据消除、质量过滤和合成数据生成等功能处理高质量文本数据。
NVIDIA NeMo Curator 学习库
更多资源


合乎道德的 AI
NVIDIA 的平台和应用框架使开发者能够构建各种 AI 应用。选择或创建所部署的模型时,请考虑潜在的算法偏差。与模型的开发者合作,确保模型满足相关行业和用例的要求;提供必要的说明和文档以了解错误率、置信区间和结果;并确保模型的使用条件和方式符合预期。
及时了解 NVIDIA 发布的生成式 AI 新动态。