Innovation in medical devices continues to accelerate, with a record number authorized by the FDA every year. When these new or updated devices are introduced to clinicians and patients, they require training to use them properly and safely.
Once in use, clinicians or patients may need help troubleshooting issues. Medical devices are often accompanied by lengthy and technically complex Instructions for Use (IFU) manuals, which describe the correct use of the device. It can be difficult to find the right information quickly and training on a new device is a time-consuming task. Medical device representatives often provide support training, but may not be present to answer all questions in real time. These issues can cause delays in using medical devices and adopting newer technologies, and in some cases, lead to incorrect usage.
Using generative AI for troubleshooting medical devices
Retrieval-augmented generation (RAG) uses deep learning models, including large language models (LLMs), for efficient search and retrieval of information using natural language. Using RAG, users can receive easy-to-understand instructions for specific questions in a large text corpus, such as in an IFU. Speech AI models, such as automatic speech recognition (ASR) and text-to-speech (TTS) models, enable users to communicate with these advanced generative AI workflows using their voice, which is important in sterile environments like the operating room.
NVIDIA NIM inference microservices are GPU-optimized and highly performant containers for these models that provide the lowest total cost of ownership and the best inference optimization for the latest models. By integrating RAG and speech AI with the efficiency and simplicity of deploying NIM microservices, companies developing advanced medical devices can provide clinicians with accurate, hands-free answers in real time.
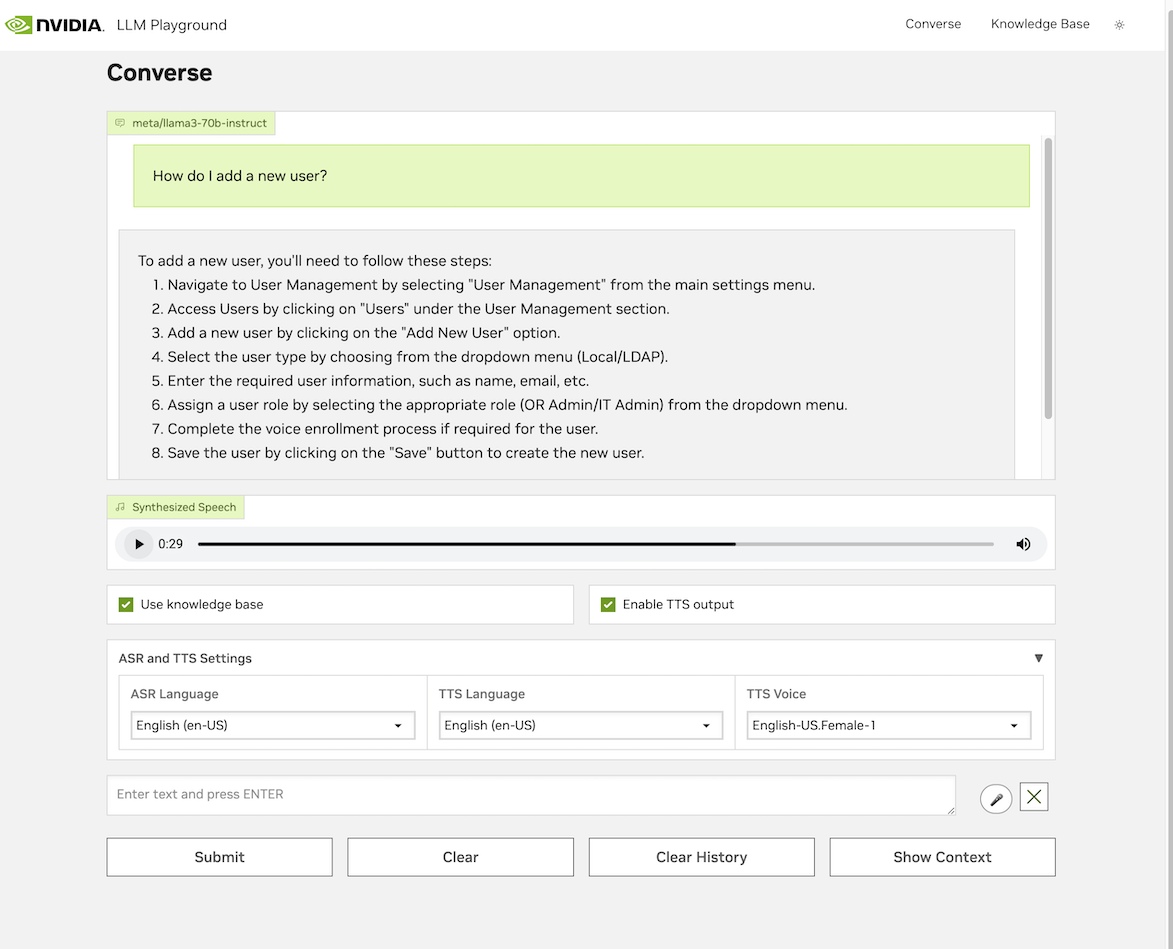
Figure 1. The chatbot user interface of the medical device training assistant
A medical device training assistant built with NIM microservices
In this tutorial, we build a RAG pipeline with optional speech capabilities to answer questions about a medical device using its IFU. The code used is available on GitHub.
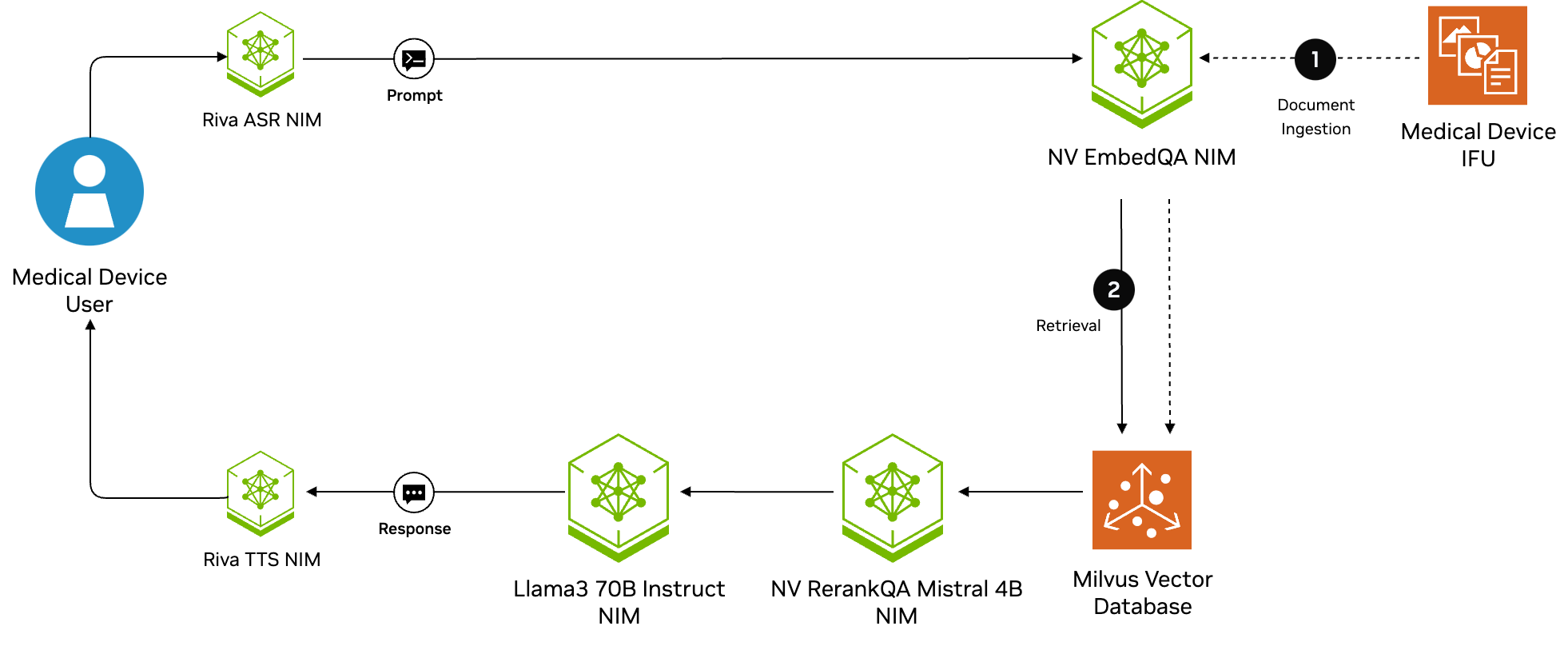
We use the following NIM microservices in our RAG pipeline. You have the flexibility to change the components in the pipeline to other NIM microservices for different models:
- Llama3 70B Instruct (meta/llama3-70b-instruct): A large language model that generates the answer to the user question based on the retrieved text.
- NV-EmbedQA-e5-v5 (nvidia/nv-embedqa-e5-v5): An embedding model that embeds the text chunks from the IFU and the queries from the user.
- NV-RerankQA-Mistral-4b-v3 (nvidia/nv-rerankqa/mistral-4b-v3): A reranking model that reranks the retrieved text chunks for the text generation step by the LLM.
- RIVA ASR: An automatic speech recognition model that transcribes the user’s speech query into text for the model.
- RIVA TTS: The text-to-speech model that outputs the audio of the response from the LLM.
RAG has two steps: document ingestion, then retrieval and generation of answers. These steps and the associated NIM microservices can be found in the reference architecture diagram in Figure 2.
Using NVIDIA NIM
You can access NIM microservices by signing up for free API credits on the API Catalog at build.nvidia.com or by deploying on your own compute infrastructure.
In this tutorial, we use the API Catalog endpoints. More information on using NIM microservices, finding your API key, and other prerequisites can be found on GitHub.
Follow these steps to build a RAG pipeline with optional speech for answering medical device questions using its IFU.
- Build and start the containers
See the docker compose files we’ve created to launch the containers with the NIM microservices and vector database. Detailed instructions and code can be accessed on GitHub. - Ingest the device manual
Navigate your browser to upload your IFU in the “Knowledge Base” tab as shown in Figure 3.
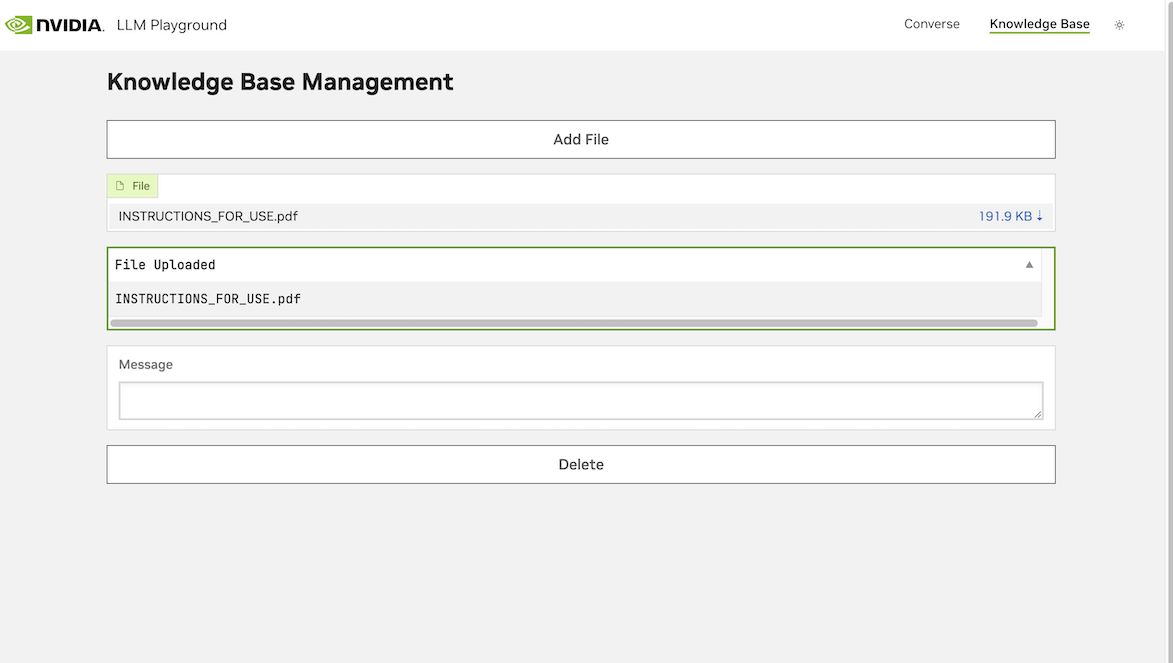
- Retrieve and generate answers
Navigate to the “Converse” tab to begin the conversation with the IFU (Figure 1). Make sure to click “Use Knowledge Base” to use the IFU as a knowledge resource.
To use speech to converse, click the microphone next to the text input area, and the RIVA ASR model will transcribe your question. To receive speech as an output, click the “Enable TTS output”. More information about using and troubleshooting the UI is on the GitHub documentation. - Evaluate on a custom dataset
Evaluate the performance of the RAG pipeline using a custom dataset of questions and automated RAGAS metrics. RAGAS metrics evaluate the performance of both the retriever and generator and are a common method for evaluating RAG pipelines in an automated fashion. Instructions on how to use the evaluation script are on GitHub.
Getting started
To get started with this workflow, visit the GenerativeAIExamples GitHub repository, which contains all of the code used in this tutorial as well as extensive documentation.
For more information on NIM microservices, you can learn more from the official NIM documentation and ask questions on our NVIDIA Developer NIM Forum.