
AMD's Strix Point "Ryzen AI 9 365" Zen 5 APU has reportedly been tested by David Huang, who has an in-depth analysis of the IPC, latency & performance.
AMD Ryzen AI 9 365 "Strix Point" APU Gets Tested In A Multitude of Benchmarks Ahead of Launch, Zen 5's IPC, Throughput, Latency & More Detailed
Note - David Huang's blog states that the numbers mentioned here are based on an engineering sample of the AMD Strix Point APU, mainly the Ryzen AI 9 365, so take these with a grain of salt as these may not be representative of the final product. He also explicitly states that the test system was running unofficial system firmware/software.
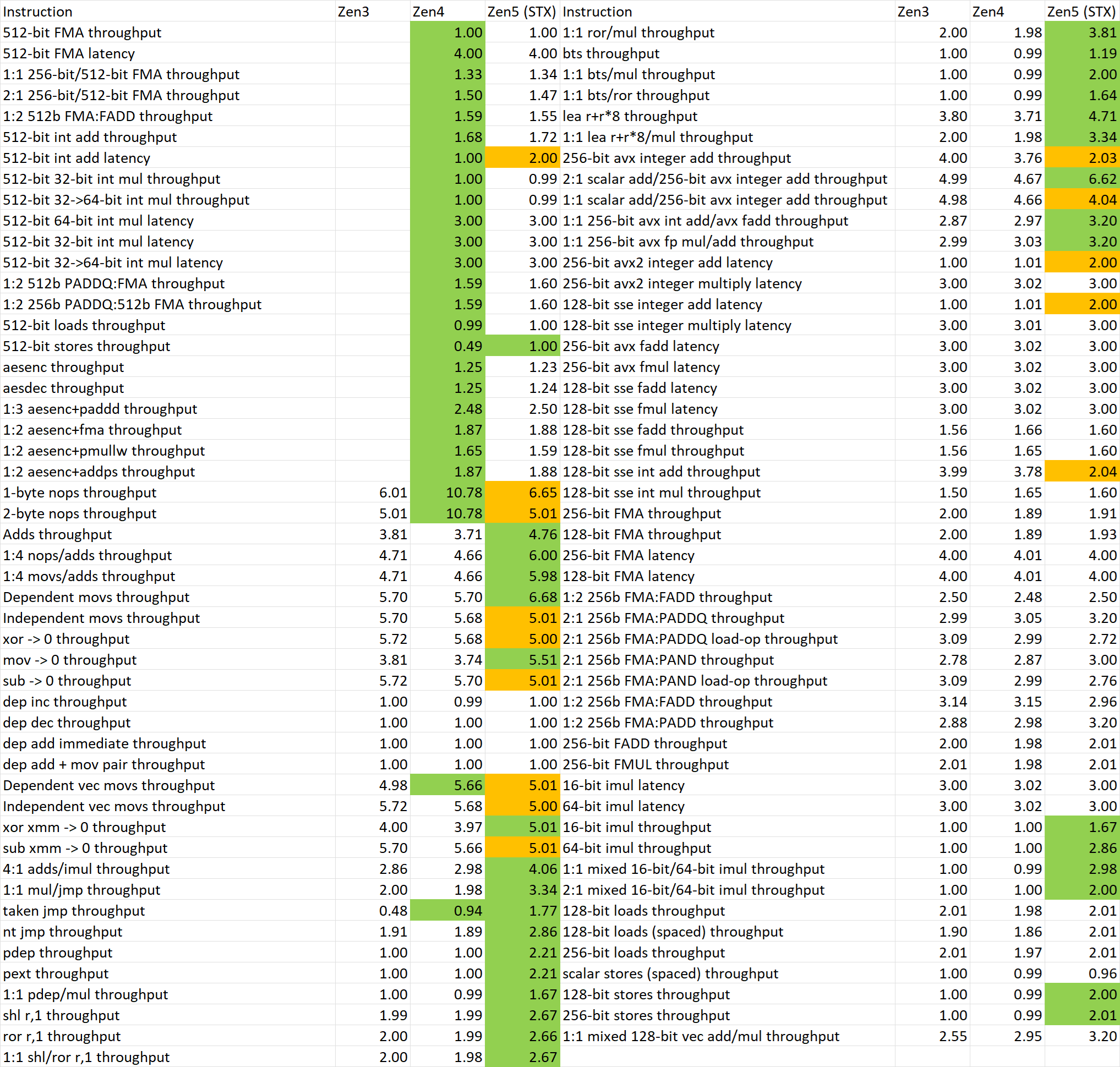
To start, David got access to an early AMD Strix Point laptop which reportedly features the Ryzen AI 9 365 SKU. The test platform made use of LPDDR5x-7500 memory in 32 GB capacities. The primary focus of today's test is on the IPC and Throughput which starts with the InstructionRate Tool to measure the instruction throughput/latency of three generations of Zen CPUs including the Zen 3, Zen 4, and Zen 5 architectures.
David lists that while Zen 5 has improvements thanks to its ground-up design, the architecture also has a few downsides which are as below:
- The throughput of various scalar ALU instructions has been greatly increased, but because the number of vector units in the mobile Zen 5 is halved compared to desktop and server, the SIMD throughput in this test remains unchanged compared to Zen 4. Even on the Zen 5 core with halved vector units, SIMD store operations of all widths are still doubled compared to the previous generation, and the SIMD load store throughput reaches 1:1;
- The branch processing capability has been greatly enhanced, with the number of non-taken branches that can be processed per cycle increased from two to three, and two taken branches can be processed per cycle. This should be related to the new front-end design;
- The latency of 128/256/512bit SSE/AVX/AVX512 SIMD integer addition calculations has all been increased to 2 cycles. This change may be to make it easier to maintain high frequencies.
- The throughput of 128/256bit SIMD integer addition operations is halved compared to Zen 4, but 512bit remains unchanged. It is speculated that this problem only exists on Zen 5 cores with halved SIMD, which may be related to port allocation;
- Removed the nop fusion feature introduced in Zen 4. It is no longer possible to merge a nop instruction with another instruction on the same macro-op;
- Adjusted the throughput of some logical register operations, unifying the throughput of some mov operations and some register zeroing operations to 5, which is a mixed improvement compared to Zen 4.
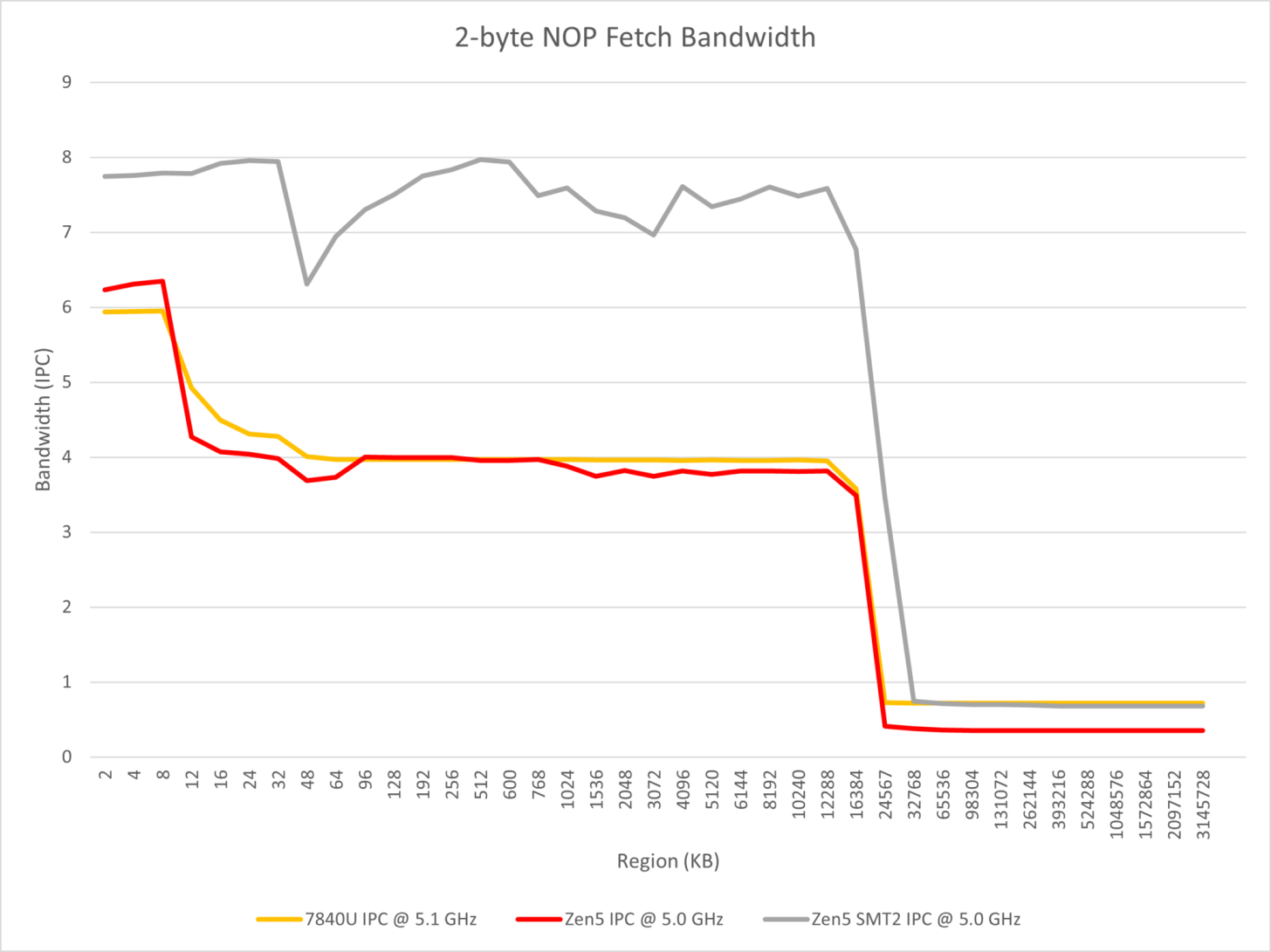
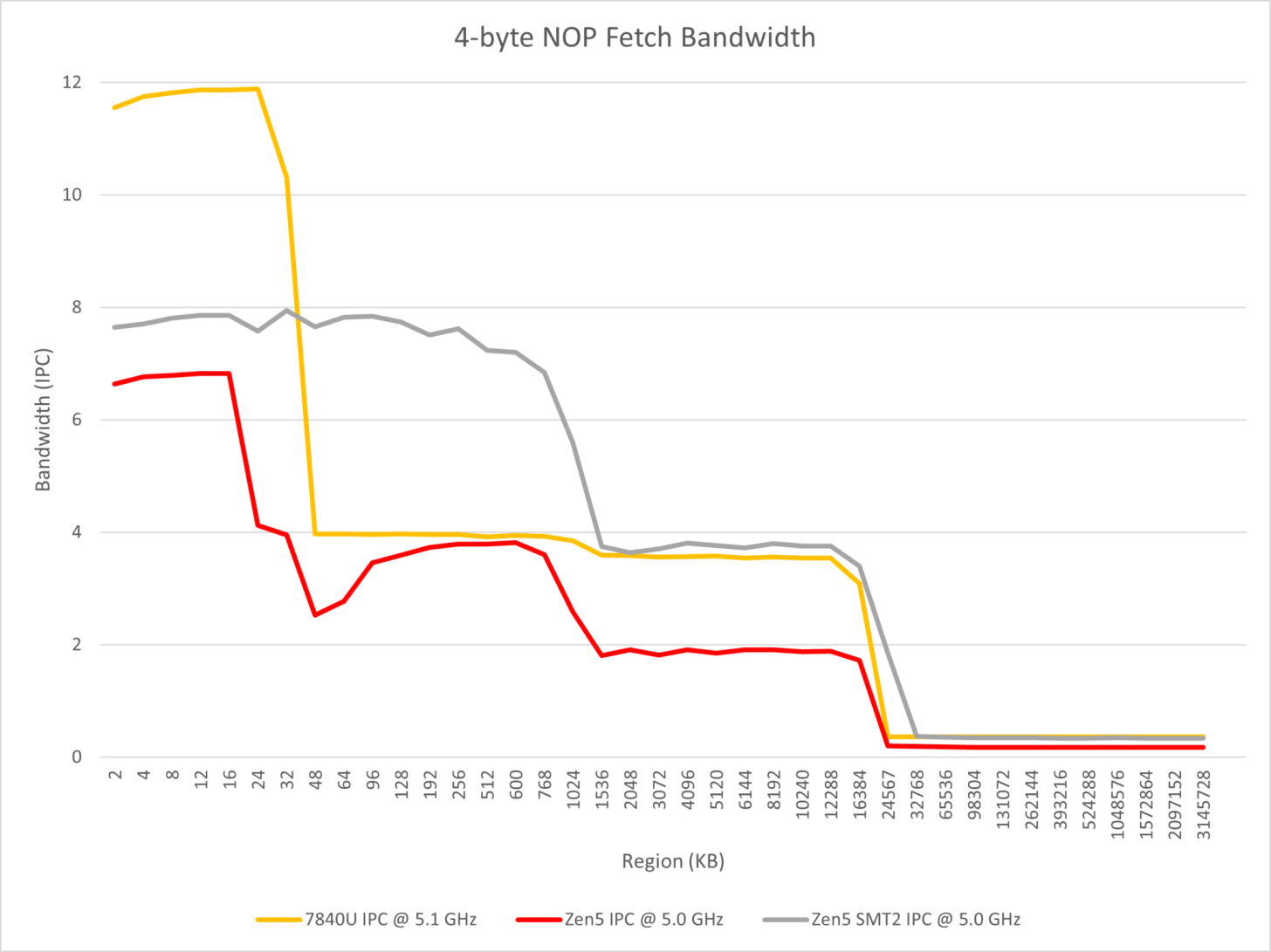
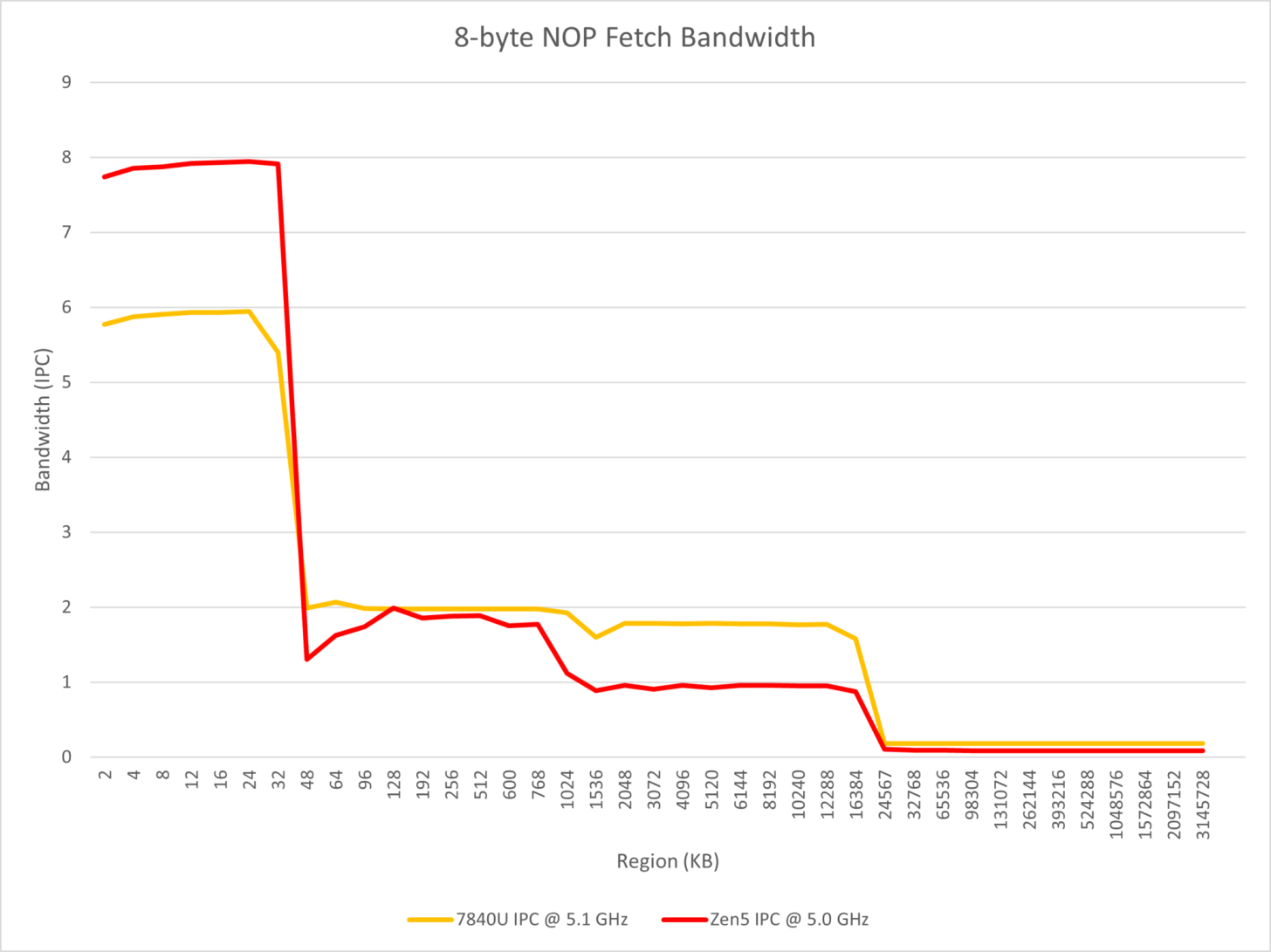
The tests also focus on the Parallel dual pipe front-end which should affect the instruction fetch, decoding, and macro-op cache. It is stated that by running NOP instructions of different lengths & numbers, the differences between Zen 4 and Zen 5 can be observed. The observations conclude as the following:
- Zen 5 uses a multi-front-end design similar to Tremont but wider, using two 4-wide x86 decoders and at least 8-wide macro-op caches to implement 8-wide renames;
- Consider the following phenomenon
- Zen 5 cannot make the x86 decode bandwidth exceed 4 when running consecutive NOP instructions in a single thread;
- In the instruction throughput section, it was tested that two taken branches can be processed in a single cycle;
- It is reasonable to speculate that Zen 5 does not use a pre-decode ILD cache solution similar to Gracemont, but must allow two decoders to work simultaneously when the branch predictor predicts a taken branch, that is, directly let one of the decoders start decoding from the next branch target address. From this perspective, AMD still needs to rely on macro-op cache to achieve high throughput in scenarios with sparse branches.
- Zen 5 not only supports decoding x86 instructions from two locations in the same cycle, but also supports fetching instructions from two locations in the macro-op cache in the same cycle, to achieve two taken branches per cycle within the coverage of the macro-op cache;
- When the core runs two SMT threads, each can monopolize a decoder so that the x86 decoding throughput limit of the entire core reaches 8 in most cases.
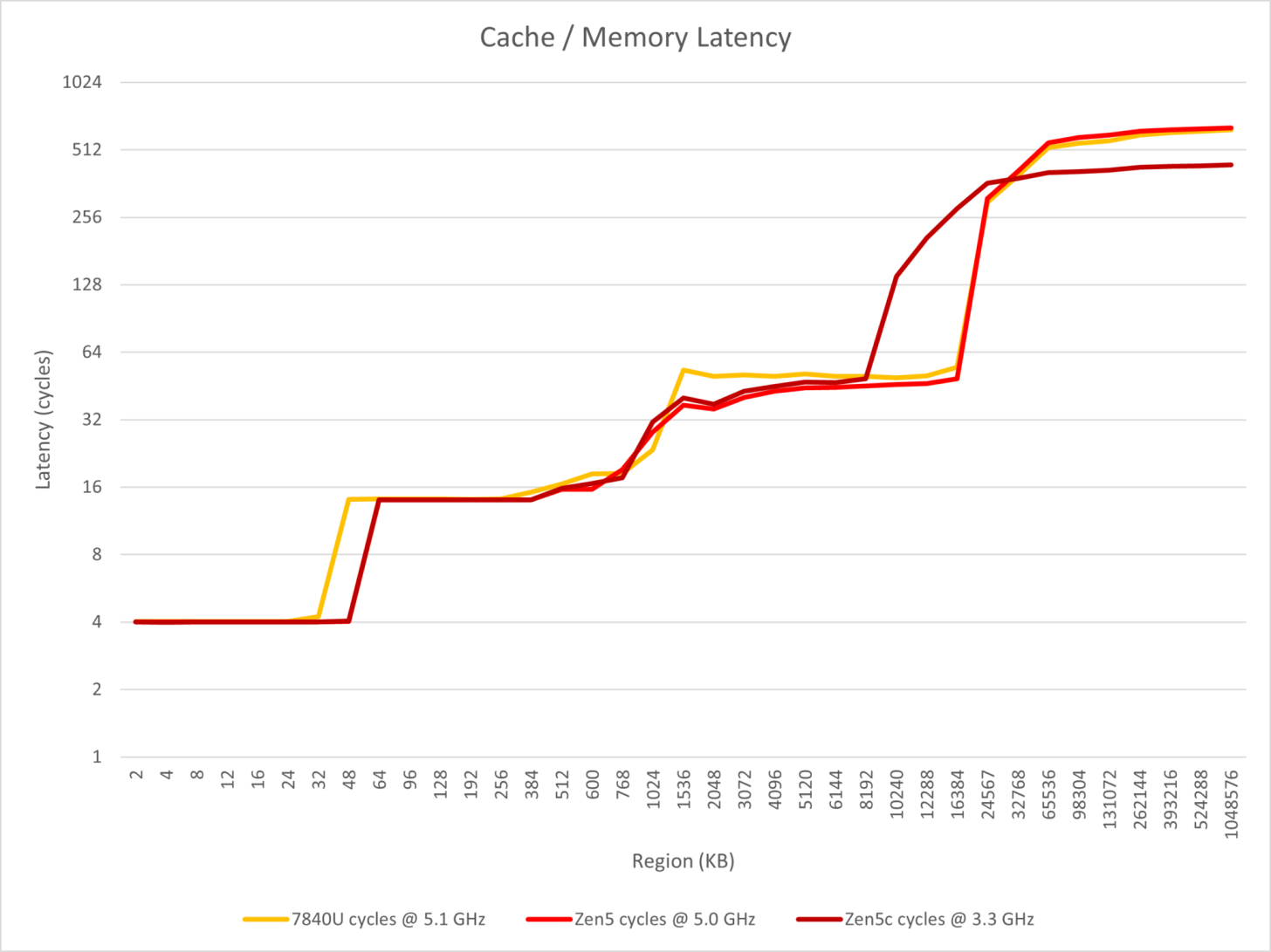
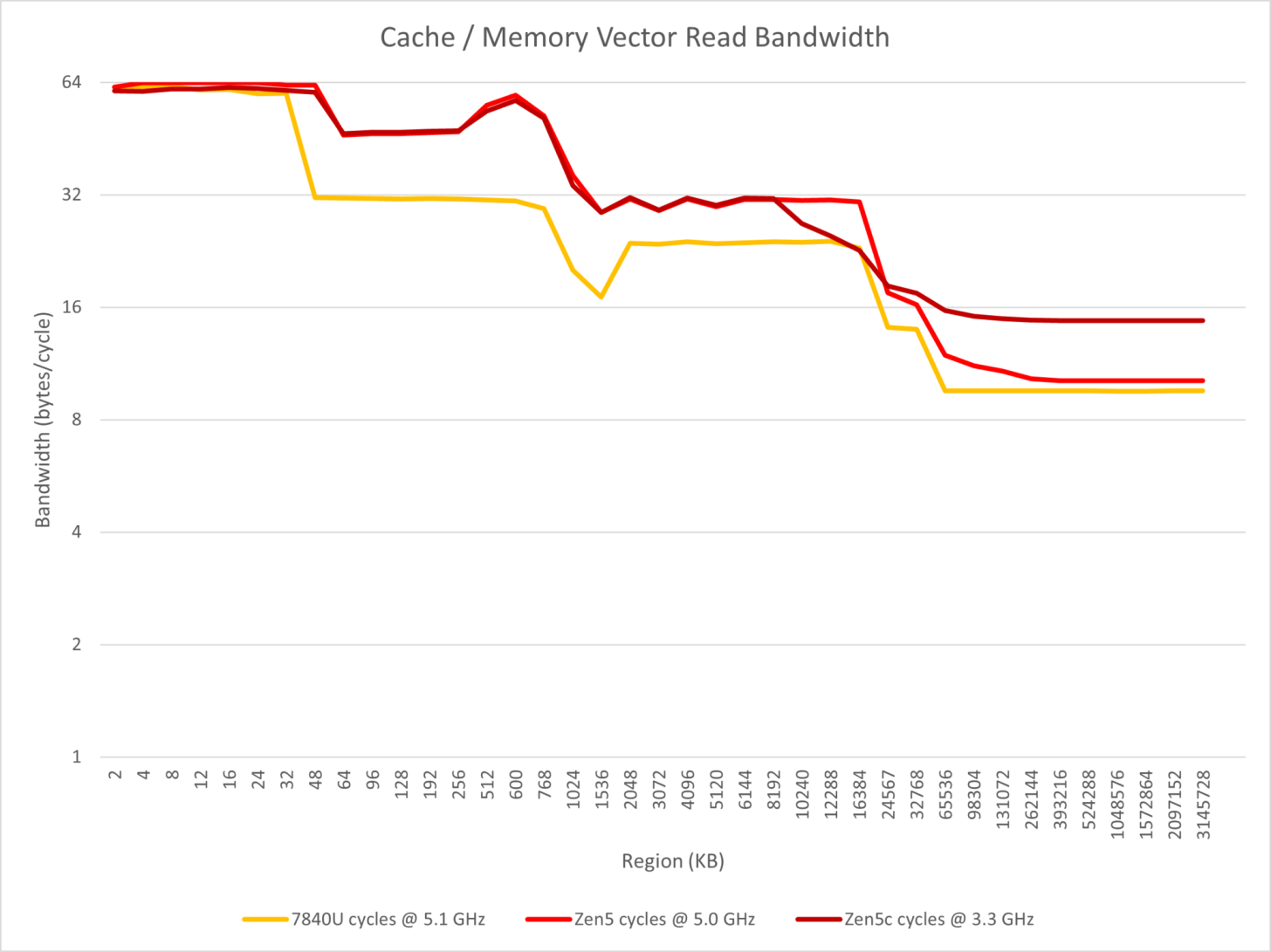
The tests then proceed to the more performance aspects of the AMD Strix Point APUs. Once again, the Ryzen AI 9 365 chip is used but this time, it is put up against the Ryzen 7 7735U (Zen 3), Ryzen 7 7840U (Zen 4), and the aforementioned Ryzen AI 9 365 (Zen 5), but this time both the Zen 5 & Zen 5C cores available on the chip being tested. The Zen 5C cores run at a much lower clock of just 3.30 GHz while the Zen 5 cores and the other two chips are set at a fixed clock rate of 4.8 GHz.
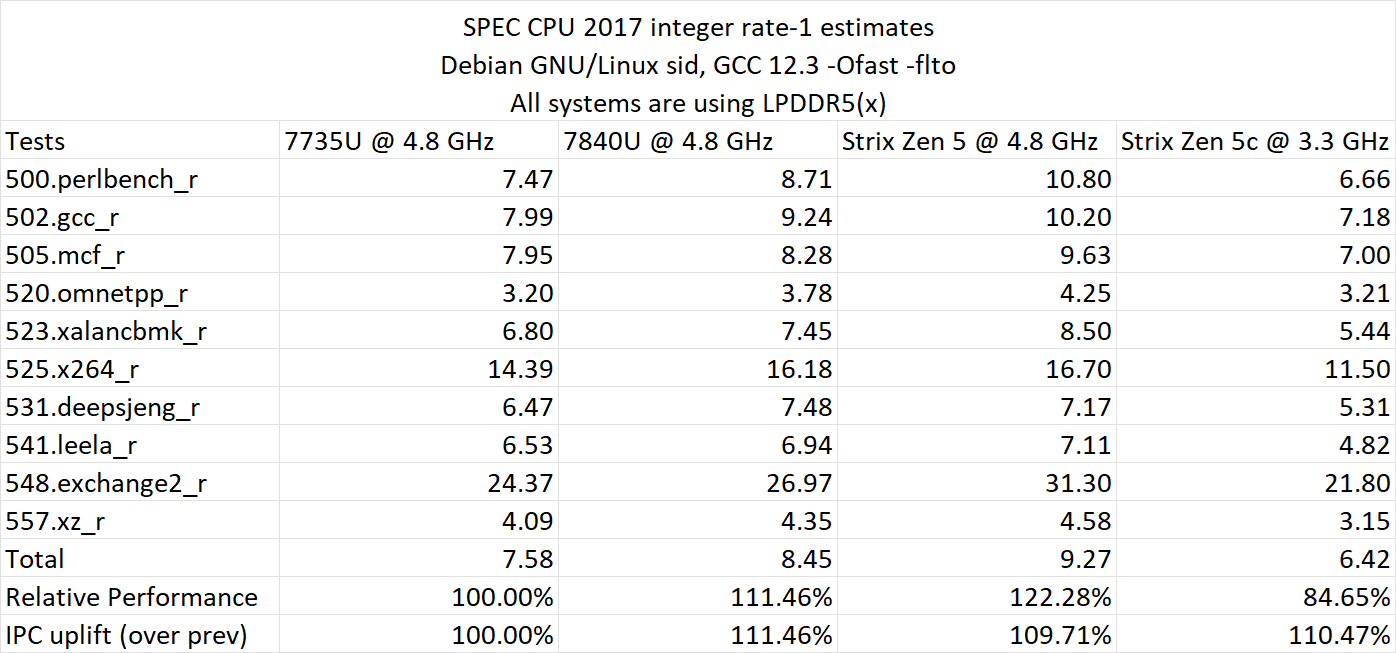
Performance was evaluated within SPEC CPU 2017 and Geekbench 6 (single-core and multi-core). In SPEC CPU 2017, the AMD Zen 5 chip sees a +9.71% uplift over the Zen 4 offering and a 22.28% uplift over the Zen 3 offering. The Zen 5C cores almost match Zen 4 IPC at a lower clock.
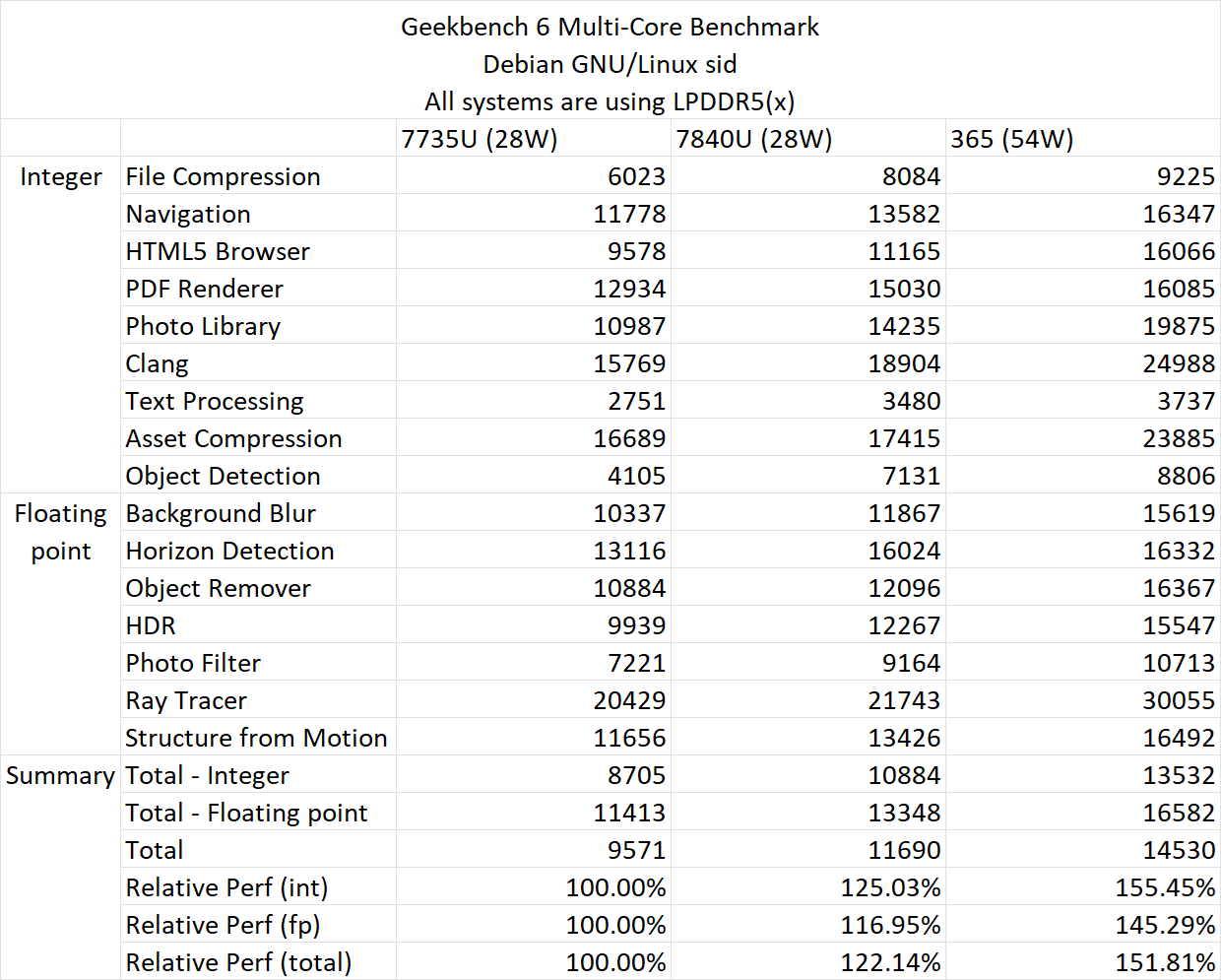
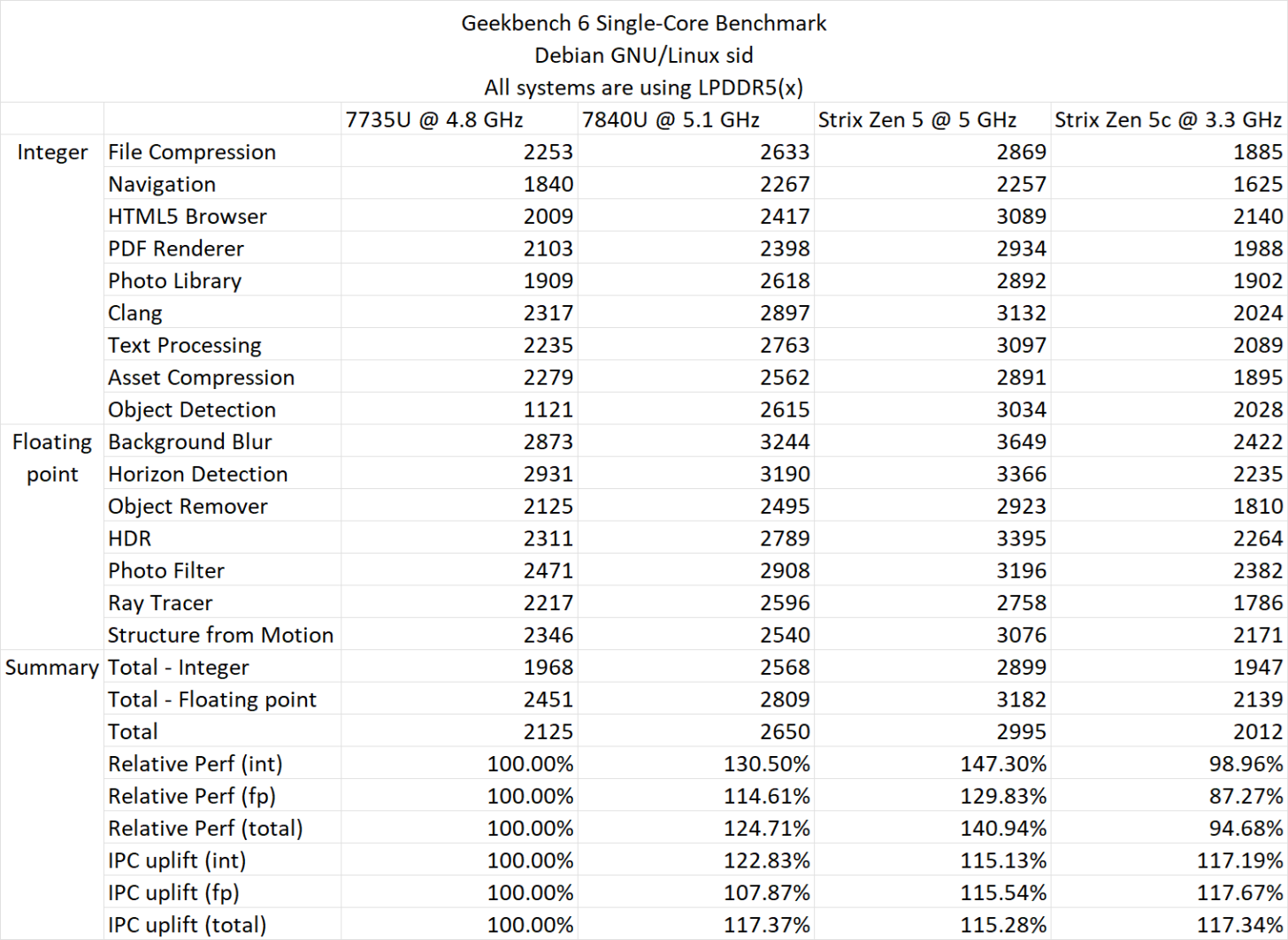
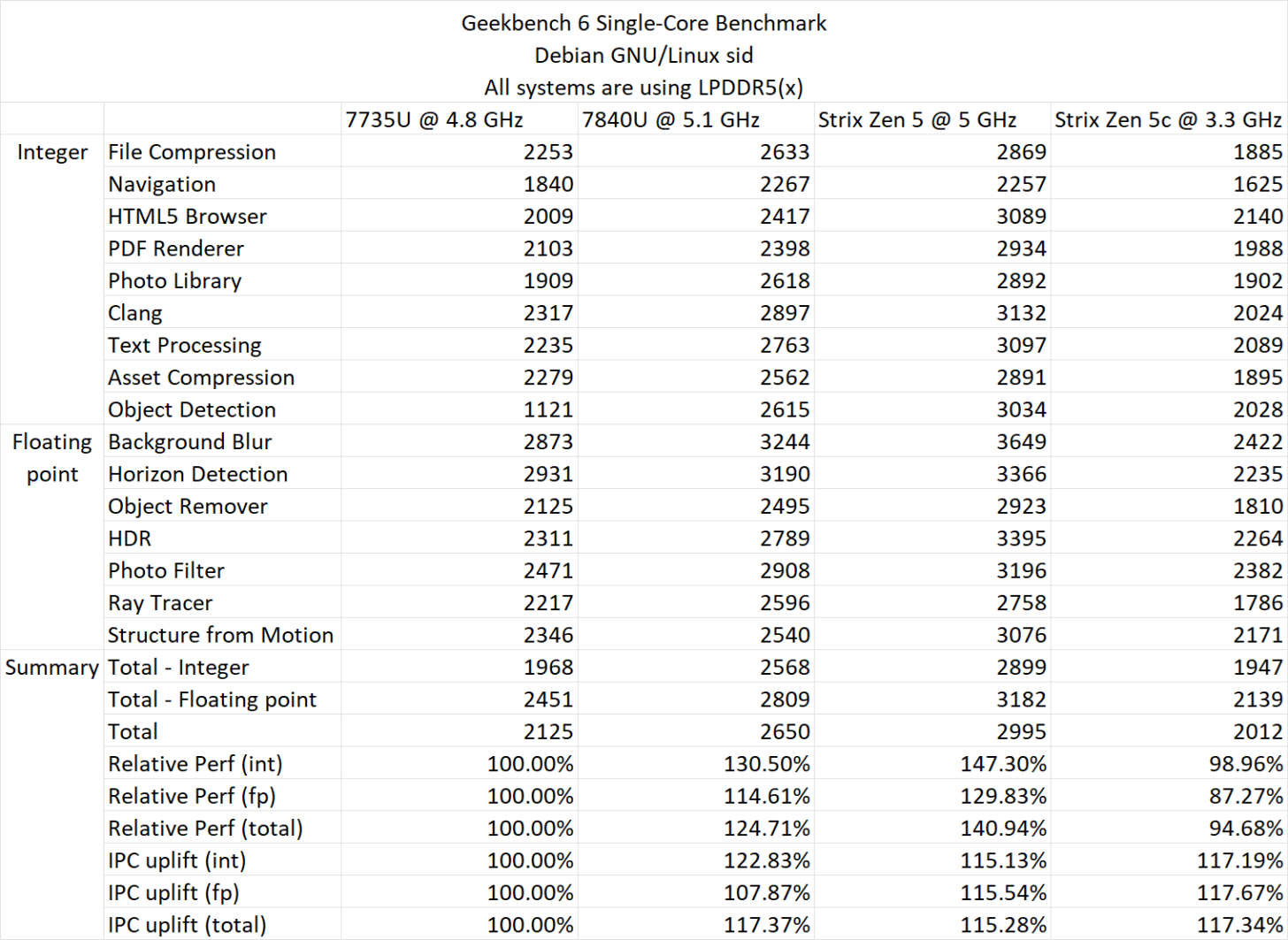
In Geekbench 6, the relative performance improvement over Zen 3 is up to 40.94% versus Zen 3 and Zen 4, it's about 13.1%. These numbers are in single-core only. With multi-core tests, the Zen 5 "Strix Point" APUs see a 55.45% uplift over Zen 3 and a 24.3% improvement over Zen 4 but it should be noted that Zen 3 and Zen 4 chips were running a 28W TDP versus the 54W of the Ryzen AI 9 365 APU.
SPEC CPU 2017 IPC (Gen-To-Gen)
- Zen 3 - 100.00%
- Zen 4 - 111.46%
- Zen 5 - 109.71%
SPEC CPU 2017 Perf (Relative)
- Zen 3 - 100.00%
- Zen 4 - 111.46%
- Zen 5 - 122.28%
Geekbench 6 ST IPC (Gen-To-Gen)
- Zen 3 - 100.00%
- Zen 4 - 117.37%
- Zen 5 - 115.28%
Geekbench 6 ST Perf (Relative)
- Zen 3 - 100.00%
- Zen 4 - 124.71%
- Zen 5 - 140.94%
David's blog post goes extensively into the various architectural aspects of the Zen 5 architecture that will not only be powering the Ryzen AI 300 "Strix Point" APUs but also several different CPUs such as the Ryzen 9000 "Granite Ridge" Desktop family, the 5th Gen EPYC "Turin" Server family & various other APUs for desktop and laptop platforms.
What we know officially is that Zen 5 cores come with an average IPC uplift of 16% and it ranges for different workloads so once again, we will advise our readers to take these results with a pinch of salt. The first launch of Zen 5 is expected with the Strix APUs in mid of July followed by Ryzen 9000 high-performance desktop chips in late July so stay tuned for more information.
News Source: David Huang




