
Spanner
Immer aktive Datenbank mit praktisch unbegrenzter Skalierung
Erstellen Sie intelligente Anwendungen mit einer einzigen Datenbank, die relationale, Grafik-, Schlüsselwert- und Suchfunktionen vereint. Keine Wartungsfenster bedeuten unterbrechungsfreie geschäftskritische Anwendungen.
Darüber hinaus erhalten neue Google Cloud-Kunden ein Guthaben im Wert von 300 $.

Features
Unbegrenzte Schreib- und Leseskalierbarkeit

Automatisierte Wartung
Cloud Spanner Graph
Verborgene Beziehungen und Verbindungen aufdecken Cloud Spanner Graph unterstützt ISO Graph Query Language (GQL), die neuen internationalen Standards für Grafikdatenbanken, die eine intuitive und präzise Möglichkeit zum Abgleichen von Mustern und zum Durchlaufen von Beziehungen in Ihren Daten bietet. Es kombiniert die Stärken von SQL und GQL, sodass Sie strukturierte und verbundene Daten in einem einzigen Vorgang abfragen können. Cloud Spanner Graph in der Vorabversion arbeitet mit Volltext- und Vektorsuchfunktionen zusammen, sodass Sie eine neue Klasse KI-gestützter Anwendungen bereitstellen können.
Vektorsuche
Sie können in Cloud Spanner Vektoreinbettungen praktisch unbegrenzt mit KNN (exakter nächster Nachbar) und ANN-Vektoren (beide in der Vorabversion) für hochgradig partitionierbare Arbeitslasten durchsuchen. Die integrierte Unterstützung für die Vektorsuche in Cloud Spanner macht separate, spezialisierte Vektordatenbanklösungen überflüssig. Sie bietet Transaktionsgarantien für Betriebsdaten sowie aktuelle und konsistente Ergebnisse der Vektorsuche in einer serverlosen Architektur mit horizontaler Skalierung und ganz ohne Verwaltung.

PostgreSQL-Oberfläche

Automatische Datenbankfragmentierung
Geo-Partitionierung
Behalten Sie die Verwaltung Ihrer einzigen, globalen Datenbank bei und verbessern Sie gleichzeitig die Latenz für Nutzer, die auf der ganzen Welt verteilt sind. Mit der Geopartitionierung in Spanner können Sie Ihre Tabellendaten weltweit auf Zeilenebene partitionieren, um Daten näher an Ihren Nutzern bereitzustellen. Obwohl die Daten in verschiedene Datenpartitionen aufgeteilt werden, behält Spanner alle Ihre verteilten Daten als eine zusammenhängende Tabelle für Abfragen und Mutationen bei.
Einzel-, Dual- und multiregionale Konfigurationen
Unabhängig davon, wo sich Ihre Nutzer befinden, können von Cloud Spanner unterstützte Anwendungen weltweit aktuelle, strikt konsistente Daten lesen und schreiben. Bei einer multiregionalen Instanz ist Ihre Datenbank außerdem gegen einen regionalen Ausfall geschützt und bietet eine branchenführende Verfügbarkeit von 99,999 %.
Strikte transaktionale Konsistenz
Von Arbeitslasten isolierte Abfrageverarbeitung mit hoher Leistung
Mit Spanner Data Boost können Nutzer Analyseabfragen, Batchverarbeitungsjobs oder Datenexportvorgänge schneller ausführen, ohne die vorhandene Transaktionsarbeitslast zu beeinträchtigen. Data Boost wird vollständig von Google Cloud verwaltet und erfordert keine Kapazitätsplanung oder ‑verwaltung. Es ist immer verfügbar und kann Nutzeranfragen direkt für Daten verarbeiten, die im verteilten Speichersystem von Spanner, Colossus, gespeichert sind. Diese unabhängige On-Demand-Computing-Ressource ermöglicht es Nutzern, problemlos gemischte Arbeitslasten und eine sorgenfreie Datenfreigabe zu bewältigen.

Volltextsuche
Mit der leistungsstarken Textsuche, die auf Erkenntnissen der Google Suche basiert, werden separate Suchtools und die zugehörigen ETL-Pipelines (Extrahieren, Transformieren und Laden) überflüssig. Die Volltextsuche bietet transaktional konsistente Suchergebnisse sowie leistungsstarke Funktionen wie die phonetische Suche und einen NGRAM-basierten Abgleich für Rechtschreibvarianten. Weitere Informationen finden Sie in diesem Whitepaper
LangChain-Integration
Dank der LangChain-Integration können Sie ganz einfach Gen-AI-Anwendungen erstellen, die genauer, transparenter und zuverlässiger sind. Spanner bietet drei LangChain-Integrationen: ein Dokument-Ladeprogramm zum Laden und Speichern von Informationen aus Dokumenten, einen Vektorspeicher zum Aktivieren der semantischen Suche und einen Speicher für Chat-Nachrichten, mit dem Ketten frühere Unterhaltungen abrufen können. Weitere Informationen finden Sie im GitHub-Repository.
Vertex AI-Integrationen
Führen Sie mit der SQL-Funktion ML.PREDICT von Spanner Online-Inferenzen für Einbettungen, Generative AI oder benutzerdefinierte Modelle aus, die in Vertex AI bereitgestellt werden. Verwenden Sie den Workflow für Spanner to Vertex AI Vector Search, um mit Vertex AI Vector Search eine Ähnlichkeitssuche für Ihre Cloud Spanner-Daten durchzuführen.
Datenbankcenter
Sie erhalten einen umfassenden Überblick über Ihre gesamte Datenbankflotte, die mehrere Engines, Versionen, Regionen, Projekte und Umgebungen umfasst.Das Database Center in der Vorabversion hilft Ihnen, das Risiko Ihrer Flotte mit intelligenten Leistungs- und Sicherheitsempfehlungen proaktiv zu senken. Wenn Gemini aktiviert ist, lässt sich mit Database Center Ihre Datenbankflotte unglaublich intuitiv optimieren. Über eine Chatoberfläche in natürlicher Sprache können Sie Fragen stellen, Flottenprobleme schnell beheben und Optimierungsempfehlungen erhalten.
Sicherung und Wiederherstellung, Wiederherstellung zu einem bestimmten Zeitpunkt (PITR)
Sicherheit und Kontrolle für Unternehmen
Datenbankvergleich
| Datenbankattribut | Andere relationale Datenbank | Andere nicht relationale Datenbank | Spanner |
|---|---|---|---|
Schema | Statisch | Dynamisch | Dynamisch |
SQL | Ja | Nein | Ja |
Transaktionen | ACID (Atomarität, Konsistenz, Isolation, Langlebigkeit) | Möglich | Striktes ACID mit TrueTime-Ordnung |
Skalierbarkeit | Vertikal (verwenden Sie einen größeren Computer) | Horizontal (weitere Computer hinzufügen) | Horizontal |
Verfügbarkeit | Failover (Ausfallzeit) | Hoch | Hohes 99,999% SLA |
Replikation | Konfigurierbar | Konfigurierbar | Automatisch |
Schema
Statisch
Dynamisch
Dynamisch
SQL
Ja
Nein
Ja
Transaktionen
ACID
(Atomarität, Konsistenz, Isolation, Langlebigkeit)
Möglich
Striktes ACID
mit TrueTime-Ordnung
Skalierbarkeit
Vertikal
(verwenden Sie einen größeren Computer)
Horizontal
(weitere Computer hinzufügen)
Horizontal
Verfügbarkeit
Failover (Ausfallzeit)
Hoch
Hohes 99,999% SLA
Replikation
Konfigurierbar
Konfigurierbar
Automatisch
Funktionsweise
Cloud Spanner-Instanzen bieten Rechen- und Speicherressourcen in einer oder mehreren Regionen. Eine verteilte Uhr namens TrueTime sorgt dafür, dass Transaktionen auch über Regionen hinweg strikt konsistent sind. Daten werden aus Gründen der Skalierbarkeit automatisch „geteilt“ und mit einem synchronen Paxos-basierten Schema für die Verfügbarkeit repliziert.
Cloud Spanner-Instanzen bieten Rechen- und Speicherressourcen in einer oder mehreren Regionen. Eine verteilte Uhr namens TrueTime sorgt dafür, dass Transaktionen auch über Regionen hinweg strikt konsistent sind. Daten werden aus Gründen der Skalierbarkeit automatisch „geteilt“ und mit einem synchronen Paxos-basierten Schema für die Verfügbarkeit repliziert.
Gängige Einsatzmöglichkeiten
Nutzerprofil und Berechtigungen
Kritische Nutzerdaten sicher verwalten bei jeder Skalierung

Tutorials, Kurzanleitungen und Labs
Kritische Nutzerdaten sicher verwalten bei jeder Skalierung
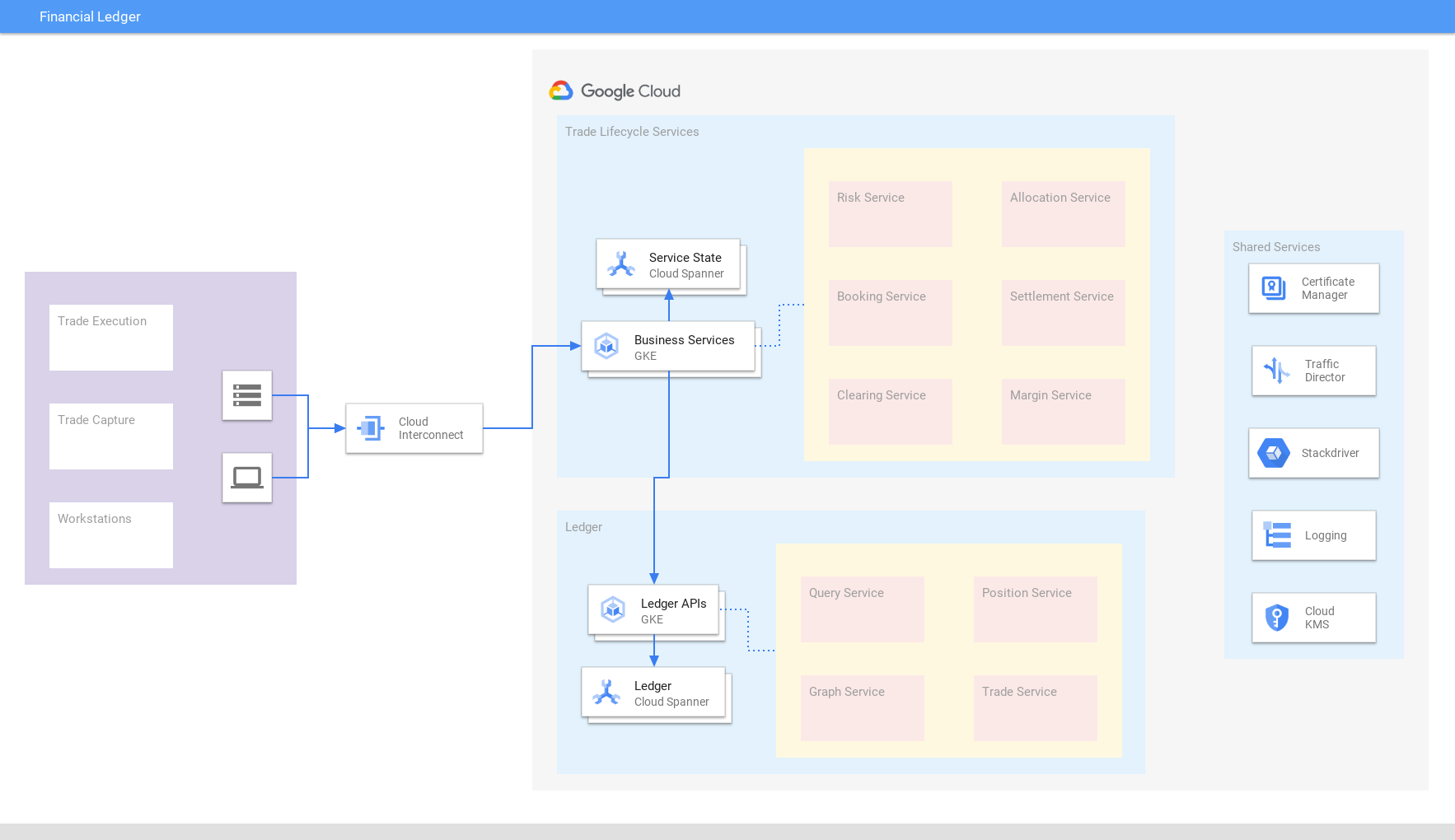
Finanzverzeichnis
Aktueller, einheitlicher Überblick über globale Transaktionen
Führen Sie Finanztransaktionen, Handelsgeschäfte, Settlements und Positionen weltweit zu einem konsolidierten, in Cloud Spanner erstellten Handelsverzeichnis zusammen, das externe Konsistenz und Skalierbarkeit sicherstellt. Die Konsolidierung von Daten ermöglicht eine schnelle Anpassung an sich verändernde Marktbedingungen und behördliche Anforderungen. In ähnlicher Weise verwenden Einzelhandels-/E-Commerce-Unternehmen Spanner für das Inventar-Verzeichnis.
Tutorials, Kurzanleitungen und Labs
Aktueller, einheitlicher Überblick über globale Transaktionen
Führen Sie Finanztransaktionen, Handelsgeschäfte, Settlements und Positionen weltweit zu einem konsolidierten, in Cloud Spanner erstellten Handelsverzeichnis zusammen, das externe Konsistenz und Skalierbarkeit sicherstellt. Die Konsolidierung von Daten ermöglicht eine schnelle Anpassung an sich verändernde Marktbedingungen und behördliche Anforderungen. In ähnlicher Weise verwenden Einzelhandels-/E-Commerce-Unternehmen Spanner für das Inventar-Verzeichnis.
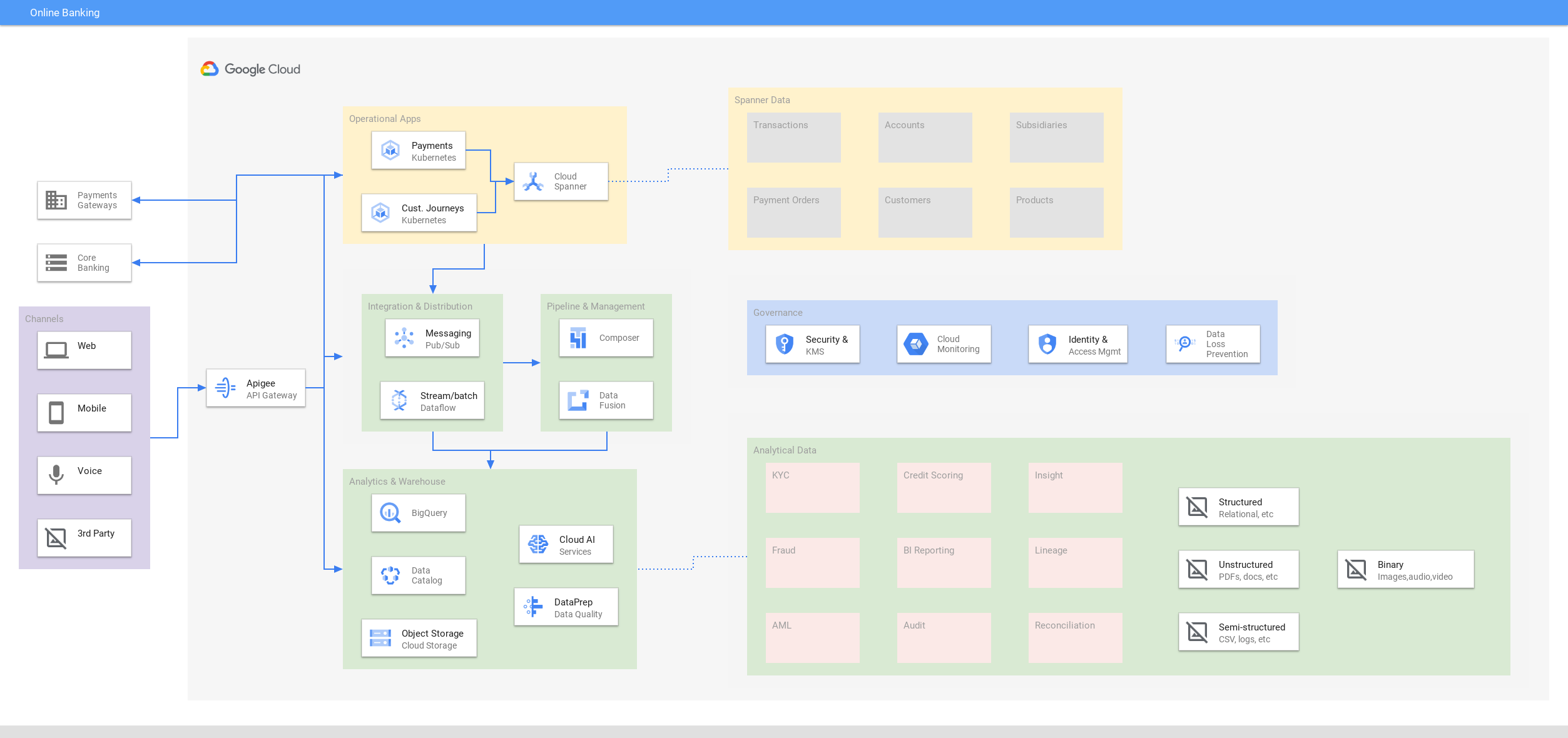
Onlinebanking
Durchgehend aktive interaktive Funktionen für digitale Angebote bereitstellen
Tutorials, Kurzanleitungen und Labs
Durchgehend aktive interaktive Funktionen für digitale Angebote bereitstellen
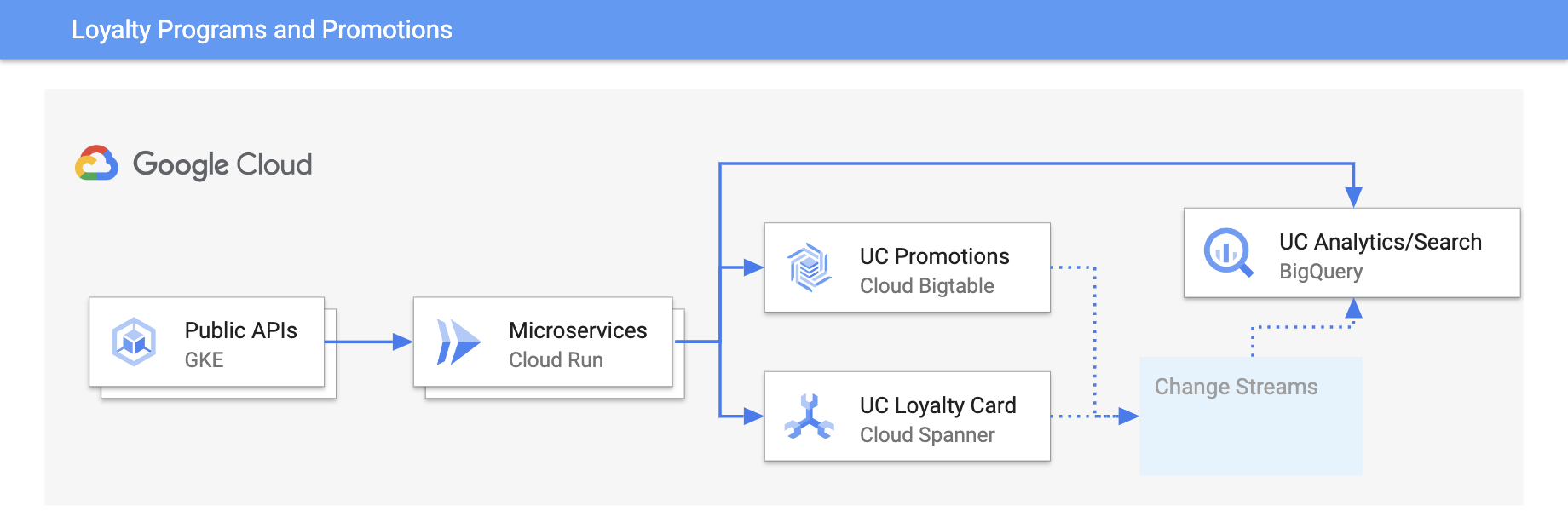
Treuepunkteprogramme und Werbeaktionen
Erlebnisse mit Echtzeit-Updates personalisieren
Tutorials, Kurzanleitungen und Labs
Erlebnisse mit Echtzeit-Updates personalisieren
Omni-Channel-Inventarverwaltung
Einheitliche Ansicht über mehrere Kanäle und Apps hinweg
Cloud Spanner bietet eine leistungsstarke Single Source Of Truth (SSOT) für den Bestand und Bestellungen im Einzelhandel, sowohl online als auch im Ladengeschäft, in Vertriebszentren und beim Versand, um das Inventar mit der Nachfrage abzugleichen und die Kundenerfahrung und die Profitabilität zu verbessern. Spieleunternehmen nutzen Cloud Spanner zum Speichern von In-Game-Inventardaten.
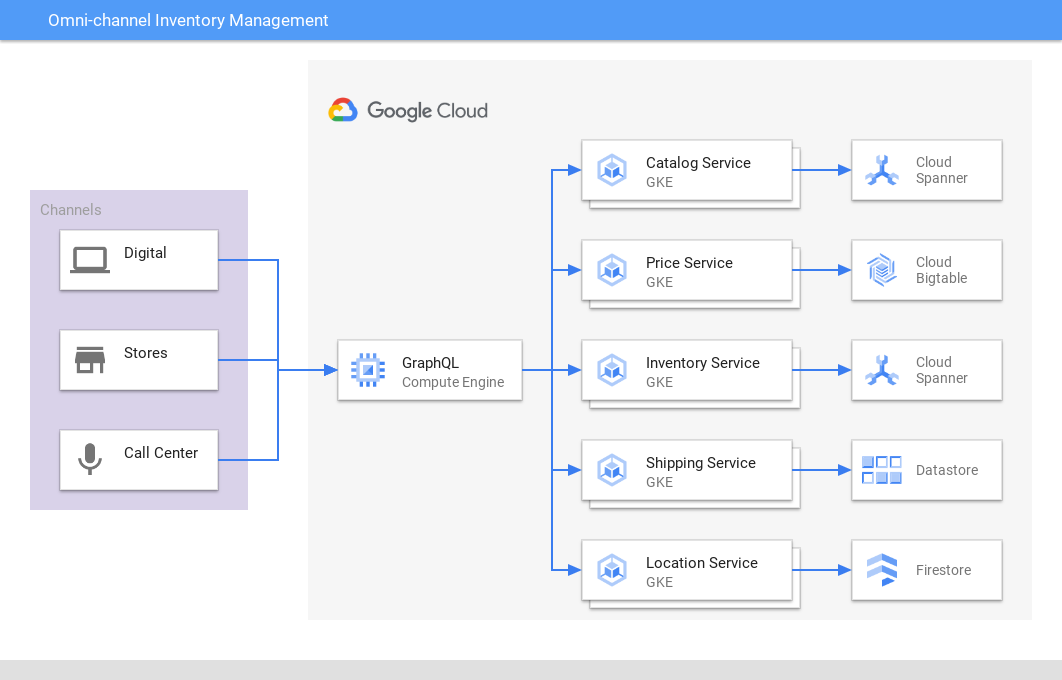
Tutorials, Kurzanleitungen und Labs
Einheitliche Ansicht über mehrere Kanäle und Apps hinweg
Cloud Spanner bietet eine leistungsstarke Single Source Of Truth (SSOT) für den Bestand und Bestellungen im Einzelhandel, sowohl online als auch im Ladengeschäft, in Vertriebszentren und beim Versand, um das Inventar mit der Nachfrage abzugleichen und die Kundenerfahrung und die Profitabilität zu verbessern. Spieleunternehmen nutzen Cloud Spanner zum Speichern von In-Game-Inventardaten.
Knowledge Graph
Versteckte Beziehungen und Verbindungen in Ihren Daten aufdecken
Versteckte Beziehungen und Verbindungen in Ihren Daten aufdecken
Mit Cloud Spanner Graph können Sie Knowledge Graphs entwickeln, die die komplexen Verbindungen zwischen Entitäten in Form von Knoten und deren Beziehungen als Kanten erfassen. Diese Verbindungen bieten umfassenden Kontext, wodurch Knowledge Graphs für die Entwicklung von Wissensdatenbanksystemen und Empfehlungssystemen von unschätzbarem Wert werden. Mit den integrierten Suchfunktionen können Sie semantisches Verständnis, keywordbasierte Abrufe und Grafiken nahtlos kombinieren, um umfassende Ergebnisse zu erhalten.
Tutorials, Kurzanleitungen und Labs
Versteckte Beziehungen und Verbindungen in Ihren Daten aufdecken
Versteckte Beziehungen und Verbindungen in Ihren Daten aufdecken
Mit Cloud Spanner Graph können Sie Knowledge Graphs entwickeln, die die komplexen Verbindungen zwischen Entitäten in Form von Knoten und deren Beziehungen als Kanten erfassen. Diese Verbindungen bieten umfassenden Kontext, wodurch Knowledge Graphs für die Entwicklung von Wissensdatenbanksystemen und Empfehlungssystemen von unschätzbarem Wert werden. Mit den integrierten Suchfunktionen können Sie semantisches Verständnis, keywordbasierte Abrufe und Grafiken nahtlos kombinieren, um umfassende Ergebnisse zu erhalten.
Preise
| Spanner-Preise | Die Spanner-Preise basieren auf Rechenkapazität, Spanner Data Boost, Datenbankspeicher, Sicherungsspeicher, Replikation und Netzwerknutzung. Die Computing-Preise variieren je nach Version und Konfiguration. Rabatte für zugesicherte Nutzung können den Computing-Preis weiter senken. | |
|---|---|---|
| Dienst | Beschreibung | Preis ($) |
Compute | Standard Edition Vollgepackt mit einer umfassenden Suite etablierter Funktionen für regionale Konfigurationen (einzelne Regionen) Rechenkapazität wird als Verarbeitungseinheiten oder Knoten bereitgestellt (1 Knoten = 1.000 Verarbeitungseinheiten). | Starting at 0,030 $ pro 100 Verarbeitungseinheiten pro Stunde und Replikat |
Enterprise Edition Bereitstellung zusätzlicher Suchfunktionen für mehrere Modelle und erweiterte Suchfunktionen mit einfacher und effizienter Bedienung Rechenkapazität wird als Verarbeitungseinheiten oder Knoten bereitgestellt (1 Knoten = 1.000 Verarbeitungseinheiten). | Starting at 0,041 $ pro 100 Verarbeitungseinheiten pro Stunde und Replikat | |
Enterprise Plus Edition Unterstützung der anspruchsvollsten Arbeitslasten mit höchster Verfügbarkeit, Leistung, Compliance und Governance Rechenkapazität wird als Verarbeitungseinheiten oder Knoten bereitgestellt (1 Knoten = 1.000 Verarbeitungseinheiten). | Starting at 0,057 $ pro 100 Verarbeitungseinheiten pro Stunde und Replikat | |
Data Boost | Isolierte On-Demand-Rechenressourcen, einschließlich CPU, Arbeitsspeicher und lokale Datenübertragung | Starting at 0,00117 $ pro serverloser Verarbeitungseinheit pro Stunde |
Datenbankspeicher | Der Preis basiert auf der in der Datenbank gespeicherten Datenmenge und beinhaltet die Speicherkosten in nicht schreibgeschützten und schreibgeschützten Replikaten. Das Zeugenreplikat ist kostenlos. | Starting at 0,10 $ pro GB pro Monat und Replikat |
Sicherungsspeicher | Regionale Konfiguration Die Preise richten sich nach der Menge des Sicherungsspeichers. Sie beinhalten die Speicherkosten aller Replikate. | Starting at 0,10 $ pro GB und Monat (einschließlich aller Replikate) |
Dual- und multiregionale Konfiguration Die Preise richten sich nach der Menge des Sicherungsspeichers. Sie beinhalten die Speicherkosten aller Replikate. | Starting at 0,30 $ pro GB und Monat (einschließlich aller Replikate) | |
Replikation | Intraregionale Replikation | Kostenlos |
Interregionale Replikation | Starting at 0,04 $ pro GB | |
Netzwerk | Eingehender Traffic | Kostenlos |
Intraregionaler ausgehender Traffic | Kostenlos | |
Interregionaler ausgehender Traffic | Starting at 0,01 $ pro GB | |
Weitere Informationen zu den Cloud Spanner-Preisen und den Rabatten für zugesicherte Nutzung.
Spanner-Preise
Die Spanner-Preise basieren auf Rechenkapazität, Spanner Data Boost, Datenbankspeicher, Sicherungsspeicher, Replikation und Netzwerknutzung. Die Computing-Preise variieren je nach Version und Konfiguration. Rabatte für zugesicherte Nutzung können den Computing-Preis weiter senken.
Standard Edition
Vollgepackt mit einer umfassenden Suite etablierter Funktionen für regionale Konfigurationen (einzelne Regionen)
Rechenkapazität wird als Verarbeitungseinheiten oder Knoten bereitgestellt (1 Knoten = 1.000 Verarbeitungseinheiten).
Starting at
0,030 $
pro 100 Verarbeitungseinheiten pro Stunde und Replikat
Enterprise Edition
Bereitstellung zusätzlicher Suchfunktionen für mehrere Modelle und erweiterte Suchfunktionen mit einfacher und effizienter Bedienung
Rechenkapazität wird als Verarbeitungseinheiten oder Knoten bereitgestellt (1 Knoten = 1.000 Verarbeitungseinheiten).
Starting at
0,041 $
pro 100 Verarbeitungseinheiten pro Stunde und Replikat
Enterprise Plus Edition
Unterstützung der anspruchsvollsten Arbeitslasten mit höchster Verfügbarkeit, Leistung, Compliance und Governance
Rechenkapazität wird als Verarbeitungseinheiten oder Knoten bereitgestellt (1 Knoten = 1.000 Verarbeitungseinheiten).
Starting at
0,057 $
pro 100 Verarbeitungseinheiten pro Stunde und Replikat
Data Boost
Isolierte On-Demand-Rechenressourcen, einschließlich CPU, Arbeitsspeicher und lokale Datenübertragung
Starting at
0,00117 $
pro serverloser Verarbeitungseinheit pro Stunde
Datenbankspeicher
Der Preis basiert auf der in der Datenbank gespeicherten Datenmenge und beinhaltet die Speicherkosten in nicht schreibgeschützten und schreibgeschützten Replikaten. Das Zeugenreplikat ist kostenlos.
Starting at
0,10 $
pro GB pro Monat und Replikat
Sicherungsspeicher
Regionale Konfiguration
Die Preise richten sich nach der Menge des Sicherungsspeichers. Sie beinhalten die Speicherkosten aller Replikate.
Starting at
0,10 $
pro GB und Monat (einschließlich aller Replikate)
Dual- und multiregionale Konfiguration
Die Preise richten sich nach der Menge des Sicherungsspeichers. Sie beinhalten die Speicherkosten aller Replikate.
Starting at
0,30 $
pro GB und Monat (einschließlich aller Replikate)
Replikation
Intraregionale Replikation
Kostenlos
Interregionale Replikation
Starting at
0,04 $
pro GB
Netzwerk
Eingehender Traffic
Kostenlos
Intraregionaler ausgehender Traffic
Kostenlos
Interregionaler ausgehender Traffic
Starting at
0,01 $
pro GB
Weitere Informationen zu den Cloud Spanner-Preisen und den Rabatten für zugesicherte Nutzung.
PREISRECHNER
INDIVIDUELLES ANGEBOT
Proof of Concept starten
90-tägige Spanner-Instanz kostenlos erstellen
Informationen zur Verwendung von Cloud Spanner
Datenbank in der Console erstellen und abfragen
Best Practices zum Erstellen von SQL-Anweisungen
Mit Beispielen ins Programmieren eintauchen
Anwendungsszenario
Erfahren Sie, wie andere Unternehmen mit Spanner innovative Apps entwickelt haben, um eine hervorragende Nutzererfahrung zu bieten, die Kosten zu senken und den ROI zu steigern.

So skaliert Uber auf Millionen von gleichzeitigen Anfragen
So hat Uber seine Plattform für die Auftragsausführung mithilfe von Spanner neu gestaltet.
Video ansehen


Vorteile und Kunden
Bauen Sie Ihr Unternehmen aus mit innovativen Anwendungen, die sich unbegrenzt skalieren lassen, um alle Anforderungen zu erfüllen.
Geringere Gesamtbetriebskosten und Ihre Entwickler müssen nicht schwerfällige Abläufe bewältigen, sodass sie groß träumen und schneller entwickeln können.
Hervorragendes Preis-Leistungs-Verhältnis und zahlen Sie für nur das, was Sie nutzen – schon ab 40 $ pro Monat.







Partner und Integration
Nutzen Sie Partner mit Spanner-Fachkenntnissen, um Sie bei jedem Schritt der Reise zu unterstützen – von Bewertungen und Anwendungsszenario bis hin zu Migrationen und der Entwicklung neuer Anwendungen auf Spanner.











Systemintegratoren
Spanner-Partner unterstützen Sie bei der Modernisierung von Anwendungen und der nahtlosen Migration in die Cloud. Suchen Sie in unserem Verzeichnis nach der idealen Partner- oder Drittanbieterintegration.
FAQs
Ist Cloud Spanner eine relationale oder eine nicht relationale Datenbank?
Cloud Spanner vereinfacht Ihre Datenarchitektur, indem es relationale, Schlüssel/Wert-Paar-, Graph- und Vektorsucharbeitslasten in einer einzigen Datenbank zusammenführt. Cloud Spanner ist eine hoch skalierbare Datenbank, die unbegrenzte Skalierbarkeit mit relationaler Semantik kombiniert. Dazu gehören sekundäre Indexe, strikte Konsistenz, Schemas und SQL, die eine Verfügbarkeit von 99,999 % in einer einfachen Lösung bieten. Daher ist es sowohl für relationale als auch für nicht relationale Arbeitslasten geeignet.
Verwendet Cloud Spanner SQL?
Cloud Spanner bietet zwei ANSI-basierte SQL-Dialekte für denselben umfassenden Satz an Funktionen: GoogleSQL und PostgreSQL. Google SQL teilt Syntax mit BigQuery damit Teams ihre Workflows zur Datenverwaltung standardisieren können. Die PostgreSQL-Oberfläche bietet Vertrautheit für Teams, die PostgreSQL kennen, sowie die Portabilität von Schemas und Abfragen in andere PostgreSQL-Umgebungen. Weitere Informationen zur PostgreSQL-Oberfläche von Cloud Spanner finden Sie in der Dokumentation.
Wie migriere ich Datenbanken zu Spanner?
Die Migration zu Cloud Spanner kann aufgrund verschiedener Faktoren stark variieren. Dazu gehören die Quelldatenbank, die Datengröße, Ausfallzeitenanforderungen, die Komplexität des Anwendungscodes, Fragmentierungsschema, benutzerdefinierte Funktionen oder Transformationen, Failover- und Replikationsstrategie. Zu den empfohlenen Tools gehören Open-Source-Tools wie das Cloud Spanner-Migrationstool für die Schema- und Datenmigration sowie Tools von Drittanbietern für Bewertungen wie migVisor. Weitere Informationen zum Migrationsprozess finden Sie in unserer Dokumentation.
Was sind die wichtigsten Überlegungen zum Einsatz von Spanner?
Spanner ist eine vollständig verwaltete Datenbank, die automatisch umfassende Features zur Infrastrukturverwaltung bereitstellt. Je nach Arbeitslast sind jedoch möglicherweise einige anwendungsspezifische Verwaltungsaktionen erforderlich. Sie müssen daher Benachrichtigungen und Monitoring ordnungsgemäß einrichten und diese genau beobachten, damit die Produktion immer reibungslos verläuft. Sie müssen wissen, welche Maßnahmen Sie ergreifen müssen, wenn der Traffic im Laufe der Zeit organisch zunimmt oder ob Sie Traffic-Spitzen erwarten. Außerdem müssen Sie wissen, wie Sie mit Datenbeschädigungen aufgrund von Anwendungsfehlern umgehen und wie Sie Leistungsprobleme beheben und Sie müssen verstehen, welche Komponenten für erhöhte Latenzen verantwortlich sind.





















