Artificial Intelligence is the study of building agents that act rationally. Most of the time, these agents perform some kind of search algorithm in the background in order to achieve their tasks.
- A search problem consists of:
- A State Space. Set of all possible states where you can be.
- A Start State. The state from where the search begins.
- A Goal State. A function that looks at the current state returns whether or not it is the goal state.
- The Solution to a search problem is a sequence of actions, called the plan that transforms the start state to the goal state.
- This plan is achieved through search algorithms.
Types of search algorithms:
There are far too many powerful search algorithms out there to fit in a single article. Instead, this article will discuss six of the fundamental search algorithms, divided into two categories, as shown below.
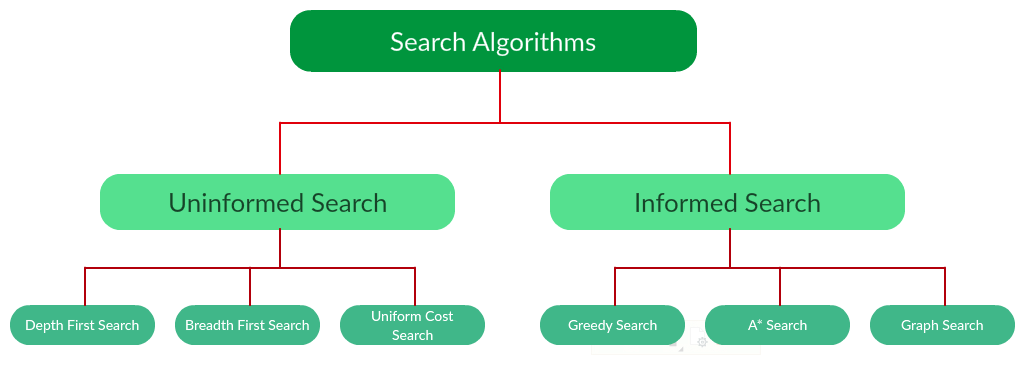
Note that there is much more to search algorithms than the chart I have provided above. However, this article will mostly stick to the above chart, exploring the algorithms given there.
Uninformed Search Algorithms:
The search algorithms in this section have no additional information on the goal node other than the one provided in the problem definition. The plans to reach the goal state from the start state differ only by the order and/or length of actions. Uninformed search is also called Blind search. These algorithms can only generate the successors and differentiate between the goal state and non goal state.
The following uninformed search algorithms are discussed in this section.
- Depth First Search
- Breadth First Search
- Uniform Cost Search
Each of these algorithms will have:
- A problem graph, containing the start node S and the goal node G.
- A strategy, describing the manner in which the graph will be traversed to get to G.
- A fringe, which is a data structure used to store all the possible states (nodes) that you can go from the current states.
- A tree, that results while traversing to the goal node.
- A solution plan, which the sequence of nodes from S to G.
Depth-first search (DFS) is an algorithm for traversing or searching tree or graph data structures. The algorithm starts at the root node (selecting some arbitrary node as the root node in the case of a graph) and explores as far as possible along each branch before backtracking. It uses last in- first-out strategy and hence it is implemented using a stack.
Example:
Question. Which solution would DFS find to move from node S to node G if run on the graph below?
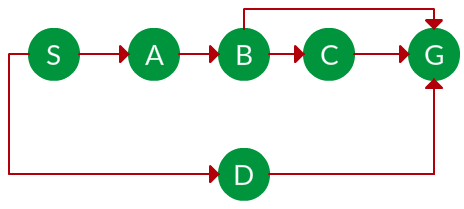
Solution. The equivalent search tree for the above graph is as follows. As DFS traverses the tree “deepest node first”, it would always pick the deeper branch until it reaches the solution (or it runs out of nodes, and goes to the next branch). The traversal is shown in blue arrows.
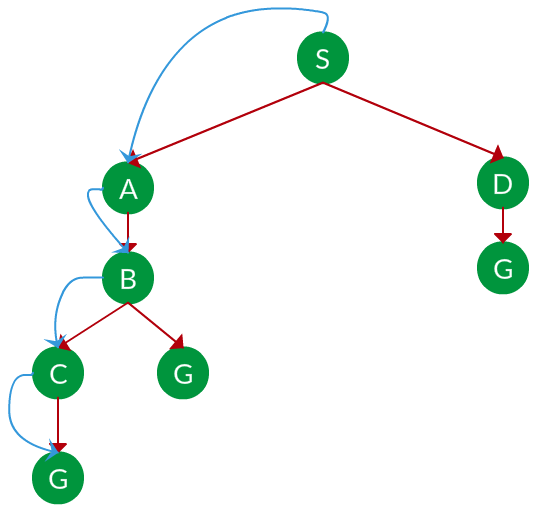
Path: S -> A -> B -> C -> G
 = the depth of the search tree = the number of levels of the search tree.
= the depth of the search tree = the number of levels of the search tree.
 = number of nodes in level
= number of nodes in level  .
.
Time complexity: Equivalent to the number of nodes traversed in DFS. 
Space complexity: Equivalent to how large can the fringe get. 
Completeness: DFS is complete if the search tree is finite, meaning for a given finite search tree, DFS will come up with a solution if it exists.
Optimality: DFS is not optimal, meaning the number of steps in reaching the solution, or the cost spent in reaching it is high.
Breadth-first search (BFS) is an algorithm for traversing or searching tree or graph data structures. It starts at the tree root (or some arbitrary node of a graph, sometimes referred to as a ‘search key’), and explores all of the neighbor nodes at the present depth prior to moving on to the nodes at the next depth level. It is implemented using a queue.
Example:
Question. Which solution would BFS find to move from node S to node G if run on the graph below?
Solution. The equivalent search tree for the above graph is as follows. As BFS traverses the tree “shallowest node first”, it would always pick the shallower branch until it reaches the solution (or it runs out of nodes, and goes to the next branch). The traversal is shown in blue arrows.
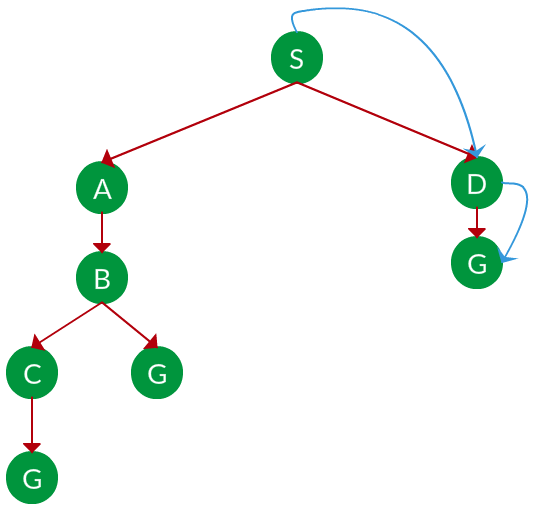
Path: S -> D -> G
 = the depth of the shallowest solution.
= the depth of the shallowest solution.
= number of nodes in level .
Time complexity: Equivalent to the number of nodes traversed in BFS until the shallowest solution. 
Space complexity: Equivalent to how large can the fringe get. 
Completeness: BFS is complete, meaning for a given search tree, BFS will come up with a solution if it exists.
Optimality: BFS is optimal as long as the costs of all edges are equal.
Uniform Cost Search:
UCS is different from BFS and DFS because here the costs come into play. In other words, traversing via different edges might not have the same cost. The goal is to find a path where the cumulative sum of costs is the least.
Cost of a node is defined as:
cost(node) = cumulative cost of all nodes from root
cost(root) = 0
Example:
Question. Which solution would UCS find to move from node S to node G if run on the graph below?
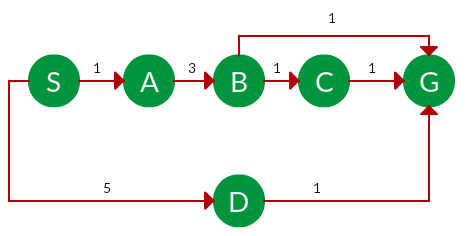
Solution. The equivalent search tree for the above graph is as follows. The cost of each node is the cumulative cost of reaching that node from the root. Based on the UCS strategy, the path with the least cumulative cost is chosen. Note that due to the many options in the fringe, the algorithm explores most of them so long as their cost is low, and discards them when a lower-cost path is found; these discarded traversals are not shown below. The actual traversal is shown in blue.
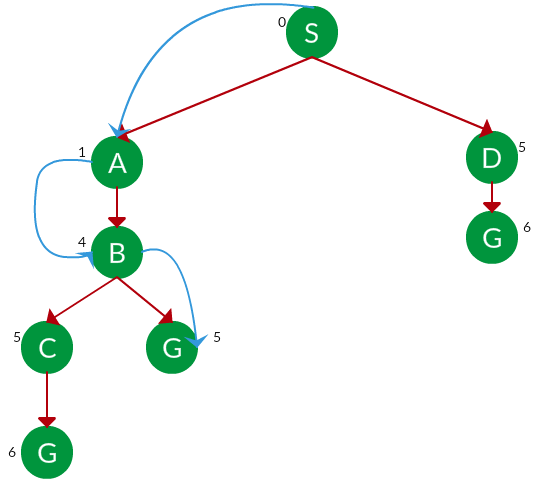
Path: S -> A -> B -> G
Cost: 5
Let  = cost of solution.
= cost of solution.
 = arcs cost.
= arcs cost.
Then  effective depth
effective depth
Time complexity:  , Space complexity:
, Space complexity: 
Advantages:
- UCS is complete only if states are finite and there should be no loop with zero weight.
- UCS is optimal only if there is no negative cost.
Disadvantages:
- Explores options in every “direction”.
- No information on goal location.
Informed Search Algorithms:
Here, the algorithms have information on the goal state, which helps in more efficient searching. This information is obtained by something called a heuristic.
In this section, we will discuss the following search algorithms.
- Greedy Search
- A* Tree Search
- A* Graph Search
Search Heuristics: In an informed search, a heuristic is a function that estimates how close a state is to the goal state. For example – Manhattan distance, Euclidean distance, etc. (Lesser the distance, closer the goal.) Different heuristics are used in different informed algorithms discussed below.
Greedy Search:
In greedy search, we expand the node closest to the goal node. The “closeness” is estimated by a heuristic h(x).
Heuristic: A heuristic h is defined as-
h(x) = Estimate of distance of node x from the goal node.
Lower the value of h(x), closer is the node from the goal.
Strategy: Expand the node closest to the goal state, i.e. expand the node with a lower h value.
Example:
Question. Find the path from S to G using greedy search. The heuristic values h of each node below the name of the node.
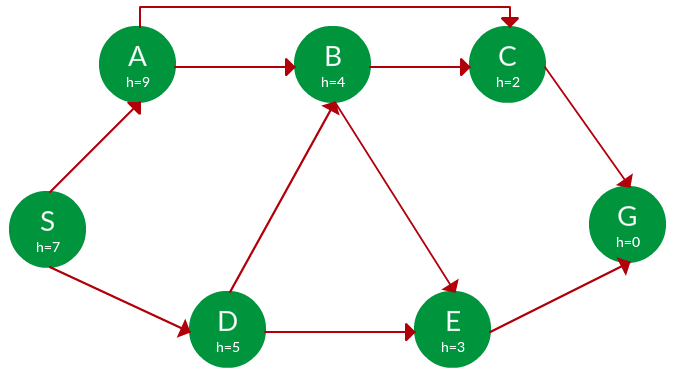
Solution. Starting from S, we can traverse to A(h=9) or D(h=5). We choose D, as it has the lower heuristic cost. Now from D, we can move to B(h=4) or E(h=3). We choose E with a lower heuristic cost. Finally, from E, we go to G(h=0). This entire traversal is shown in the search tree below, in blue.
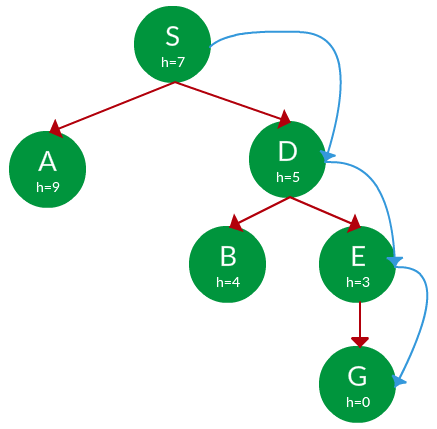
Path: S -> D -> E -> G
Advantage: Works well with informed search problems, with fewer steps to reach a goal.
Disadvantage: Can turn into unguided DFS in the worst case.
A* Tree Search:
A* Tree Search, or simply known as A* Search, combines the strengths of uniform-cost search and greedy search. In this search, the heuristic is the summation of the cost in UCS, denoted by g(x), and the cost in the greedy search, denoted by h(x). The summed cost is denoted by f(x).
Heuristic: The following points should be noted wrt heuristics in A* search. 
- Here, h(x) is called the forward cost and is an estimate of the distance of the current node from the goal node.
- And, g(x) is called the backward cost and is the cumulative cost of a node from the root node.
- A* search is optimal only when for all nodes, the forward cost for a node h(x) underestimates the actual cost h*(x) to reach the goal. This property of A* heuristic is called admissibility.
Admissibility:

Strategy: Choose the node with the lowest f(x) value.
Example:
Question. Find the path to reach from S to G using A* search.
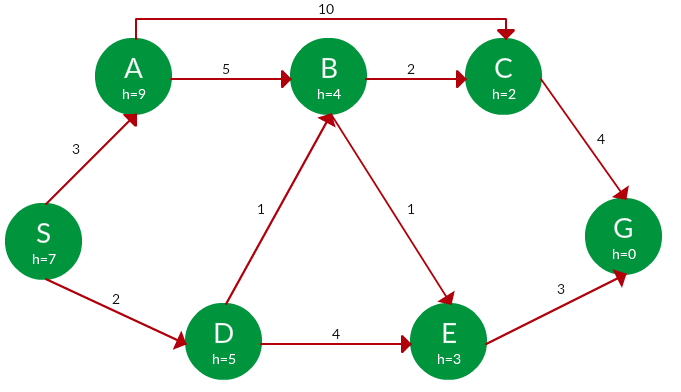
Solution. Starting from S, the algorithm computes g(x) + h(x) for all nodes in the fringe at each step, choosing the node with the lowest sum. The entire work is shown in the table below.
Note that in the fourth set of iterations, we get two paths with equal summed cost f(x), so we expand them both in the next set. The path with a lower cost on further expansion is the chosen path.
| Path | h(x) | g(x) | f(x) |
|---|
| S | 7 | 0 | 7 |
|---|
| | | | |
|---|
| S -> A | 9 | 3 | 12 |
|---|
| S -> D ✔ | 5 | 2 | 7 |
|---|
| | | | |
|---|
| S -> D -> B ✔ | 4 | 2 + 1 = 3 | 7 |
|---|
| S -> D -> E | 3 | 2 + 4 = 6 | 9 |
|---|
| | | | |
|---|
| S -> D -> B -> C ✔ | 2 | 3 + 2 = 5 | 7 |
|---|
| S -> D -> B -> E ✔ | 3 | 3 + 1 = 4 | 7 |
|---|
| | | | |
|---|
| S -> D -> B -> C -> G | 0 | 5 + 4 = 9 | 9 |
|---|
| S -> D -> B -> E -> G ✔ | 0 | 4 + 3 = 7 | 7 |
|---|
Path: S -> D -> B -> E -> G
Cost: 7
- A* tree search works well, except that it takes time re-exploring the branches it has already explored. In other words, if the same node has expanded twice in different branches of the search tree, A* search might explore both of those branches, thus wasting time
- A* Graph Search, or simply Graph Search, removes this limitation by adding this rule: do not expand the same node more than once.
- Heuristic. Graph search is optimal only when the forward cost between two successive nodes A and B, given by h(A) – h (B), is less than or equal to the backward cost between those two nodes g(A -> B). This property of the graph search heuristic is called consistency.
Consistency:

Example:
Question. Use graph searches to find paths from S to G in the following graph.
the Solution. We solve this question pretty much the same way we solved last question, but in this case, we keep a track of nodes explored so that we don’t re-explore them.

Path: S -> D -> B -> E -> G
Cost: 7
Similar Reads
Artificial Intelligence Tutorial | AI Tutorial
Artificial Intelligence (AI) refers to the simulation of human intelligence in machines that are programmed to think and act like humans. It involves the development of algorithms and computer programs that can perform tasks that typically require human intelligence such as visual perception, speech
7 min read
What is Artificial Intelligence?
What is Artificial Intelligence? In today's rapidly advancing technological landscape, AI has become a household term. From chatbots and virtual assistants to self-driving cars and recommendation algorithms, the impact of AI is ubiquitous. But what exactly is AI and how does it work? At its core, Ar
15+ min read
History of AI
The term Artificial Intelligence (AI) is already widely used in everything from smartphones to self-driving cars. AI has come a long way from science fiction stories to practical uses. Yet What is artificial intelligence and how did it go from being an idea in science fiction to a technology that re
7 min read
Agents in Artificial Intelligence
In artificial intelligence, an agent is a computer program or system that is designed to perceive its environment, make decisions and take actions to achieve a specific goal or set of goals. The agent operates autonomously, meaning it is not directly controlled by a human operator. Agents can be cla
11 min read
Problem Solving in AI
Search Algorithms in AI
Artificial Intelligence is the study of building agents that act rationally. Most of the time, these agents perform some kind of search algorithm in the background in order to achieve their tasks. A search problem consists of: A State Space. Set of all possible states where you can be.A Start State.
10 min read
Uninformed Search Algorithms in AI
Uninformed search algorithms are a class of search algorithms that do not have any additional information about the problem other than what is given in the problem definition. They are also known as blind search algorithms. In Artificial Intelligence (AI), search algorithms play a crucial role in fi
8 min read
Informed Search Algorithms in Artificial Intelligence
Informed search algorithms, also known as heuristic search algorithms, are an essential component of Artificial Intelligence (AI). These algorithms use domain-specific knowledge to improve the efficiency of the search process, leading to faster and more optimal solutions compared to uninformed searc
10 min read
Local Search Algorithm in Artificial Intelligence
Local search algorithms are essential tools in artificial intelligence and optimization, employed to find high-quality solutions in large and complex problem spaces. Key algorithms include Hill-Climbing Search, Simulated Annealing, Local Beam Search, Genetic Algorithms, and Tabu Search. Each of thes
4 min read
Adversarial Search Algorithms in Artificial Intelligence (AI)
Adversarial search algorithms are the backbone of strategic decision-making in artificial intelligence, it enables the agents to navigate competitive scenarios effectively. This article offers concise yet comprehensive advantages of these algorithms from their foundational principles to practical ap
15+ min read
Constraint Satisfaction Problems (CSP) in Artificial Intelligence
Constraint Satisfaction Problems (CSP) play a crucial role in artificial intelligence (AI) as they help solve various problems that require decision-making under certain constraints. CSPs represent a class of problems where the goal is to find a solution that satisfies a set of constraints. These pr
14 min read
Knowledge, Reasoning and Planning in AI
How do knowledge representation and reasoning techniques support intelligent systems?
In artificial intelligence (AI), knowledge representation and reasoning (KR&R) stands as a fundamental pillar, crucial for enabling machines to emulate complex decision-making and problem-solving abilities akin to those of humans. This article explores the intricate relationship between KR&R
5 min read
First-Order Logic in Artificial Intelligence
First-order logic (FOL), also known as predicate logic or first-order predicate calculus, is a powerful framework used in various fields such as mathematics, philosophy, linguistics, and computer science. In artificial intelligence (AI), FOL plays a crucial role in knowledge representation, automate
6 min read
Types of Reasoning in Artificial Intelligence
In today's tech-driven world, machines are being designed to mimic human intelligence and actions. One key aspect of this is reasoning, a logical process that enables machines to conclude, make predictions, and solve problems just like humans. Artificial Intelligence (AI) employs various types of re
6 min read
What is the Role of Planning in Artificial Intelligence?
Artificial Intelligence (AI) is reshaping the future, playing a pivotal role in domains like intelligent robotics, self-driving cars, and smart cities. At the heart of AI systems’ ability to perform tasks autonomously is AI planning, which is critical in guiding AI systems to make informed decisions
7 min read
Representing Knowledge in an Uncertain Domain in AI
Artificial Intelligence (AI) systems often operate in environments where uncertainty is a fundamental aspect. Representing and reasoning about knowledge in such uncertain domains is crucial for building robust and intelligent systems. This article explores the various methods and techniques used in
6 min read
Learning in AI
Supervised Machine Learning
Supervised machine learning is a fundamental approach for machine learning and artificial intelligence. It involves training a model using labeled data, where each input comes with a corresponding correct output. The process is like a teacher guiding a student—hence the term "supervised" learning. I
12 min read
What is Unsupervised Learning?
Unsupervised learning is a branch of machine learning that deals with unlabeled data. Unlike supervised learning, where the data is labeled with a specific category or outcome, unsupervised learning algorithms are tasked with finding patterns and relationships within the data without any prior knowl
8 min read
Semi-Supervised Learning in ML
Today's Machine Learning algorithms can be broadly classified into three categories, Supervised Learning, Unsupervised Learning, and Reinforcement Learning. Casting Reinforced Learning aside, the primary two categories of Machine Learning problems are Supervised and Unsupervised Learning. The basic
4 min read
Reinforcement Learning
Reinforcement Learning (RL) is a branch of machine learning that focuses on how agents can learn to make decisions through trial and error to maximize cumulative rewards. RL allows machines to learn by interacting with an environment and receiving feedback based on their actions. This feedback comes
6 min read
Self-Supervised Learning (SSL)
In this article, we will learn a major type of machine learning model which is Self-Supervised Learning Algorithms. Usage of these algorithms has increased widely in the past times as the sizes of the model have increased up to billions of parameters and hence require a huge corpus of data to train
8 min read
Introduction to Deep Learning
Deep Learning is transforming the way machines understand, learn, and interact with complex data. Deep learning mimics neural networks of the human brain, it enables computers to autonomously uncover patterns and make informed decisions from vast amounts of unstructured data. Deep Learning leverages
8 min read
Natural Language Processing (NLP) - Overview
The meaning of NLP is Natural Language Processing (NLP) which is a fascinating and rapidly evolving field that intersects computer science, artificial intelligence, and linguistics. NLP focuses on the interaction between computers and human language, enabling machines to understand, interpret, and g
12 min read
Computer Vision Tutorial
Computer Vision is a branch of Artificial Intelligence (AI) that enables computers to interpret and extract information from images and videos, similar to human perception. It involves developing algorithms to process visual data and derive meaningful insights. Why Learn Computer Vision?High Demand
8 min read
Artificial Intelligence in Robotics
Artificial Intelligence (AI) in robotics is one of the most groundbreaking technological advancements, revolutionizing how robots perform tasks. What was once a futuristic concept from space operas, the idea of "artificial intelligence robots" is now a reality, shaping industries globally. Unlike ea
10 min read