
Spanner
Base de datos siempre disponible con una escala prácticamente ilimitada
Compila apps inteligentes con una sola base de datos que reúna los datos relacionales, de gráficos, de pares clave-valor y de búsqueda. Cuando no hay períodos de mantenimiento, significa que las apps esenciales funcionan sin interrupciones.
Además, los clientes nuevos de Google Cloud obtienen $300 en créditos gratuitos.

Funciones
Escalabilidad de lectura y escritura sin límites

Mantenimiento automatizado
Spanner Graph
Revela conexiones y relaciones ocultas. Spanner Graph es compatible con el lenguaje ISO Graph Query Language (GQL), el nuevos estándar internacional para las bases de datos de gráficos, que ofrecen una forma intuitiva y concisa de hacer coincidir patrones y analizar las relaciones en tus datos. Combina las fortalezas de SQL y GQL, lo que te permite consultar datos estructurados y conectados en una sola operación. Spanner Graph, en versión preliminar, opera conjuntamente con las capacidades de búsqueda de texto completo y de vectores, lo que te permite ofrecer una nueva clase de aplicaciones potenciadas por IA.
Búsqueda de vectores
Busca incorporaciones de vectores a una escala prácticamente ilimitada en Spanner con la búsqueda de vectores de vecino más cercano exacto (KNN) y vecino más cercano aproximado (ANN) (ambas en versión preliminar) para cargas de trabajo altamente particionables. La compatibilidad integrada con la búsqueda de vectores en Spanner elimina la necesidad de soluciones de bases de datos de vectores especializadas y separadas, lo que proporciona garantías transaccionales de datos operativos y resultados de búsqueda vectoriales nuevos y coherentes en una arquitectura sin servidores escalable y sin administración.

Interfaz de PostgreSQL

Fragmentación automática de la base de datos
Partición geográfica
Conserva la capacidad de administración de tu base de datos única y global, a la vez que mejoras la latencia para los usuarios de todo el mundo. La partición geográfica en Spanner te permite particionar los datos de las tablas a nivel de las filas en todo el mundo para entregar datos más cerca de los usuarios. Aunque los datos se dividen en diferentes particiones, Spanner mantiene todos los datos distribuidos como una única tabla coherente para consultas y mutaciones.
Configuraciones regionales, birregionales y multirregionales
Independientemente de dónde se encuentren tus usuarios, las apps que tengan el respaldo de Cloud Spanner pueden leer y escribir datos actualizados, con coherencia sólida, a nivel mundial. Además, cuando se ejecuta una instancia birregional o multirregional, tu base de datos puede soportar una falla regional y ofrecer una disponibilidad líder en la industria de un 99.999%.
Coherencia sólida de las transacciones
Procesamiento de consultas de alto rendimiento y aislado de la carga de trabajo
Spanner Data Boost permite a los usuarios ejecutar consultas analíticas, trabajos de procesamiento por lotes, o bien operaciones de exportación de datos más rápido sin afectar la carga de trabajo transaccional existente. Data Boost es un recurso completamente administrado por Google Cloud que no requiere planificación ni administración de la capacidad. Siempre está activo y listo para procesar las consultas de los usuarios directamente en los datos almacenados en el sistema de almacenamiento distribuido de Spanner, Colossus. Este recurso de procesamiento independiente y a pedido permite a los usuarios administrar con facilidad cargas de trabajo mixtas y compartir datos sin preocupaciones.

Búsqueda en el texto completo
Elimina las herramientas de búsqueda independientes y las canalizaciones de extracción, transformación y carga (ETL) asociadas gracias a la búsqueda de texto de alto rendimiento potenciada con la información de la Búsqueda de Google. La búsqueda en el texto completo proporciona resultados de búsqueda coherentes de forma transaccional, junto con funciones eficaces, como la búsqueda fonética y la concordancia basada en NGRAM para las variaciones ortográficas. Para obtener más información, consulta este informe.
Integración de LangChain
Compila fácilmente aplicaciones de IA generativa que sean más precisas, transparentes y confiables con la integración de LangChain. Spanner tiene tres integraciones de LangChain: cargador de documentos para cargar y almacenar información de documentos, almacenes de vectores para habilitar la búsqueda semántica y memoria de mensajes de chat para permitir que las cadenas recuperen conversaciones anteriores. Visita el repositorio de GitHub para obtener más información.
Integraciones de Vertex AI
Realiza inferencias en línea sobre incorporaciones, IA generativa o modelos personalizados que se entregan en Vertex AI con la función en SQL ML.PREDICT de Spanner. Usar el flujo de trabajo de Spanner a la Búsqueda de vectores de Vertex AI para realizar una búsqueda de similitud en los datos de Spanner con la Búsqueda de vectores de Vertex AI.
Centro de bases de datos
Obtén una vista integral de toda tu flota de bases de datos, que abarca varios motores, versiones, regiones, proyectos y entornos. Database Center, en versión preliminar, ayuda a reducir proactivamente los riesgos de tu flota con recomendaciones de rendimiento y seguridad inteligentes. Con Gemini habilitado, Database Center hace que optimizar tu flota de bases de datos sea increíblemente intuitivo. Usa una interfaz de chat de lenguaje natural para hacer preguntas, resolver problemas de la flota con rapidez y obtener recomendaciones de optimización.
Copia de seguridad y restablecimiento, recuperación de un momento determinado (PITR)
Seguridad y controles de nivel empresarial
Comparación de bases de datos
| Atributo de la base de datos | Otra base de datos relacional | Otra base de datos no relacional | Spanner |
|---|---|---|---|
Esquema | Estática | Dinámica | Dinámica |
SQL | Sí | No | Sí |
Transacciones | ACID (atomicidad, coherencia, aislamiento y durabilidad) | Eventual | Ácido fuerte con ordenamiento de TrueTime |
Escalabilidad | Vertical (usar una máquina más grande) | Horizontal (agregar más máquinas) | Horizontal |
Disponibilidad | Conmutación por error (tiempo de inactividad) | Alta | ANS alto del 99.999% |
Replicación | Configurable | Configurable | Automático |
Esquema
Estática
Dinámica
Dinámica
SQL
Sí
No
Sí
Transacciones
ACID
(atomicidad, coherencia, aislamiento y durabilidad)
Eventual
Ácido fuerte
con ordenamiento de TrueTime
Escalabilidad
Vertical
(usar una máquina más grande)
Horizontal
(agregar más máquinas)
Horizontal
Disponibilidad
Conmutación por error (tiempo de inactividad)
Alta
ANS alto del 99.999%
Replicación
Configurable
Configurable
Automático
Cómo funciona
Las instancias de Spanner proporcionan procesamiento y almacenamiento en una o más regiones. Un reloj distribuido llamado TrueTime garantiza que las transacciones tengan una coherencia sólida incluso en todas las regiones. Los datos se “dividen” automáticamente para la escalabilidad y se replican mediante un esquema síncrono basado en Paxos para la disponibilidad.
Las instancias de Spanner proporcionan procesamiento y almacenamiento en una o más regiones. Un reloj distribuido llamado TrueTime garantiza que las transacciones tengan una coherencia sólida incluso en todas las regiones. Los datos se “dividen” automáticamente para la escalabilidad y se replican mediante un esquema síncrono basado en Paxos para la disponibilidad.
Usos comunes
Perfil del usuario y derechos
Administra datos fundamentales del usuario de forma segura a cualquier escala

Instructivos, guías de inicio rápido y labs
Administra datos fundamentales del usuario de forma segura a cualquier escala
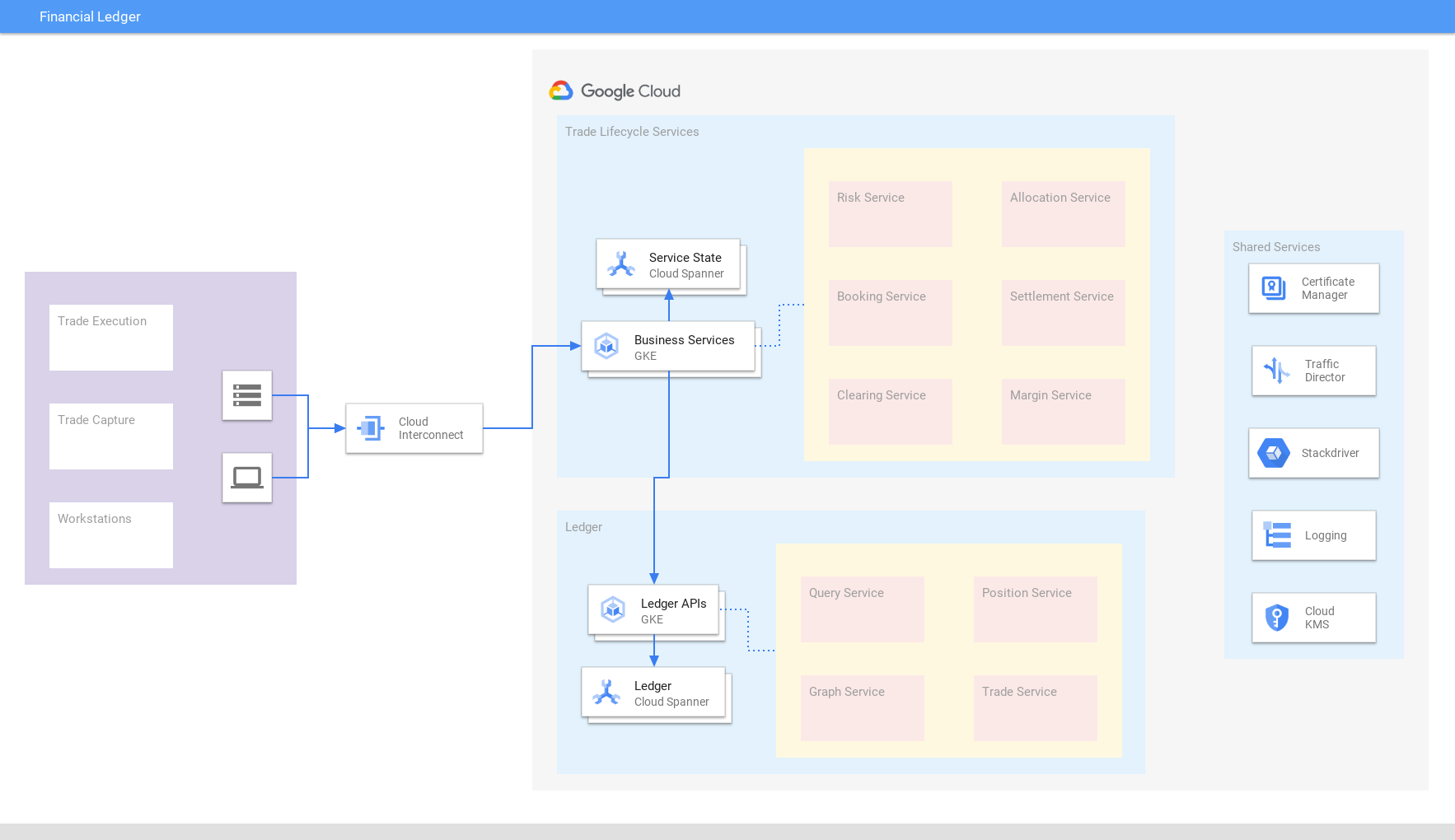
Registro financiero
Obtén una vista actualizada y coherente de las transacciones globales
Unifica transacciones, liquidaciones y posiciones financieras en todo el mundo en un registro comercial consolidado de Spanner que garantice la coherencia y escalabilidad externas. La consolidación de datos ayuda a adaptarse rápidamente a los cambios en las condiciones del mercado y los requisitos normativos. Del mismo modo, las empresas minoristas y de comercio electrónico usan Spanner para el registro de inventario.
Instructivos, guías de inicio rápido y labs
Obtén una vista actualizada y coherente de las transacciones globales
Unifica transacciones, liquidaciones y posiciones financieras en todo el mundo en un registro comercial consolidado de Spanner que garantice la coherencia y escalabilidad externas. La consolidación de datos ayuda a adaptarse rápidamente a los cambios en las condiciones del mercado y los requisitos normativos. Del mismo modo, las empresas minoristas y de comercio electrónico usan Spanner para el registro de inventario.
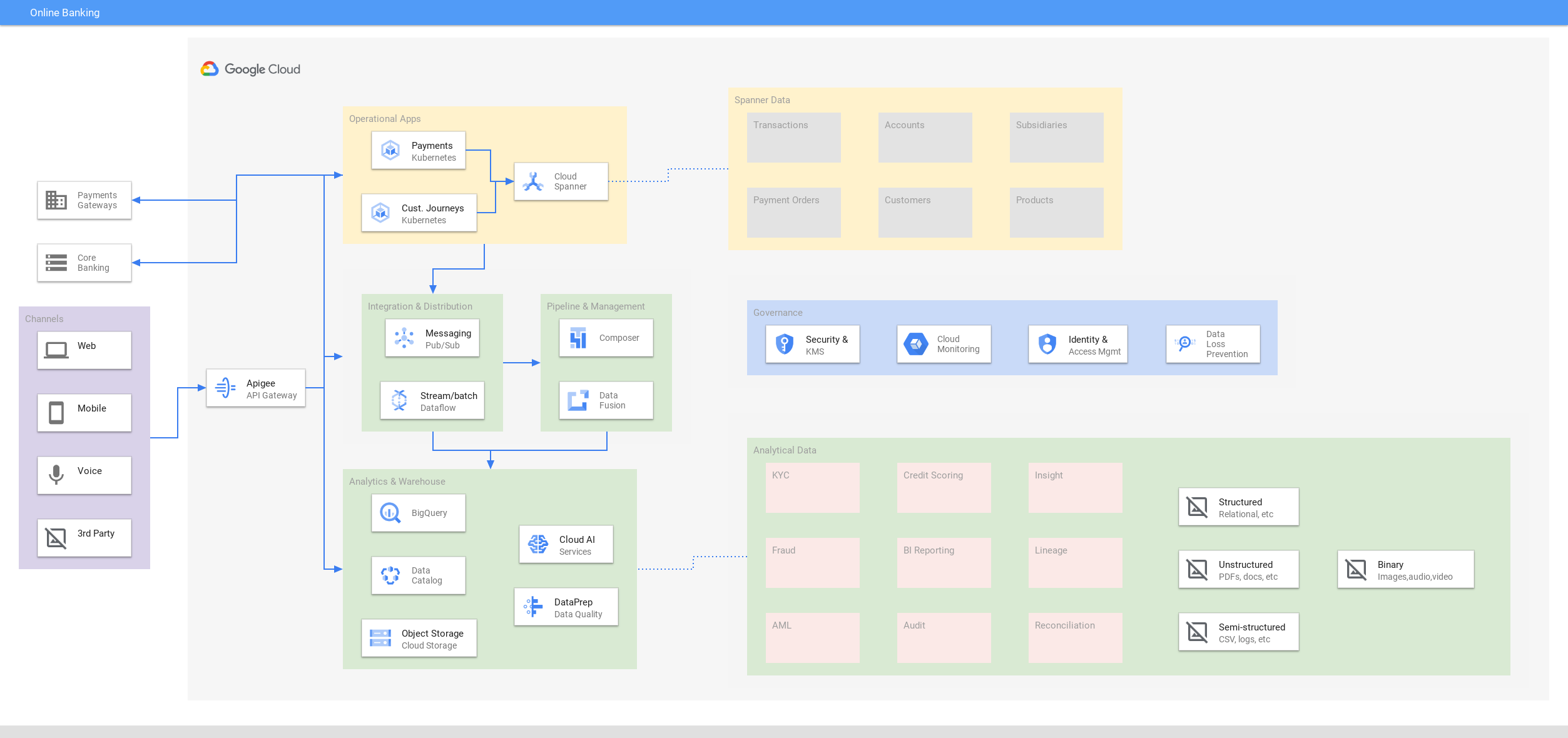
Banca en línea
Ofrece interactividad siempre activa para experiencias digitales
Instructivos, guías de inicio rápido y labs
Ofrece interactividad siempre activa para experiencias digitales
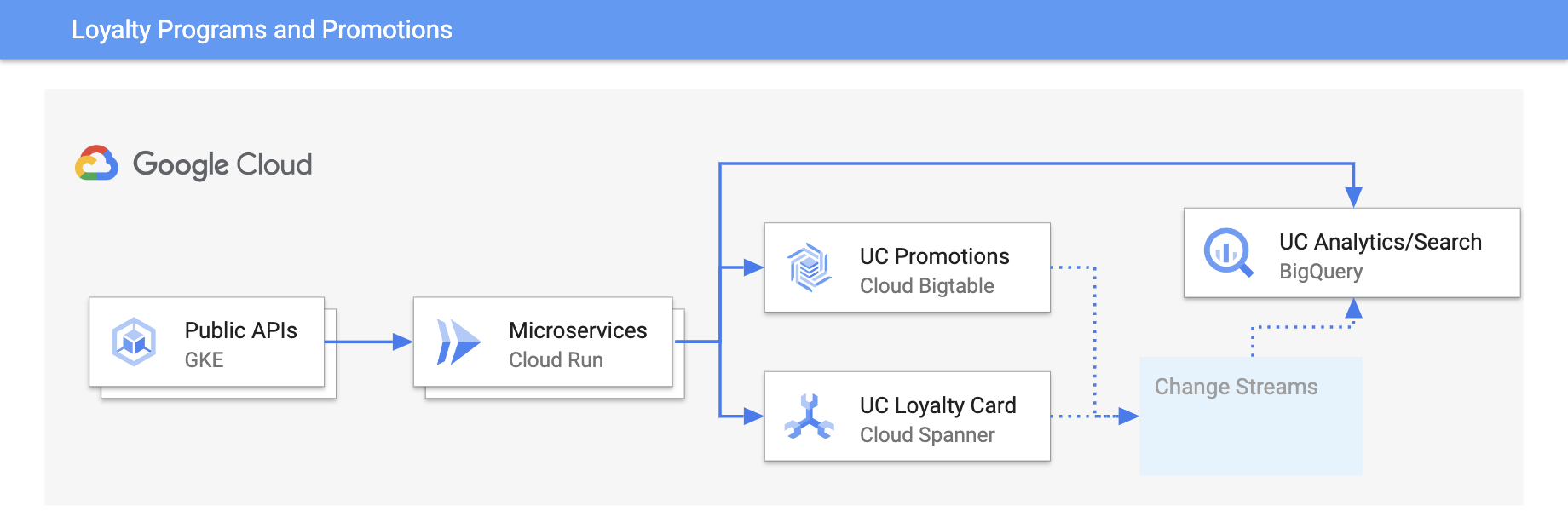
Programas de lealtad y promociones
Personaliza las experiencias con actualizaciones en tiempo real
Instructivos, guías de inicio rápido y labs
Personaliza las experiencias con actualizaciones en tiempo real
Administración del inventario en varios canales
Proporciona una vista coherente en varios canales y apps
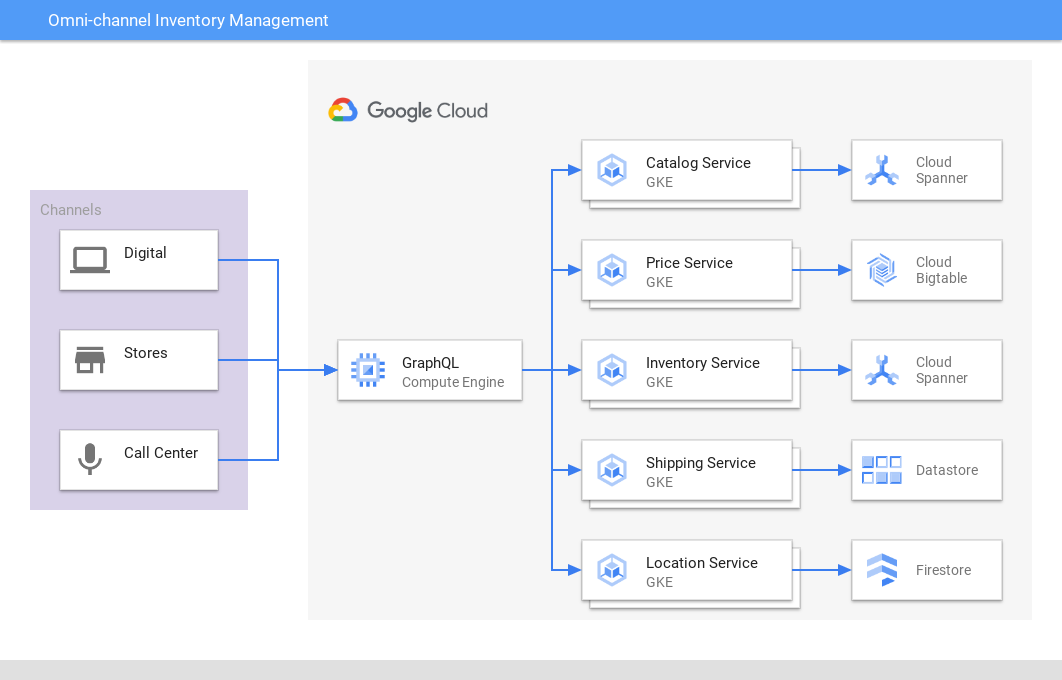
Spanner proporciona una fuente de confianza única y de alto rendimiento para el inventario de venta minorista y los pedidos en centros de distribución en línea, en la tienda y en la distribución, y a fin de combinar el inventario con la demanda para mejorar al cliente, experiencia y rentabilidad. De manera similar, las empresas de videojuegos usan Spanner para almacenar datos de inventario dentro del juego.
Instructivos, guías de inicio rápido y labs
Proporciona una vista coherente en varios canales y apps
Spanner proporciona una fuente de confianza única y de alto rendimiento para el inventario de venta minorista y los pedidos en centros de distribución en línea, en la tienda y en la distribución, y a fin de combinar el inventario con la demanda para mejorar al cliente, experiencia y rentabilidad. De manera similar, las empresas de videojuegos usan Spanner para almacenar datos de inventario dentro del juego.
Gráfico de conocimiento
Revela conexiones y relaciones ocultas en tus datos
Revela conexiones y relaciones ocultas en tus datos
Con Spanner Graph, puedes desarrollar gráficos de conocimiento que capturen las conexiones complejas entre entidades, representadas como nodos, y sus relaciones, representadas como aristas. Estas conexiones proporcionan un contexto amplio, lo que hace que los gráficos de conocimiento sean muy valiosos para el desarrollo de sistemas de base de conocimiento y motores de recomendaciones. Gracias a las capacidades de búsqueda integradas, puedes combinar sin problemas la comprensión semántica, la recuperación basada en palabras clave y los gráficos para obtener resultados exhaustivos.
Instructivos, guías de inicio rápido y labs
Revela conexiones y relaciones ocultas en tus datos
Revela conexiones y relaciones ocultas en tus datos
Con Spanner Graph, puedes desarrollar gráficos de conocimiento que capturen las conexiones complejas entre entidades, representadas como nodos, y sus relaciones, representadas como aristas. Estas conexiones proporcionan un contexto amplio, lo que hace que los gráficos de conocimiento sean muy valiosos para el desarrollo de sistemas de base de conocimiento y motores de recomendaciones. Gracias a las capacidades de búsqueda integradas, puedes combinar sin problemas la comprensión semántica, la recuperación basada en palabras clave y los gráficos para obtener resultados exhaustivos.
Precios
| Cómo funcionan los precios de Spanner | Los precios de Spanner se basan en la capacidad de procesamiento, Spanner Data Boost, el almacenamiento de la base de datos, el almacenamiento de copias de seguridad, la replicación y el uso de la red. Los precios de procesamiento varían según la edición y la configuración seleccionadas. Los descuentos por compromiso de uso pueden reducir aún más el precio del procesamiento. | |
|---|---|---|
| Servicio | Descripción | Precio (USD) |
Procesamiento | Edición estándar Incluye un paquete completo de funciones establecidas para configuraciones regionales (de una sola región) La capacidad de procesamiento se aprovisiona como unidades de procesamiento o nodos (1 nodo = 1,000 unidades de procesamiento). | Starting at $0.030 por 100 unidades de procesamiento por hora por réplica |
Edición Enterprise Proporcionar capacidades de búsqueda avanzadas y con varios modelos adicionales con una mayor simplicidad y eficiencia operativa La capacidad de procesamiento se aprovisiona como unidades de procesamiento o nodos (1 nodo = 1,000 unidades de procesamiento). | Starting at $0.041 por 100 unidades de procesamiento por hora por réplica | |
Edición Enterprise Plus Admite las cargas de trabajo más exigentes con los niveles más altos de disponibilidad, rendimiento, cumplimiento y administración La capacidad de procesamiento se aprovisiona como unidades de procesamiento o nodos (1 nodo = 1,000 unidades de procesamiento). | Starting at $0.057 por 100 unidades de procesamiento por hora por réplica | |
Data Boost | Recursos de procesamiento aislados y a pedido, incluidos CPU, memoria y transferencia de datos local | Starting at $0.00117 por unidad de procesamiento sin servidores por hora |
Almacenamiento en bases de datos | El precio se basa en la cantidad de datos almacenados en la base de datos y también incluye el costo de almacenamiento en réplicas de lectura y escritura y de solo lectura; la réplica de testigo es gratuita. | Starting at $0.10 por GB al mes por réplica |
Almacenamiento en copias de seguridad | Configuración regional Los precios se basan en la cantidad de almacenamiento de copia de seguridad y también incluyen el costo del almacenamiento en todas las réplicas. | Starting at $0.10 por GB al mes (incluidas todas las réplicas) |
Configuración birregional y multirregional Los precios se basan en la cantidad de almacenamiento de copia de seguridad y también incluyen el costo del almacenamiento en todas las réplicas. | Starting at $0.30 por GB al mes (incluidas todas las réplicas) | |
Replicación | Replicación dentro de la región | Gratis |
Replicación interregionales | Starting at $0.04 por GB | |
Red | Entrada | Gratis |
Salida dentro de la región | Gratis | |
Salida interregional | Starting at $0.01 por GB | |
Obtén más información sobre los precios y los descuentos por compromiso de uso de Spanner.
Cómo funcionan los precios de Spanner
Los precios de Spanner se basan en la capacidad de procesamiento, Spanner Data Boost, el almacenamiento de la base de datos, el almacenamiento de copias de seguridad, la replicación y el uso de la red. Los precios de procesamiento varían según la edición y la configuración seleccionadas. Los descuentos por compromiso de uso pueden reducir aún más el precio del procesamiento.
Edición estándar
Incluye un paquete completo de funciones establecidas para configuraciones regionales (de una sola región)
La capacidad de procesamiento se aprovisiona como unidades de procesamiento o nodos (1 nodo = 1,000 unidades de procesamiento).
Starting at
$0.030
por 100 unidades de procesamiento por hora por réplica
Edición Enterprise
Proporcionar capacidades de búsqueda avanzadas y con varios modelos adicionales con una mayor simplicidad y eficiencia operativa
La capacidad de procesamiento se aprovisiona como unidades de procesamiento o nodos (1 nodo = 1,000 unidades de procesamiento).
Starting at
$0.041
por 100 unidades de procesamiento por hora por réplica
Edición Enterprise Plus
Admite las cargas de trabajo más exigentes con los niveles más altos de disponibilidad, rendimiento, cumplimiento y administración
La capacidad de procesamiento se aprovisiona como unidades de procesamiento o nodos (1 nodo = 1,000 unidades de procesamiento).
Starting at
$0.057
por 100 unidades de procesamiento por hora por réplica
Data Boost
Recursos de procesamiento aislados y a pedido, incluidos CPU, memoria y transferencia de datos local
Starting at
$0.00117
por unidad de procesamiento sin servidores por hora
Almacenamiento en bases de datos
El precio se basa en la cantidad de datos almacenados en la base de datos y también incluye el costo de almacenamiento en réplicas de lectura y escritura y de solo lectura; la réplica de testigo es gratuita.
Starting at
$0.10
por GB al mes por réplica
Almacenamiento en copias de seguridad
Configuración regional
Los precios se basan en la cantidad de almacenamiento de copia de seguridad y también incluyen el costo del almacenamiento en todas las réplicas.
Starting at
$0.10
por GB al mes (incluidas todas las réplicas)
Configuración birregional y multirregional
Los precios se basan en la cantidad de almacenamiento de copia de seguridad y también incluyen el costo del almacenamiento en todas las réplicas.
Starting at
$0.30
por GB al mes (incluidas todas las réplicas)
Replicación
Replicación dentro de la región
Gratis
Replicación interregionales
Starting at
$0.04
por GB
Red
Entrada
Gratis
Salida dentro de la región
Gratis
Salida interregional
Starting at
$0.01
por GB
Obtén más información sobre los precios y los descuentos por compromiso de uso de Spanner.
CALCULADORA DE PRECIOS
COTIZACIÓN PERSONALIZADA
Comienza tu prueba de concepto
Crea una instancia de Spanner de 90 días de forma gratuita
Aprende a usar Spanner
Crea y consulta una base de datos en la consola
Prácticas recomendadas para crear instrucciones de SQL
Explora la programación con ejemplos
Caso empresarial
Explora cómo otras empresas crearon aplicaciones innovadoras para brindar excelentes experiencias del cliente, reducir costos y aumentar el ROI con Spanner

¿Cómo se escala Uber a millones de solicitudes simultáneas?
Descubre cómo Uber rediseñó su plataforma de entrega aprovechando Spanner.
Mirar el video


Clientes y beneficios destacados
Haz crecer tu negocio con aplicaciones innovadoras que escalan sin límites para satisfacer cualquier demanda.
Reduce el TCO y libera a los desarrolladores de las operaciones complicadas para que sueñen en grande y compilen más rápido.
Obtén un precio y rendimiento superiores, y paga por lo que usas, desde tan solo USD 40 por mes.







Integración y socios
Aprovecha la experiencia de nuestros socios con Spanner en cada paso de tu recorrido, desde evaluaciones y casos empresariales hasta migraciones y compilación de apps nuevas en Spanner.











Integradores de sistemas
Los socios de Spanner te ayudan a modernizar aplicaciones y a migrar a la nube sin inconvenientes. Encuentra tu socio o integración de terceros ideal en nuestro directorio.
Preguntas frecuentes
¿Spanner es una base de datos relacional o no relacional?
Spanner simplifica tu arquitectura de datos, ya que reúne cargas de trabajo de búsquedas relacionales, de pares clave-valor, de gráficos y de vectores, todo en la misma base de datos. Es una base de datos altamente escalable que combina escalabilidad ilimitada con semántica relacional, como índices secundarios, coherencia sólida, esquemas y SQL, y proporciona un 99.999% de disponibilidad en una solución sencilla. Por lo tanto, es adecuado para cargas de trabajo relacionales y no relacionales.
¿Spanner usa SQL?
Spanner proporciona dos dialectos de SQL basados en ANSI sobre el mismo conjunto amplio de capacidades: GoogleSQL y PostgreSQL. GoogleSQL comparte la sintaxis con BigQuery para los equipos que estandarizan sus flujos de trabajo de administración de datos. La interfaz de PostgreSQL permite la familiaridad para los equipos que ya conocen PostgreSQL y la portabilidad de esquemas y consultas a otros entornos de PostgreSQL. Para obtener más información sobre la interfaz de PostgreSQL de Spanner, consulta nuestra documentación.
¿Cómo migro bases de datos a Spanner?
La migración a Spanner puede variar ampliamente en función de varios factores, como la base de datos de origen, el tamaño de los datos, los requisitos de tiempo de inactividad, la complejidad del código de la aplicación, el esquema de fragmentación, las funciones o transformaciones personalizadas, la conmutación por error y la estrategia de replicación. Las herramientas recomendadas incluyen herramientas de código abierto, como la herramienta de migración de Spanner para la migración de esquemas y datos, y herramientas de terceros para evaluaciones, como migVisor. Obtén más información sobre el proceso de migración en nuestra documentación.
¿Cuáles son las consideraciones clave para operar Spanner?
Spanner es una base de datos completamente administrada, por lo que proporciona automáticamente funciones de administración de infraestructura completas, pero existen algunas acciones de administración específicas de la aplicación que pueden ser necesarias según tu carga de trabajo. Deberás asegurarte de haber configurado las alertas y la supervisión adecuadas, y de supervisarlas de cerca para que la producción siempre se ejecute sin problemas. Debes comprender qué medidas tomar cuando el tráfico crezca de forma orgánica con el paso del tiempo o si se espera un tráfico máximo, o cómo manejar la corrupción de datos debido a errores de la aplicación y, por último, pero no menos importante, cómo solucionar problemas de rendimiento y comprender qué componentes son responsables de las latencias aumentadas.





















