An Operating System (OS) is a system software that manages computer hardware, software resources, and provides common services for computer programs. It acts as an interface between the user and the computer hardware.
Types of Operating System (OS):
- Batch OS – A set of similar jobs are stored in the main memory for execution. A job gets assigned to the CPU, only when the execution of the previous job completes.
- Multiprogramming OS – The main memory consists of jobs waiting for CPU time. The OS selects one of the processes and assigns it to the CPU. Whenever the executing process needs to wait for any other operation (like I/O), the OS selects another process from the job queue and assigns it to the CPU. This way, the CPU is never kept idle and the user gets the flavor of getting multiple tasks done at once.
- Multi-Tasking/Time-sharing Operating systems: It is a type of Multiprogramming system with every process running in round robin manner. Each task is given some time to execute so that all the tasks work smoothly. Each user gets the time of the CPU as they use a single system. These systems are also known as Multitasking Systems. The task can be from a single user or different users also. The time that each task gets to execute is called quantum. After this time interval is over OS switches over to the next task.
- Multi-Processing Operating System: Multi-Processing Operating System is a type of Operating System in which more than one CPU is used for the execution of resources. It betters the throughput of the System.
- Multi User Operating Systems: These systems allow multiple users to be active at the same time. These system can be either multiprocessor or single processor with interleaving.
- Distributed Operating System: These types of operating system is a recent advancement in the world of computer technology and are being widely accepted all over the world and, that too, at a great pace. Various autonomous interconnected computers communicate with each other using a shared communication network. Independent systems possess their own memory unit and CPU.
- Network Operating System: These systems run on a server and provide the capability to manage data, users, groups, security, applications, and other networking functions. These types of operating systems allow shared access to files, printers, security, applications, and other networking functions over a small private network.
- Real Time OS – Real-Time OS are usually built for dedicated systems to accomplish a specific set of tasks within deadlines.
Threads
A thread is a lightweight process and forms the basic unit of CPU utilization. A process can perform more than one task at the same time by including multiple threads.
- A thread has its own program counter, register set, and stack
- A thread shares resources with other threads of the same process the code section, the data section, files and signals.
A new thread, or a child process of a given process, can be introduced by using the fork() system call.
A process with n fork() system calls generates 2n – 1 child processes.
There are two types of threads:
- User threads
- Kernel threads
Example: Java thread, POSIX threads. Example : Window Solaris.
Types of Threads
1. Based on the number of threads
There are two types of threads:
(i) Single thread process
(ii) Multi thread process
2. Based on level
There are two types of threads:
(i) User-level threads
(ii) Kernel-level threads
read more about – Threads
Process
A process is a program under execution. The value of program counter (PC) indicates the address of the next instruction of the process being executed. Each process is represented by a Process Control Block (PCB).
Process States Diagram:
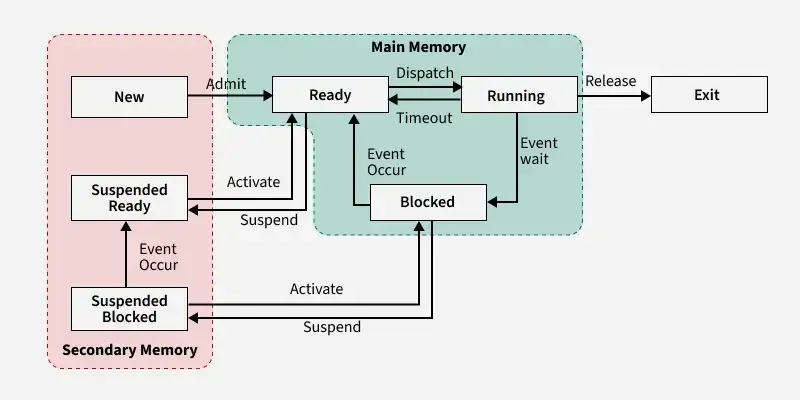
Schedulers
The operating system deploys three kinds of schedulers:
- Long-term scheduler: It is responsible for the creation and bringing of new processes into the main memory (New → Ready state transition).
- Medium-term scheduler: The medium-term scheduler acts as the swapper by doing swap-out (suspending the process from the main to secondary memory) and swap-in (resuming the process by bringing it from the secondary to main memory) operations.
- Short-term scheduler: The short-term scheduler selects a process from the ready state to be executed (Ready → Run state transition).
Dispatchers
The dispatcher is responsible for loading the job (selected by the short-term scheduler) onto the CPU. It performs context switching. Context switching refers to saving the context of the process which was being executed by the CPU and loading the context of the new process that is being scheduled to be executed by the CPU.
CPU Scheduling Algorithms
Why do we need scheduling? A typical process involves both I/O time and CPU time. In a uniprogramming system like MS-DOS, time spent waiting for I/O is wasted and CPU is free during this time. In multiprogramming systems, one process can use CPU while another is waiting for I/O. This is possible only with process scheduling.
Process Scheduling: Below are different times with respect to a process.
- Arrival Time – Time at which the process arrives in the ready queue.
- Completion Time – Time at which process completes its execution.
- Burst Time – Time required by a process for CPU execution.
- Turn Around Time – Time Difference between completion time and arrival time.
Turn Around Time = Completion Time – Arrival Time
- Waiting Time (WT) – Time Difference between turn around time and burst time.
Waiting Time = Turn Around Time – Burst Time
Objectives of Process Scheduling Algorithm:
- Max CPU utilization (Keep CPU as busy as possible)
- Fair allocation of CPU.
- Max throughput (Number of processes that complete their execution per time unit)
- Min turnaround time (Time taken by a process to finish execution)
- Min waiting time (Time for which a process waits in ready queue)
- Min response time (Time when a process produces first response)
Different CPU Scheduling Algorithms:
1. First Come First Serve (FCFS): First Come, First Serve (FCFS) is one of the simplest types of CPU scheduling algorithms. It is exactly what it sounds like: processes are attended to in the order in which they arrive in the ready queue, much like customers lining up at a grocery store.
- It is a non pre-emptive algorithm.
- Processes are assigned to the CPU based on their arrival times. If two or more processes have the same arrival times, then the processes are assigned based on their process ids.
- It is free from starvation
2. Shortest Job First (SJF): Shortest Job First (SJF) or Shortest Job Next (SJN) is a scheduling process that selects the waiting process with the smallest execution time to execute next.
- It is a non-pre-emptive algorithm.
- If all the processes have the same burst times, SJF behaves as FCFS.
- In SJF, the burst times of all the processes should be known prior execution.
- It minimizes the average response time of the processes.
- There is a chance of starvation.
3. Shortest Remaining Time First (SRTF): It is preemptive mode of SJF algorithm in which jobs are scheduled according to the shortest remaining time.
- It is a pre-emptive algorithm.
- Processes are assigned to the CPU based on their shortest remaining burst times.
- If all the processes have the same arrival times, SRTF behaves as SJF.
- It minimizes the average turnaround time of the processes.
- If shorter processes keep on arriving, then the longer processes may starve.
4. Round Robin (RR) Scheduling: It is a method used by operating systems to manage the execution time of multiple processes that are competing for CPU attention.
- RR scheduling is a pre-emptive FCFS based on the concept of time quantum or time slice.
- If the time quantum is too small, then the number of context switches (overhead) will increase and the average response time will decrease.
- If the time quantum is too large, then the number of context switches (overhead) will decrease and the average response time will increase.
- If the time quantum is greater than the burst times of all the processes, RR scheduling behaves as FCFS.
5. Priority Based scheduling: In this scheduling, processes are scheduled according to their priorities, i.e., highest priority process is schedule first. If priorities of two processes match, then scheduling is according to the arrival time.
- Priority scheduling can either be pre-emptive or non-pre-emptive.
- In pre-emptive priority scheduling, a process is voluntarily pre-empted whenever a higher priority process arrives.
- In non-pre-emptive priority scheduling, the scheduler picks up the highest priority process.
- If all the processes have equal priority, then priority scheduling behaves as FCFS.
6. Highest Response Ratio Next (HRRN): In this scheduling, processes with highest response ratio is scheduled. This algorithm avoids starvation.
- It is a non pre-emptive algorithm.
- Processes are assigned to the CPU based on their highest response ratio.
- Response ratio is calculated as:
[Tex]\text{Response Ratio} = \frac{\text{WT} + \text{BT}}{\text{BT}}[/Tex]
- It is free from starvation.
- It favors the shorter jobs and limits the waiting time of the longer jobs.
Some useful facts about Scheduling Algorithms:
- FCFS can cause long waiting times, especially when the first job takes too much CPU time.
- Both SJF and Shortest Remaining time first algorithms may cause starvation. Consider a situation when a long process is there in the ready queue and shorter processes keep coming.
- If time quantum for Round Robin scheduling is very large, then it behaves same as FCFS scheduling.
- SJF is optimal in terms of average waiting time for a given set of processes. SJF gives minimum average waiting time, but problems with SJF is how to know/predict the time of next job.
read more about – CPU Scheduling Algorithms
Critical Section Problem
- Critical Section – The portion of the code in the program where shared variables are accessed and/or updated.
- Remainder Section – The remaining portion of the program excluding the Critical Section.
- Race around Condition – The final output of the code depends on the order in which the variables are accessed. This is termed as the race around condition.
A solution for the critical section problem must satisfy the following three conditions:
- Mutual Exclusion – If a process Pi is executing in its critical section, then no other process is allowed to enter into the critical section.
- Progress – If no process is executing in the critical section, then the decision of a process to enter a critical section cannot be made by any other process that is executing in its remainder section. The selection of the process cannot be postponed indefinitely.
- Bounded Waiting – There exists a bound on the number of times other processes can enter into the critical section after a process has made request to access the critical section and before the requested is granted.
Synchronization Tools: A Semaphore is an integer variable that is accessed only through two atomic operations, wait () and signal (). An atomic operation is executed in a single CPU time slice without any pre-emption. Semaphores are of two types:
- Counting Semaphore – A counting semaphore is an integer variable whose value can range over an unrestricted domain.
- Mutex – A mutex provides mutual exclusion, either producer or consumer can have the key (mutex) and proceed with their work. As long as the buffer is filled by producer, the consumer needs to wait, and vice versa. At any point of time, only one thread can work with the entire buffer. The concept can be generalized using semaphore.
Misconception: There is an ambiguity between binary semaphore and mutex. We might have come across that a mutex is binary semaphore. But they are not! The purpose of mutex and semaphore are different. May be, due to similarity in their implementation a mutex would be referred as binary semaphore.
read more about – Critical Section Problem
Deadlock
A situation where a set of processes are blocked because each process is holding a resource and waiting for another resource acquired by some other process. Deadlock can arise if following four conditions hold simultaneously (Necessary Conditions):
- Mutual Exclusion – One or more than one resource are non-sharable (Only one process can use at a time).
- Hold and Wait – A process is holding at least one resource and waiting for resources.
- No Preemption – A resource cannot be taken from a process unless the process releases the resource.
- Circular Wait – A set of processes are waiting for each other in circular form.
Deadlock handling
There are three ways to handle deadlock
1. Deadlock prevention
To ensure the system never enters a deadlock state, at least one of the conditions for deadlock must be prevented:
- Mutual Exclusion: This condition cannot be removed because some resources (non-shareable resources) must be exclusively allocated to one process at a time.
- Hold and Wait: This condition can be avoided using the following strategies:
- Allocate all required resources to a process before it starts execution. However, this approach might lead to low resource utilization.
- Force a process to release all its held resources before requesting new ones. However, this might cause starvation (a process waiting indefinitely).
- Pre-emption:
- If a process P1P1P1 requests a resource RRR that is held by another process P2P2P2:
- If P2P2P2 is still running, P1P1P1 will have to wait.
- Otherwise, the resource RRR can be taken (pre-empted) from P2P2P2 and allocated to P1P1P1.
- Circular Wait: This condition can be avoided using the following method:
- Assign a unique number to each resource (assuming there is only one instance of each resource).
- Ensure processes request resources in a strict order, either increasing or decreasing based on the assigned numbers.
2. Deadlock Avoidance
The Deadlock Avoidance Algorithm prevents deadlocks by monitoring resource usage and resolving conflicts before they occur, like rolling back processes or reallocating resources. It minimizes deadlocks but doesn’t fully guarantee their prevention. The two key techniques are:
- Process Initiation Denial: Blocks processes that might cause deadlock.
- Resource Allocation Denial: Rejects resource requests that could lead to deadlock.
Banker’s Algorithm
The Banker’s Algorithm is a resource allocation and deadlock avoidance algorithm used in operating systems. It ensures that the system remains in a safe state by simulating the allocation of resources to processes without running into a deadlock.
The following Data structures are used to implement the Banker’s Algorithm:
1. Available: It is a 1-D array of size ‘m’ indicating the number of available resources of each type. Available[ j ] = k means there are ‘k’ instances of resource type R j.
2. Max: It is a 2-d array of size ‘ n*m’ that defines the maximum demand of each process in a system. Max[ i, j ] = k means process Pi may request at most ‘k’ instances of resource type Rj.
3.Allocated: It is a 2-d array of size ‘n*m’ that defines the number of resources of each type currently allocated to each process. Allocation[ i, j ] = k means process Pi is currently allocated ‘k’ instances of resource type Rj.
4. Need: It is a 2-d array of size ‘n*m’ that indicates the remaining resource need of each process. Need [ i, j ] = k means process Pi currently needs ‘k’ instances of resource type Rj Need [ i, j ] = Max [ i, j ] – Allocation [ i, j ].
3. Deadlock Detection and Recovery
Detection: A cycle in the resource allocation graph represents deadlock only when resources are of single-instance type. If the resources are of multiple instance type, then the safety algorithm is used to detect deadlock.
Recovery: A system can recover from deadlock through adoption of the following mechanisms:
- Process termination
- Resource Pre-emption
4. Deadlock Ignorance
In the Deadlock ignorance method the OS acts like the deadlock never occurs and completely ignores it even if the deadlock occurs. This method only applies if the deadlock occurs very rarely. The algorithm is very simple. It says, ” if the deadlock occurs, simply reboot the system and act like the deadlock never occurred.” That’s why the algorithm is called the Ostrich Algorithm.
read more about – Deadlock
Memory Management
In multiprogramming system, the task of subdividing the memory among the various processes is called memory management. The task of the memory management unit is the efficient utilization of memory and minimize the internal and external fragmentation.
Why Memory Management is Required?
- Allocate and de-allocate memory before and after process execution.
- To keep track of used memory space by processes.
- To minimize fragmentation issues.
- To proper utilization of main memory.
- To maintain data integrity while executing of process.
Logical and Physical Address Space
- Logical Address Space: An address generated by the CPU is known as a “Logical Address”. It is also known as a Virtual address. Logical address space can be defined as the size of the process. A logical address can be changed.
- Physical Address Space: An address seen by the memory unit (i.e. the one loaded into the memory address register of the memory) is commonly known as a “Physical Address”. A Physical address is also known as a Real address.
Static and Dynamic Loading
Loading a process into the main memory is done by a loader. There are two different types of loading :
- Static Loading: Static Loading is basically loading the entire program into a fixed address. It requires more memory space.
- Dynamic Loading: The entire program and all data of a process must be in physical memory for the process to execute. So, the size of a process is limited to the size of physical memory. To gain proper memory utilization, dynamic loading is used. In dynamic loading, a routine is not loaded until it is called.
Memory Management Techniques
(a) Single Partition Allocation Schemes – The memory is divided into two parts. One part is kept to be used by the OS and the other is kept to be used by the users.
(b) Multiple Partition Schemes –
- Fixed Partition – The memory is divided into fixed size partitions.
- Variable Partition – The memory is divided into variable sized partitions.
Variable partition allocation schemes:
- First Fit – The arriving process is allotted the first hole of memory in which it fits completely.
- Best Fit – The arriving process is allotted the hole of memory in which it fits the best by leaving the minimum memory empty.
- Worst Fit – The arriving process is allotted the hole of memory in which it leaves the maximum gap.
Note:
- Best fit does not necessarily give the best results for memory allocation.
- The cause of external fragmentation is the condition in Fixed partitioning and Variable partitioning saying that entire process should be allocated in a contiguous memory location. Therefore Paging is used.
Paging
The physical memory is divided into equal sized frames. The main memory is divided into fixed size pages. The size of a physical memory frame is equal to the size of a virtual memory frame.

Segmentation
Segmentation is implemented to give users view of memory. The logical address space is a collection of segments. Segmentation can be implemented with or without the use of paging.
-660.webp)
read more about – Memory Management Techniques
Page Fault: A page fault is a type of interrupt, raised by the hardware when a running program accesses a memory page that is mapped into the virtual address space, but not loaded in main/virtual memory.
Page Replacement Algorithms
1. First In First Out (FIFO)
This is the simplest page replacement algorithm. In this algorithm, operating system keeps track of all pages in the memory in a queue, oldest page is in the front of the queue. When a page needs to be replaced page in the front of the queue is selected for removal.
For example, consider page reference string 1, 3, 0, 3, 5, 6 and 3 page slots.
- Initially, all slots are empty, so when 1, 3, 0 came they are allocated to the empty slots —> 3 Page Faults.
- When 3 comes, it is already in memory so —> 0 Page Faults. Then 5 comes, it is not available in memory so it replaces the oldest page slot i.e 1. —> 1 Page Fault.
- Finally, 6 comes, it is also not available in memory so it replaces the oldest page slot i.e 3 —> 6 Page Fault.
Belady’s anomaly: Belady’s anomaly proves that it is possible to have more page faults when increasing the number of page frames while using the First in First Out (FIFO) page replacement algorithm.
For example, if we consider reference string 3 2 1 0 3 2 4 3 2 1 0 4 and 3 slots, we get 9 total page faults, but if we increase slots to 4, we get 10 page faults.
2. Optimal Page replacement
In this algorithm, pages are replaced which are not used for the longest duration of time in the future.
Let us consider page reference string 7 0 1 2 0 3 0 4 2 3 0 3 2 and 4 page slots.
Initially, all slots are empty, so when 7 0 1 2 are allocated to the empty slots —> 4 Page faults.
0 is already there so —> 0 Page fault.
When 3 came it will take the place of 7 because it is not used for the longest duration of time in the future.—> 1 Page fault.
0 is already there so —> 0 Page fault.
4 will takes place of 1 —> 1 Page Fault.
Now for the further page reference string —> 0 Page fault because they are already available in the memory.
Optimal page replacement is perfect, but not possible in practice as an operating system cannot know future requests. The use of Optimal Page replacement is to set up a benchmark so that other replacement algorithms can be analyzed against it.
3. Least Recently Used (LRU)
In this algorithm, the page will be replaced which is least recently used.
Let say the page reference string 7 0 1 2 0 3 0 4 2 3 0 3 2 .
Initially, we have 4-page slots empty. Initially, all slots are empty, so when 7 0 1 2 are allocated to the empty slots —> 4 Page faults.
0 is already their so —> 0 Page fault.
When 3 came it will take the place of 7 because it is least recently used —> 1 Page fault.
0 is already in memory so —> 0 Page fault. 4 will takes place of 1 —> 1 Page Fault.
Now for the further page reference string —> 0 Page fault because they are already available in the memory.
4. Most Recently Used (MRU)
In this algorithm, page will be replaced which has been used recently. Belady’s anomaly can occur in this algorithm.
Example: Consider the page reference string 7, 0, 1, 2, 0, 3, 0, 4, 2, 3, 0, 3, 2, 3 with 4-page frames. Find number of page faults using MRU Page Replacement Algorithm.
- Initially, all slots are empty, so when 7 0 1 2 are allocated to the empty slots —> 4 Page faults
- 0 is already their so–> 0 page fault
- when 3 comes it will take place of 0 because it is most recently used —> 1 Page fault
- when 0 comes it will take place of 3 —> 1 Page fault
- when 4 comes it will take place of 0 —> 1 Page fault
- 2 is already in memory so —> 0 Page fault
- when 3 comes it will take place of 2 —> 1 Page fault
- when 0 comes it will take place of 3 —> 1 Page fault
- when 3 comes it will take place of 0 —> 1 Page fault
- when 2 comes it will take place of 3 —> 1 Page fault
- when 3 comes it will take place of 2 —> 1 Page fault
read more about – Page Replacement Algorithms
Virtual Memory
Virtual memory is a memory management technique used by operating systems to give the appearance of a large, continuous block of memory to applications, even if the physical memory (RAM) is limited. It allows larger applications to run on systems with less RAM.
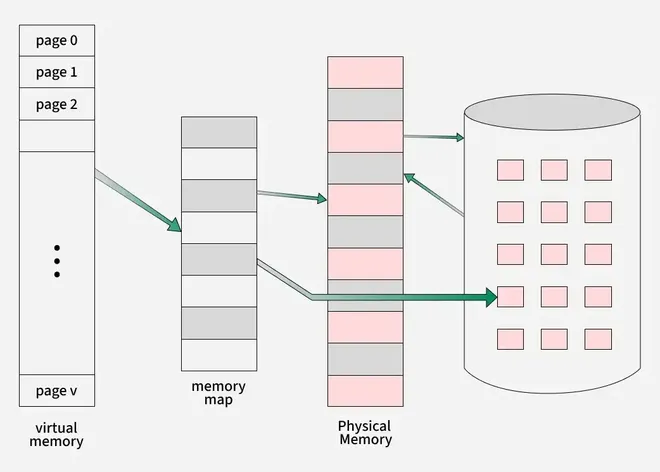
Demand Paging
Demand paging is a memory management technique used in operating systems where a page (a fixed-size block of memory) is only loaded into the computer’s RAM when it is needed, or “demanded” by a process.
How Demand Paging Works:
- When a Program Starts: Initially, only a part of the program (some pages) is loaded into RAM. The rest of the program is stored on the hard drive (secondary memory).
- When a Page is Needed: If the program needs a page that is not currently in RAM, a page fault occurs. This means the operating system must fetch the required page from the hard drive and load it into RAM.
- Efficient Memory Use: With demand paging, only the parts of the program that are actively used are in memory, which makes better use of RAM. This allows the system to run large programs without needing all of their data loaded into memory at once.
read more about – Demand Paging
Thrashing
Thrashing is a situation in which the operating system spends more time swapping data between RAM (main memory) and the hard drive (secondary memory) than actually executing processes. This happens when there isn’t enough physical memory (RAM) to handle the current workload, causing the system to constantly swap pages in and out of memory.
Techniques to handle Thrashing
read more about – Virtual Memory
File Systems
A file system is a method an operating system uses to store, organize, and manage files and directories on a storage device.
File Directories
The collection of files is a file directory. The directory contains information about the files, including attributes, location, and ownership. Much of this information, especially that is concerned with storage, is managed by the operating system.
Below are information contained in a device directory.
- Name
- Type
- Address
- Current length
- Maximum length
- Date last accessed
- Date last updated
- Owner id
- Protection information
The operation performed on the directory are:
- Search for a file
- Create a file
- Delete a file
- List a directory
- Rename a file
- Traverse the file system
File Allocation Methods
There are several types of file allocation methods. These are mentioned below.
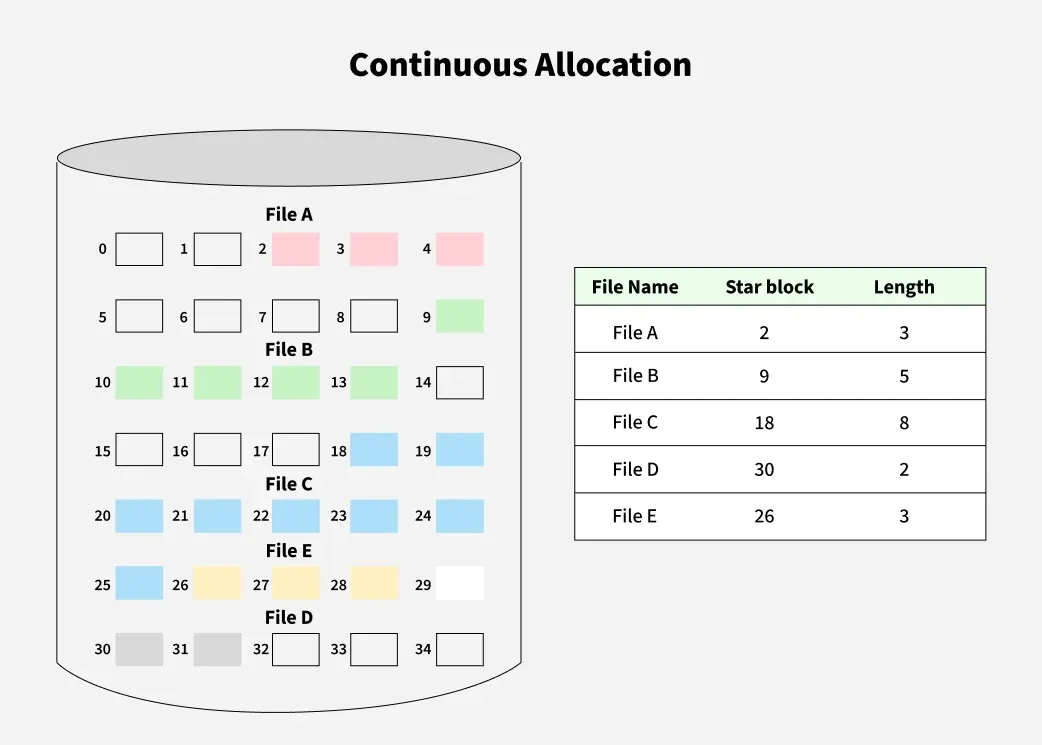
Continuous Allocation: A single continuous set of blocks is allocated to a file at the time of file creation. Thus, this is a pre-allocation strategy, using variable size portions. The file allocation table needs just a single entry for each file, showing the starting block and the length of the file.
Linked Allocation(Non-contiguous allocation): Allocation is on an individual block basis. Each block contains a pointer to the next block in the chain. Again the file table needs just a single entry for each file, showing the starting block and the length of the file. Although pre-allocation is possible, it is more common simply to allocate blocks as needed. Any free block can be added to the chain.

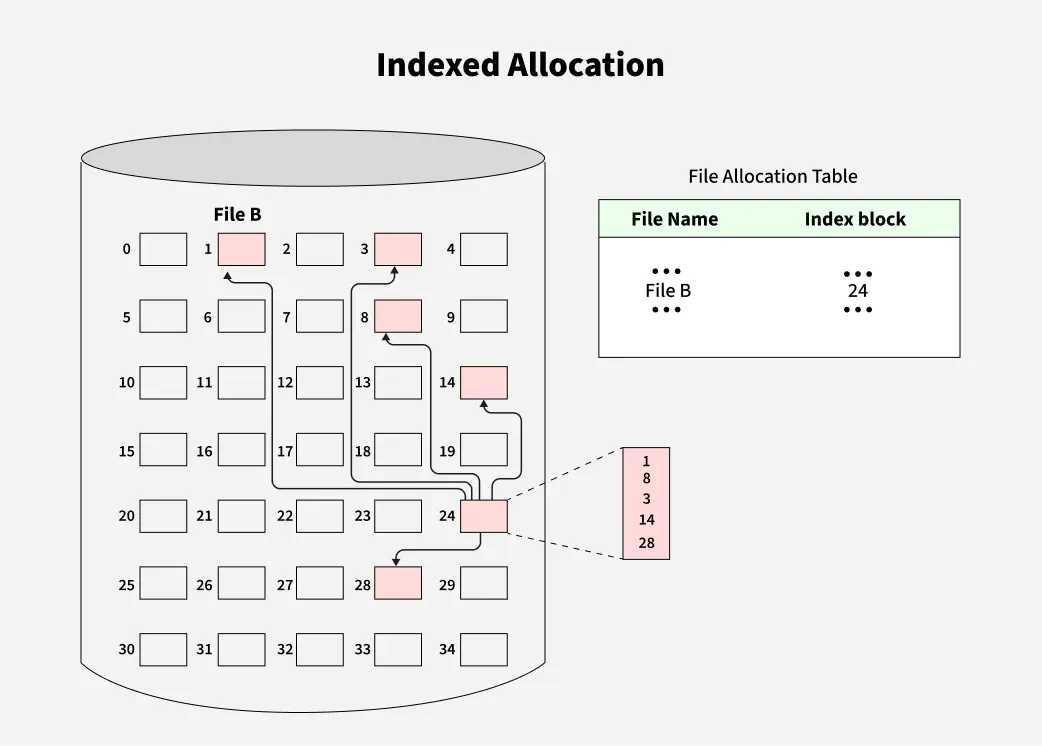
Indexed Allocation: Allocation is on an individual block basis. Each block contains a pointer to the next block in the chain. Again the file table needs just a single entry for each file, showing the starting block and the length of the file. Although pre-allocation is possible, it is more common simply to allocate blocks as needed. Any free block can be added to the chain.
read more about – File Systems
Disk Scheduling
Disk scheduling algorithms are crucial in managing how data is read from and written to a computer’s hard disk. These algorithms help determine the order in which disk read and write requests are processed, significantly impacting the speed and efficiency of data access. Common disk scheduling methods include First-Come, First-Served (FCFS), Shortest Seek Time First (SSTF), SCAN, C-SCAN, LOOK, and C-LOOK. By understanding and implementing these algorithms, we can optimize system performance and ensure faster data retrieval.
Disk scheduling Algorithms
Different Disk scheduling Algorithms are:
- FCFS (First Come First Serve): FCFS is the simplest of all Disk Scheduling Algorithms. In FCFS, the requests are addressed in the order they arrive in the disk queue.
- SSTF (Shortest Seek Time First): In SSTF (Shortest Seek Time First), requests having the shortest seek time are executed first. So, the seek time of every request is calculated in advance in the queue and then they are scheduled according to their calculated seek time. As a result, the request near the disk arm will get executed first. SSTF is certainly an improvement over FCFS as it decreases the average response time and increases the throughput of the system.
- SCAN: In the SCAN algorithm the disk arm moves in a particular direction and services the requests coming in its path and after reaching the end of the disk, it reverses its direction and again services the request arriving in its path. So, this algorithm works as an elevator and is hence also known as an elevator algorithm. As a result, the requests at the midrange are serviced more and those arriving behind the disk arm will have to wait.
- C-SCAN: In the SCAN algorithm, the disk arm again scans the path that has been scanned, after reversing its direction. So, it may be possible that too many requests are waiting at the other end or there may be zero or few requests pending at the scanned area.
- LOOK: LOOK Algorithm is similar to the SCAN disk scheduling algorithm except for the difference that the disk arm in spite of going to the end of the disk goes only to the last request to be serviced in front of the head and then reverses its direction from there only. Thus it prevents the extra delay which occurred due to unnecessary traversal to the end of the disk.
- C-LOOK: As LOOK is similar to the SCAN algorithm, in a similar way, C-LOOK is similar to the CSCAN disk scheduling algorithm. In CLOOK, the disk arm in spite of going to the end goes only to the last request to be serviced in front of the head and then from there goes to the other end’s last request. Thus, it also prevents the extra delay which occurred due to unnecessary traversal to the end of the disk.
- LIFO (Last-In First-Out): In LIFO (Last In, First Out) algorithm, the newest jobs are serviced before the existing ones i.e. in order of requests that get serviced the job that is newest or last entered is serviced first, and then the rest in the same order.
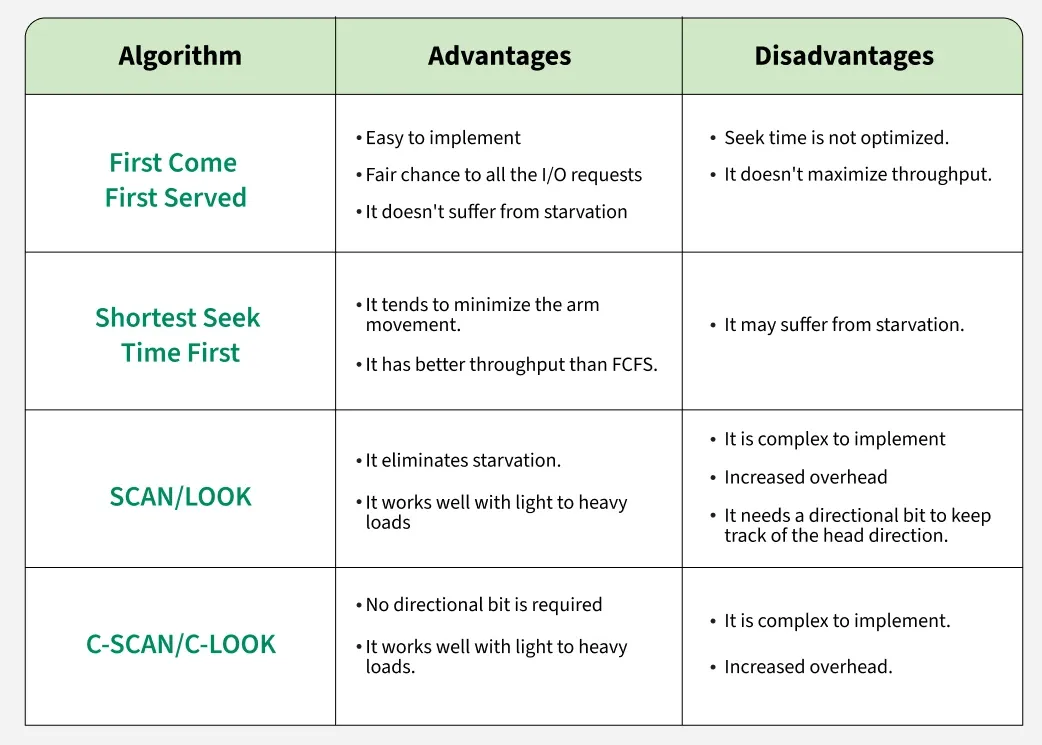
Comparison Among the Disk Scheduling Algorithms
read more about – Disk scheduling algorithms
Similar Reads
Operating System Tutorial
An Operating System(OS) is a software that manages and handles hardware and software resources of a computing device. Responsible for managing and controlling all the activities and sharing of computer resources among different running applications.A low-level Software that includes all the basic fu
4 min read
Structure of Operating System
Types of OS
Batch Processing Operating System
In the beginning, computers were very large types of machinery that ran from a console table. In all-purpose, card readers or tape drivers were used for input, and punch cards, tape drives, and line printers were used for output. Operators had no direct interface with the system, and job implementat
6 min read
Multiprogramming in Operating System
As the name suggests, Multiprogramming means more than one program can be active at the same time. Before the operating system concept, only one program was to be loaded at a time and run. These systems were not efficient as the CPU was not used efficiently. For example, in a single-tasking system,
5 min read
Time Sharing Operating System
Multiprogrammed, batched systems provide an environment where various system resources were used effectively, but it did not provide for user interaction with computer systems. Time-sharing is a logical extension of multiprogramming. The CPU performs many tasks by switches that are so frequent that
5 min read
What is a Network Operating System?
The basic definition of an operating system is that the operating system is the interface between the computer hardware and the user. In daily life, we use the operating system on our devices which provides a good GUI, and many more features. Similarly, a network operating system(NOS) is software th
2 min read
Real Time Operating System (RTOS)
Real-time operating systems (RTOS) are used in environments where a large number of events, mostly external to the computer system, must be accepted and processed in a short time or within certain deadlines. such applications are industrial control, telephone switching equipment, flight control, and
6 min read
Process Management
Introduction of Process Management
Process Management for a single tasking or batch processing system is easy as only one process is active at a time. With multiple processes (multiprogramming or multitasking) being active, the process management becomes complex as a CPU needs to be efficiently utilized by multiple processes. Multipl
8 min read
Process Table and Process Control Block (PCB)
While creating a process, the operating system performs several operations. To identify the processes, it assigns a process identification number (PID) to each process. As the operating system supports multi-programming, it needs to keep track of all the processes. For this task, the process control
6 min read
Operations on Processes
Process operations refer to the actions or activities performed on processes in an operating system. These operations include creating, terminating, suspending, resuming, and communicating between processes. Operations on processes are crucial for managing and controlling the execution of programs i
5 min read
Process Schedulers in Operating System
A process is the instance of a computer program in execution. Scheduling is important in operating systems with multiprogramming as multiple processes might be eligible for running at a time.One of the key responsibilities of an Operating System (OS) is to decide which programs will execute on the C
7 min read
Inter Process Communication (IPC)
Processes need to communicate with each other in many situations, for example, to count occurrences of a word in text file, output of grep command needs to be given to wc command, something like grep -o -i <word> <file> | wc -l. Inter-Process Communication or IPC is a mechanism that allo
5 min read
Context Switching in Operating System
An operating system is a program loaded into a system or computer. and manage all the other program which is running on that OS Program, it manages the all other application programs. or in other words, we can say that the OS is an interface between the user and computer hardware. So in this article
6 min read
Preemptive and Non-Preemptive Scheduling
In operating systems, scheduling is the method by which processes are given access the CPU. Efficient scheduling is essential for optimal system performance and user experience. There are two primary types of CPU scheduling: preemptive and non-preemptive. Understanding the differences between preemp
5 min read
Critical Section Problem Solution
Peterson's Algorithm in Process Synchronization
Peterson's Algorithm is a classic solution to the critical section problem in process synchronization. It ensures mutual exclusion meaning only one process can access the critical section at a time and avoids race conditions. The algorithm uses two shared variables to manage the turn-taking mechanis
15+ min read
Semaphores in Process Synchronization
Semaphores are a tool used in operating systems to help manage how different processes (or programs) share resources, like memory or data, without causing conflicts. A semaphore is a special kind of synchronization data that can be used only through specific synchronization primitives. Semaphores ar
15+ min read
Semaphores and its types
A semaphore is a tool used in computer science to manage how multiple programs or processes access shared resources, like memory or files, without causing conflicts. Semaphores are compound data types with two fields one is a Non-negative integer S.V(Semaphore Value) and the second is a set of proce
6 min read
Producer Consumer Problem using Semaphores | Set 1
The Producer-Consumer problem is a classic synchronization issue in operating systems. It involves two types of processes: producers, which generate data, and consumers, which process that data. Both share a common buffer. The challenge is to ensure that the producer doesn't add data to a full buffe
4 min read
Readers-Writers Problem | Set 1 (Introduction and Readers Preference Solution)
The readers-writer problem in operating systems is about managing access to shared data. It allows multiple readers to read data at the same time without issues but ensures that only one writer can write at a time, and no one can read while writing is happening. This helps prevent data corruption an
8 min read
Dining Philosopher Problem Using Semaphores
The Dining Philosopher Problem states that K philosophers are seated around a circular table with one chopstick between each pair of philosophers. There is one chopstick between each philosopher. A philosopher may eat if he can pick up the two chopsticks adjacent to him. One chopstick may be picked
11 min read
Hardware Synchronization Algorithms : Unlock and Lock, Test and Set, Swap
Process Synchronization problems occur when two processes running concurrently share the same data or same variable. The value of that variable may not be updated correctly before its being used by a second process. Such a condition is known as Race Around Condition. There are a software as well as
5 min read
Deadlocks & Deadlock Handling Methods
Introduction of Deadlock in Operating System
A deadlock is a situation where a set of processes is blocked because each process is holding a resource and waiting for another resource acquired by some other process. In this article, we will discuss deadlock, its necessary conditions, etc. in detail. Deadlock is a situation in computing where tw
11 min read
Conditions for Deadlock in Operating System
A deadlock is a situation where a set of processes is blocked because each process is holding a resource and waiting for another resource acquired by some other process. In this article, we will discuss what deadlock is and the necessary conditions required for deadlock. What is Deadlock?Deadlock is
8 min read
Banker's Algorithm in Operating System
Banker's Algorithm is a resource allocation and deadlock avoidance algorithm used in operating systems. It ensures that a system remains in a safe state by carefully allocating resources to processes while avoiding unsafe states that could lead to deadlocks. The Banker's Algorithm is a smart way for
8 min read
Wait For Graph Deadlock Detection in Distributed System
Deadlocks are a fundamental problem in distributed systems. A process may request resources in any order and a process can request resources while holding others. A Deadlock is a situation where a set of processes are blocked as each process in a Distributed system is holding some resources and that
5 min read
Handling Deadlocks
Deadlock is a situation where a process or a set of processes is blocked, waiting for some other resource that is held by some other waiting process. It is an undesirable state of the system. In other words, Deadlock is a critical situation in computing where a process, or a group of processes, beco
9 min read
Deadlock Prevention And Avoidance
Deadlock prevention and avoidance are strategies used in computer systems to ensure that different processes can run smoothly without getting stuck waiting for each other forever. Think of it like a traffic system where cars (processes) must move through intersections (resources) without getting int
5 min read
Deadlock Detection And Recovery
Deadlock Detection and Recovery is the mechanism of detecting and resolving deadlocks in an operating system. In operating systems, deadlock recovery is important to keep everything running smoothly. A deadlock occurs when two or more processes are blocked, waiting for each other to release the reso
7 min read
Deadlock Ignorance in Operating System
In this article we will study in brief about what is Deadlock followed by Deadlock Ignorance in Operating System. What is Deadlock? If each process in the set of processes is waiting for an event that only another process in the set can cause it is actually referred as called Deadlock. In other word
5 min read
Recovery from Deadlock in Operating System
In today's world of computer systems and multitasking environments, deadlock is an undesirable situation that can bring operations to a halt. When multiple processes compete for exclusive access to resources and end up in a circular waiting pattern, a deadlock occurs. To maintain the smooth function
8 min read