Natural language processing (NLP) is a subfield of computer science and artificial intelligence concerned with the interactions between computers and human (natural) languages.
In NLP techniques, we map the words and phrases (from vocabulary or corpus) to vectors of numbers to make the processing easier. These types of language modeling techniques are called word embeddings.
Let’s implement our skip-gram model (in Python) by deriving the backpropagation equations of our neural network.
What is Skip-Gram?
In skip-gram architecture of word2vec, the input is the center word and the predictions are the context words. Consider an array of words W, if W(i) is the input (center word), then W(i-2), W(i-1), W(i+1), and W(i+2) are the context words if the sliding window size is 2.

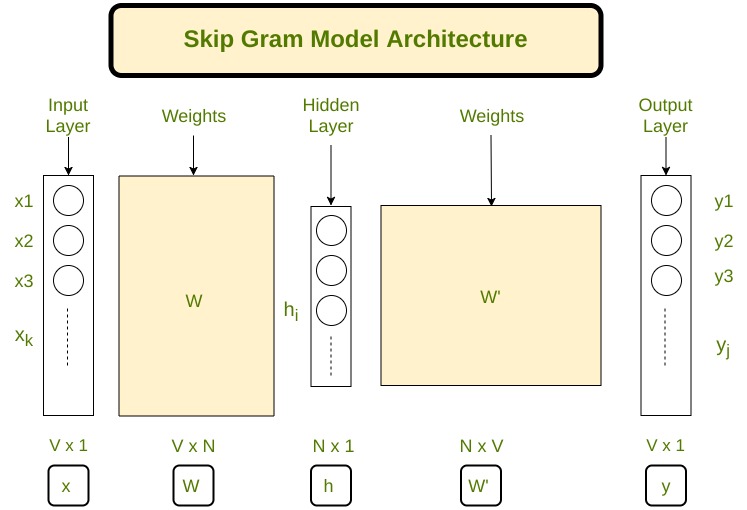
Let's define some variables :
V Number of unique words in our corpus of text ( Vocabulary )
x Input layer (One hot encoding of our input word ).
N Number of neurons in the hidden layer of neural network
W Weights between input layer and hidden layer
W' Weights between hidden layer and output layer
y A softmax output layer having probabilities of every word in our vocabulary
Neural Network Architecture
Our neural network architecture is defined, now let’s do some math to derive the equations needed for gradient descent.
Forward Propagation
- Hidden Layer Calculation:
- Multiply one hot encoding of the center word (denoted by x) with the first weight matrix W to get hidden layer matrix h.
- [Tex]h = W^T.x[/Tex]
- Dimensions: [Tex](V \times 1) (N \times V) (V \times 1)[/Tex]
- Output Layer Calculation:
- Multiply the hidden layer vector h with second weight matrix W’ to get a new matrix u.
- [Tex]u = W’^T.h[/Tex]
- Dimensions: [Tex](V \times 1) (V \times N) (N \times 1)[/Tex]
- Apply Softmax:
- Apply a softmax function to layer u to get our output layer y.
- Let [Tex]u_j[/Tex] be the jth neuron of layer u.
- Let [Tex]w_j[/Tex] be the jth word in our vocabulary where j is any index.
- Let [Tex]V_{w_j}[/Tex] be the jth column of matrix W’ (column corresponding to a word [Tex]w_j[/Tex]).
- [Tex]u_j = V_{w_j}^T.h[/Tex]
- [Tex]y = \text{softmax}(u)[/Tex]
- [Tex]y_j = \text{softmax}(u_j)[/Tex]
- [Tex]P(w_j | w_i) = y_j = \frac{e^{u_j}}{\sum_{j’=1}^{V} e^{u_{j’}}}[/Tex]
- Maximizing Probability:
- Our goal is to maximize [Tex]P(w_{j^*} | w_i)[/Tex], where [Tex]j^*[/Tex] represents the indices of context words.
- Maximize [Tex]\prod_{c=1}^{C} \frac{e^{u_{j_c^*}}}{\sum_{j’=1}^{V} e^{u_{j’}}}[/Tex]
Loss Function
- Take the negative log-likelihood of this function to get our loss function.
- [Tex]E = – \log{ \left( \prod_{c=1}^{C} \frac{e^{u_{j_c^*}}}{\sum_{j’=1}^{V} e^{u_{j’}}} \right) }[/Tex]
- Let t be the actual output vector from our training data.
- [Tex]E = -\sum_{c=1}^{C} u_{j_c^*} + C \log{\sum_{j’=1}^{V} e^{u_{j’}}}[/Tex]
Back Propagation
The parameters to be adjusted are in the matrices W and W’, hence we have to find the partial derivatives of our loss function with respect to W and W’ to apply the gradient descent algorithm.
Derivatives Calculation
- For W’:
- [Tex]\frac{\partial E}{\partial W’} = \frac{\partial E}{\partial u_j} \cdot \frac{\partial u_j}{\partial W’}[/Tex]
- [Tex]\frac{\partial E}{\partial u_j} = y_j – t_j = e_j[/Tex]
- [Tex]\frac{\partial E}{\partial W’} = e_j \cdot h_i[/Tex]
- For W:
- [Tex]\frac{\partial E}{\partial W} = \frac{\partial E}{\partial u_j} \cdot \frac{\partial u_j}{\partial h_i} \cdot \frac{\partial h_i}{\partial W}[/Tex]
- [Tex]\frac{\partial E}{\partial W} = e_j \cdot W’ \cdot x_i[/Tex]
Skip gram architecture
Implementing Word2Vec (Skip-gram) Model in Python
In this section, we are going to step by step implement a simple skip-gram model for word2vec in python using nympy operations.
Step 1: Importing Libraries and Setting Up Environment
We begin by importing the necessary libraries, including numpy for numerical computations and nltk for natural language processing. Additionally, we download the NLTK stopwords dataset.
import numpy as np
import string
from nltk.corpus import stopwords
import nltk
nltk.download('stopwords')
Step 2: Defining the Softmax Function
The softmax function is used to convert raw scores (logits) into probabilities. It is commonly used in the output layer of a neural network for classification problems.
def softmax(x):
"""Compute softmax values for each sets of scores in x."""
e_x = np.exp(x - np.max(x))
return e_x / e_x.sum()
Step 3: Creating the Word2Vec Class
We define the word2vec class, which will contain methods for initializing weights, performing forward propagation, backpropagation, training, and prediction.
class word2vec(object):
def __init__(self):
self.N = 10
self.X_train = []
self.y_train = []
self.window_size = 2
self.alpha = 0.001
self.words = []
self.word_index = {}
def initialize(self, V, data):
self.V = V
self.W = np.random.uniform(-0.8, 0.8, (self.V, self.N))
self.W1 = np.random.uniform(-0.8, 0.8, (self.N, self.V))
self.words = data
for i in range(len(data)):
self.word_index[data[i]] = i
Step 4: Forward Propagation
The forward propagation method calculates the hidden layer activations and the output layer probabilities using the softmax function.
def feed_forward(self, X):
self.h = np.dot(self.W.T, X).reshape(self.N, 1)
self.u = np.dot(self.W1.T, self.h)
self.y = softmax(self.u)
return self.y
Step 5: Backpropagation
The backpropagation method adjusts the weights based on the error between the predicted output and the actual context words. It calculates the gradients and updates the weight matrices.
def backpropagate(self, x, t):
e = self.y - np.asarray(t).reshape(self.V, 1)
dLdW1 = np.dot(self.h, e.T)
X = np.array(x).reshape(self.V, 1)
dLdW = np.dot(X, np.dot(self.W1, e).T)
self.W1 = self.W1 - self.alpha * dLdW1
self.W = self.W - self.alpha * dLdW
Step 6: Training the Model
The train method iterates over the training data for a specified number of epochs. In each epoch, it performs forward propagation, backpropagation, and computes the loss.
def train(self, epochs):
for x in range(1, epochs):
self.loss = 0
for j in range(len(self.X_train)):
self.feed_forward(self.X_train[j])
self.backpropagate(self.X_train[j], self.y_train[j])
C = 0
for m in range(self.V):
if self.y_train[j][m]:
self.loss += -1 * self.u[m][0]
C += 1
self.loss += C * np.log(np.sum(np.exp(self.u)))
print("epoch ", x, " loss = ", self.loss)
self.alpha *= 1 / ((1 + self.alpha * x))
Step 7: Prediction
The predict method takes a word and returns the top context words based on the trained model. It uses the forward propagation method to get the probabilities and sorts them to find the most likely context words.
def predict(self, word, number_of_predictions):
if word in self.words:
index = self.word_index[word]
X = [0 for i in range(self.V)]
X[index] = 1
prediction = self.feed_forward(X)
output = {}
for i in range(self.V):
output[prediction[i][0]] = i
top_context_words = []
for k in sorted(output, reverse=True):
top_context_words.append(self.words[output[k]])
if len(top_context_words) >= number_of_predictions:
break
return top_context_words
else:
print("Word not found in dictionary")
Step 8: Preprocessing the Corpus
The preprocessing function cleans and prepares the text data by removing stopwords and punctuation, and converting words to lowercase.
def preprocessing(corpus):
stop_words = set(stopwords.words('english'))
training_data = []
sentences = corpus.split(".")
for i in range(len(sentences)):
sentences[i] = sentences[i].strip()
sentence = sentences[i].split()
x = [word.strip(string.punctuation) for word in sentence if word not in stop_words]
x = [word.lower() for word in x]
training_data.append(x)
return training_data
Step 9: Preparing Data for Training
The prepare_data_for_training function creates the training data by generating one-hot encoded vectors for the center and context words based on the window size.
def prepare_data_for_training(sentences, w2v):
data = {}
for sentence in sentences:
for word in sentence:
if word not in data:
data[word] = 1
else:
data[word] += 1
V = len(data)
data = sorted(list(data.keys()))
vocab = {}
for i in range(len(data)):
vocab[data[i]] = i
for sentence in sentences:
for i in range(len(sentence)):
center_word = [0 for x in range(V)]
center_word[vocab[sentence[i]]] = 1
context = [0 for x in range(V)]
for j in range(i - w2v.window_size, i + w2v.window_size + 1):
if i != j and j >= 0 and j < len(sentence):
context[vocab[sentence[j]]] += 1
w2v.X_train.append(center_word)
w2v.y_train.append(context)
w2v.initialize(V, data)
return w2v.X_train, w2v.y_train
Step 10: Running the Training and Prediction
Finally, we run the preprocessing, training, and prediction steps. We define a corpus, preprocess it, prepare the training data, train the model, and make predictions.
corpus = "The earth revolves around the sun. The moon revolves around the earth"
epochs = 1000
training_data = preprocessing(corpus)
w2v = word2vec()
prepare_data_for_training(training_data, w2v)
w2v.train(epochs)
print(w2v.predict("around", 3))
Complete Implementation
Python
import numpy as np
import string
from nltk.corpus import stopwords
import nltk
nltk.download('stopwords')
def softmax(x):
"""Compute softmax values for each sets of scores in x."""
e_x = np.exp(x - np.max(x))
return e_x / e_x.sum()
class word2vec(object):
def __init__(self):
self.N = 10
self.X_train = []
self.y_train = []
self.window_size = 2
self.alpha = 0.001
self.words = []
self.word_index = {}
def initialize(self,V,data):
self.V = V
self.W = np.random.uniform(-0.8, 0.8, (self.V, self.N))
self.W1 = np.random.uniform(-0.8, 0.8, (self.N, self.V))
self.words = data
for i in range(len(data)):
self.word_index[data[i]] = i
def feed_forward(self,X):
self.h = np.dot(self.W.T,X).reshape(self.N,1)
self.u = np.dot(self.W1.T,self.h)
#print(self.u)
self.y = softmax(self.u)
return self.y
def backpropagate(self,x,t):
e = self.y - np.asarray(t).reshape(self.V,1)
# e.shape is V x 1
dLdW1 = np.dot(self.h,e.T)
X = np.array(x).reshape(self.V,1)
dLdW = np.dot(X, np.dot(self.W1,e).T)
self.W1 = self.W1 - self.alpha*dLdW1
self.W = self.W - self.alpha*dLdW
def train(self,epochs):
for x in range(1,epochs):
self.loss = 0
for j in range(len(self.X_train)):
self.feed_forward(self.X_train[j])
self.backpropagate(self.X_train[j],self.y_train[j])
C = 0
for m in range(self.V):
if(self.y_train[j][m]):
self.loss += -1*self.u[m][0]
C += 1
self.loss += C*np.log(np.sum(np.exp(self.u)))
print("epoch ",x, " loss = ",self.loss)
self.alpha *= 1/( (1+self.alpha*x) )
def predict(self,word,number_of_predictions):
if word in self.words:
index = self.word_index[word]
X = [0 for i in range(self.V)]
X[index] = 1
prediction = self.feed_forward(X)
output = {}
for i in range(self.V):
output[prediction[i][0]] = i
top_context_words = []
for k in sorted(output,reverse=True):
top_context_words.append(self.words[output[k]])
if(len(top_context_words)>=number_of_predictions):
break
return top_context_words
else:
print("Word not found in dictionary")
def preprocessing(corpus):
stop_words = set(stopwords.words('english'))
training_data = []
sentences = corpus.split(".")
for i in range(len(sentences)):
sentences[i] = sentences[i].strip()
sentence = sentences[i].split()
x = [word.strip(string.punctuation) for word in sentence
if word not in stop_words]
x = [word.lower() for word in x]
training_data.append(x)
return training_data
def prepare_data_for_training(sentences,w2v):
data = {}
for sentence in sentences:
for word in sentence:
if word not in data:
data[word] = 1
else:
data[word] += 1
V = len(data)
data = sorted(list(data.keys()))
vocab = {}
for i in range(len(data)):
vocab[data[i]] = i
#for i in range(len(words)):
for sentence in sentences:
for i in range(len(sentence)):
center_word = [0 for x in range(V)]
center_word[vocab[sentence[i]]] = 1
context = [0 for x in range(V)]
for j in range(i-w2v.window_size,i+w2v.window_size):
if i!=j and j>=0 and j<len(sentence):
context[vocab[sentence[j]]] += 1
w2v.X_train.append(center_word)
w2v.y_train.append(context)
w2v.initialize(V,data)
return w2v.X_train,w2v.y_train
corpus = ""
corpus += "The earth revolves around the sun. The moon revolves around the earth"
epochs = 1000
training_data = preprocessing(corpus)
w2v = word2vec()
prepare_data_for_training(training_data,w2v)
w2v.train(epochs)
print(w2v.predict("around",3))
Output:
epoch 1 loss = 42.11388999718691
epoch 2 loss = 42.046624187204344
epoch 3 loss = 41.979860169596975
epoch 4 loss = 41.91365796481678
epoch 5 loss = 41.848075221435785
...
epoch 995 loss = 38.344465104706956
epoch 996 loss = 38.34437416057446
epoch 997 loss = 38.34428339972524
epoch 998 loss = 38.34419282160614
epoch 999 loss = 38.34410242566626
['earth', 'around', 'sun']
The function correctly identifies “earth”, “around”, and “sun” as the top context words for “around” based on the trained model, demonstrating the relationships captured by the word embeddings.
Conclusion
This implementation demonstrates how to build a simple skip-gram model for word2vec using basic numpy operations. The model learns word embeddings by minimizing the loss function through gradient descent, effectively capturing relationships between words in the corpus. The output shows the top context words for a given input word, illustrating the model’s ability to understand and predict word associations based on the learned embeddings.