
Spanner
実質的に無制限のスケーリングを備えた、常時稼働のデータベース
リレーショナル、グラフ、Key-Value、検索を組み合わせた単一のデータベースを使用して、インテリジェントなアプリを構築します。メンテナンスの時間枠がないため、ミッション クリティカルなアプリが中断されません。
さらに、Google Cloud の新規のお客様には、$300 分の無料クレジットを差し上げます。

機能
読み取りと書き込みのスケーラビリティに制限なし

自動メンテナンス
Spanner Graph
隠れた関係やつながりを明らかにする。Spanner Graph は、グラフ データベースの新しい国際標準である ISO Graph Query Language(GQL)に対応しており、直感的かつ簡潔な方法でパターンを照合したり、データの関係を走査したりできます。SQL と GQL の強みを兼ね備えており、構造化データと接続データを 1 回のオペレーションでクエリできます。Spanner Graph(プレビュー版)は全文検索およびベクトル検索機能の相互運用が可能で、新しいクラスの AI 対応アプリケーションを実現できます。
ベクトル検索
高度にパーティショニング可能なワークロード向けの厳密最近傍(KNN)と近似最近傍(ANN)ベクトル検索により、Spanner で実質的に無制限のスケーリングを使用してベクトル エンベディングを検索できます。Spanner に組み込まれたベクトル検索のサポートにより、個別の特殊なベクトル データベース ソリューションが不要になります。管理性のないスケールアウト サーバーレス アーキテクチャ上で、運用データのトランザクション保証、最新かつ整合性のあるベクトル検索結果が提供されます。

PostgreSQL Interface

データベースの自動シャーディング
地域別パーティション分割
単一のグローバル データベースの管理性を維持しながら、世界中に分散するユーザーのためにレイテンシを改善します。Spanner の地域別パーティション分割を使用すると、世界中のテーブルデータを行レベルで分割し、ユーザーに近い場所でデータを提供できます。データが複数のデータ パーティションに分割されていても、Spanner は分散されたすべてのデータを、クエリやミューテーション用に 1 つのまとまったテーブルとして維持します。
シングルリージョン、デュアルリージョン、マルチリージョンの構成
ユーザーは世界中のどこからでも Spanner に接続されたアプリを使って、強整合性が保たれた最新のデータの読み取りや書き込みを行えます。また、デュアルリージョンまたはマルチリージョン インスタンスを実行している場合、リージョン障害が発生してもデータベースを稼働でき、業界最高水準の 99.999% の可用性を実現します。
高パフォーマンスでワークロードから分離されたクエリ処理
Spanner Data Boost を使用すると、既存のトランザクション ワークロードに影響を与えることなく、分析クエリ、バッチ処理ジョブ、データのエクスポート オペレーションをより迅速に実行できます。Google Cloud により完全に管理されているため、キャパシティ プランニングや管理は必要ありません。常にホットな状態であり、Spanner の分散ストレージ システムである Colossus に保存されたデータに対するユーザークエリを直接処理できます。このオンデマンドの独立したコンピューティング リソースにより、ユーザーは混在したワークロードや安全なデータ共有を簡単に処理できます。

全文検索
Google 検索からの学習内容を活用した高性能なテキスト検索を利用することで、個別の検索ツールと関連する抽出、変換、読み込み(ETL)パイプラインを排除できます。全文検索は、トランザクションとしての一貫性がある検索結果を提供するとともに、音声検索、異なるスペルに関する NGRAM ベースのマッチングなどの強力な機能を備えています。詳しくは、こちらのホワイトペーパーをご覧ください。
LangChain インテグレーション
LangChain インテグレーションにより、より正確で透明性が高く、信頼性の高い生成 AI アプリケーションを簡単に構築できます。Spanne には 3 つの LangChain インテグレーションがあります。ドキュメントから情報を読み込んで保存するドキュメント ローダ、セマンティック検索を可能にする Vector ストア、チェーンによって以前の会話をリコールできるようにするチャット メッセージ メモリの 3 つです。詳しくは、GitHub リポジトリをご覧ください。
Vertex AI インテグレーション
Spanner の ML.PREDICT SQL 関数を使用して、Vertex AI で提供されるエンベディング、生成 AI、カスタムモデルに対してオンライン推論を実行します。Spanner to Vertex AI Vector Search Workflow を使用して、Vertex AI Vector Search によって Spanner データの類似検索を実行します。
データベース センター
複数のエンジン、バージョン、リージョン、プロジェクト、環境にわたるデータベース フリート全体を包括的に把握できます。データベース センター(プレビュー版)は、インテリジェントなパフォーマンスとセキュリティに関する推奨事項により、フリートのリスクをプロアクティブに回避するのに役立ちます。Gemini を有効にしたデータベース センターでは、データベース フリートの最適化が非常に直感的になります。自然言語のチャット インターフェースを使用して質問し、フリートの問題を迅速に解決して、最適化に関する推奨事項を得ることができます。
エンタープライズ クラスのセキュリティと制御
データベースの比較
| データベース属性 | 他のリレーショナル DB | 他の非リレーショナル DB | Spanner |
|---|---|---|---|
スキーマ | 静的 | 動的 | 動的 |
SQL | はい | いいえ | はい |
履歴 | ACID (原子性、整合性、独立性、耐久性) | 結果 | 強力な ACID TrueTime による順序付けで実現 |
スケーラビリティ | 垂直型 (より大型なマシンを使用) | 水平型 (マシンを追加します) | 横 |
サービス提供状況 | フェイルオーバー(ダウンタイム) | 高 | 99.999% の高 SLA |
レプリケーション | 構成可能 | 構成可能 | 自動 |
スキーマ
静的
動的
動的
SQL
はい
いいえ
はい
履歴
ACID
(原子性、整合性、独立性、耐久性)
結果
強力な ACID
TrueTime による順序付けで実現
スケーラビリティ
垂直型
(より大型なマシンを使用)
水平型
(マシンを追加します)
横
サービス提供状況
フェイルオーバー(ダウンタイム)
高
99.999% の高 SLA
レプリケーション
構成可能
構成可能
自動
仕組み
Spanner のインスタンスは、単一リージョンでも、複数リージョンでも、コンピューティングとストレージを提供します。TrueTime と呼ばれる分散クロックは、リージョン間も含めてトランザクションの強整合性を保証します。スケーラビリティのためにデータは自動的に「分割」され、可用性確保のために同期された Paxos ベースのスキームを使用して複製されます。
Spanner のインスタンスは、単一リージョンでも、複数リージョンでも、コンピューティングとストレージを提供します。TrueTime と呼ばれる分散クロックは、リージョン間も含めてトランザクションの強整合性を保証します。スケーラビリティのためにデータは自動的に「分割」され、可用性確保のために同期された Paxos ベースのスキームを使用して複製されます。
一般的な使用例
ユーザー プロフィールと利用資格
重要なユーザーデータをあらゆる規模に応じて安全に管理

チュートリアル、クイックスタート、ラボ
重要なユーザーデータをあらゆる規模に応じて安全に管理
会計台帳
最新で整合性のあるグローバル トランザクションのビューを取得
Spanner 上に構築された、統合された取引台帳に世界各地の金融トランザクション、取引、決済、ポジションを一元化することで、外部の整合性とスケーラビリティを保証します。データを統合することで、市場状況や規制要件の変化に迅速に対応できます。同様に、小売業や e コマースの企業も、在庫台帳に Spanner を使用しています。
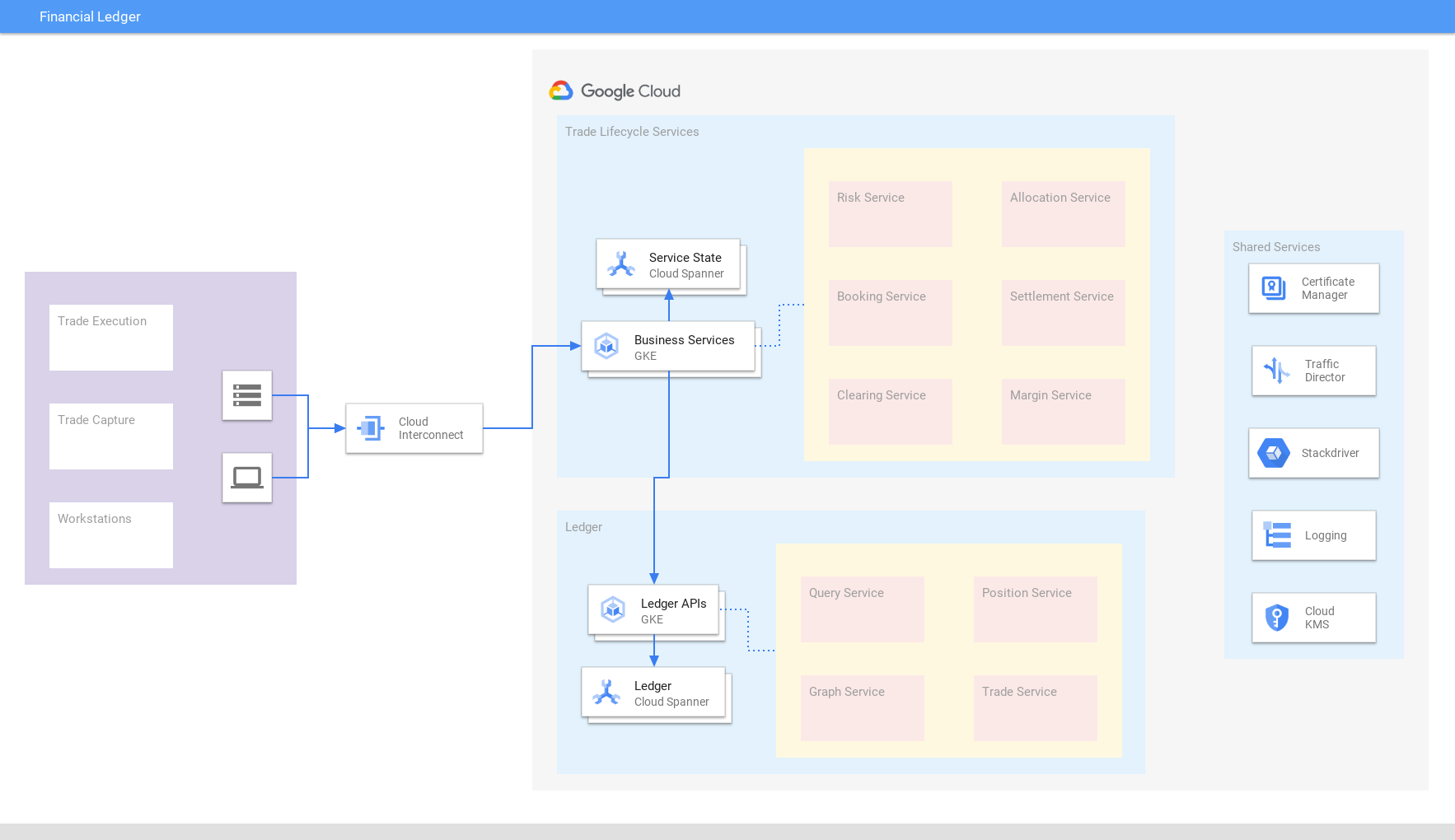
チュートリアル、クイックスタート、ラボ
最新で整合性のあるグローバル トランザクションのビューを取得
Spanner 上に構築された、統合された取引台帳に世界各地の金融トランザクション、取引、決済、ポジションを一元化することで、外部の整合性とスケーラビリティを保証します。データを統合することで、市場状況や規制要件の変化に迅速に対応できます。同様に、小売業や e コマースの企業も、在庫台帳に Spanner を使用しています。
オンライン バンキング
デジタル エクスペリエンスのインタラクティビティを常時提供
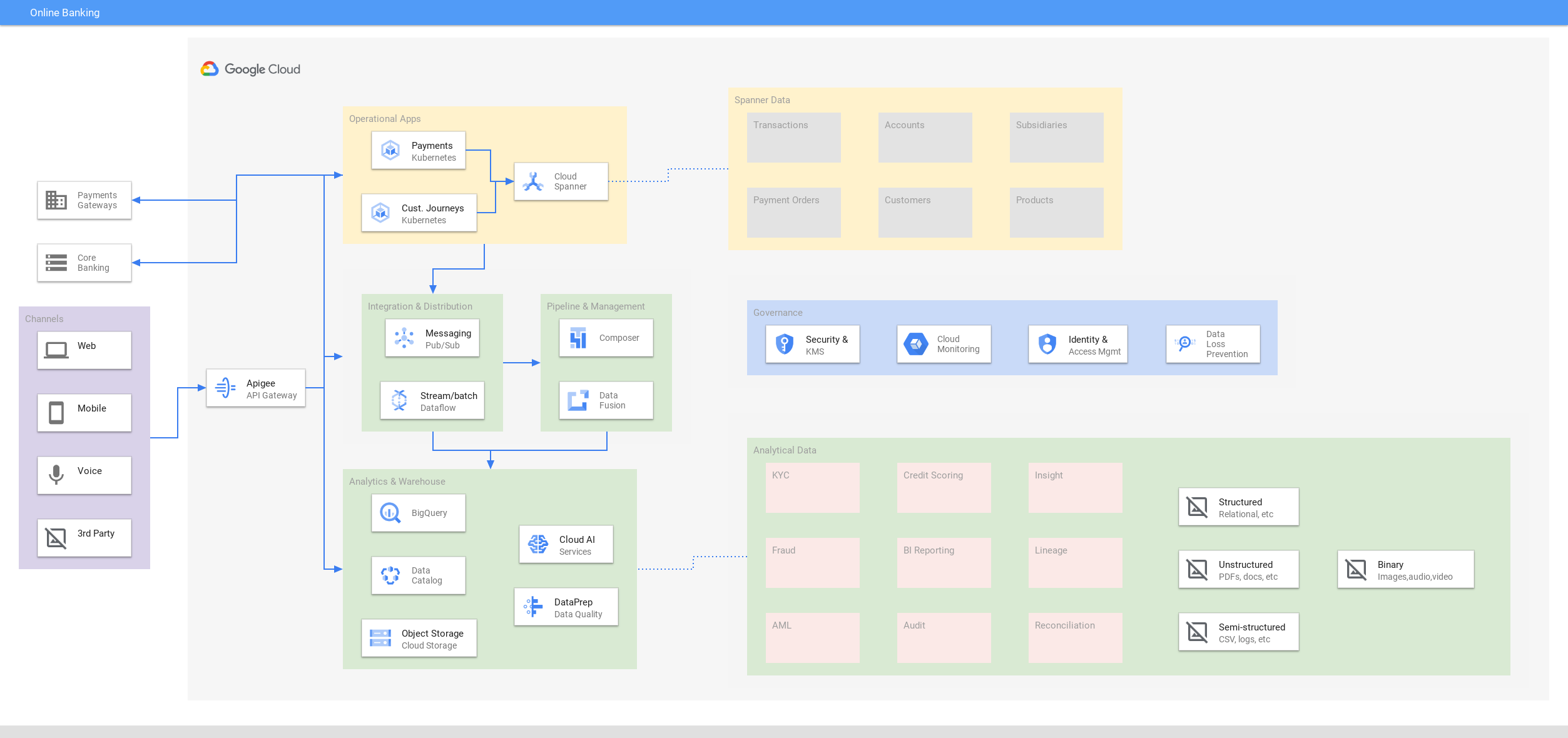
チュートリアル、クイックスタート、ラボ
デジタル エクスペリエンスのインタラクティビティを常時提供
ポイント プログラムとプロモーション
リアルタイム アップデートでエクスペリエンスをカスタマイズする
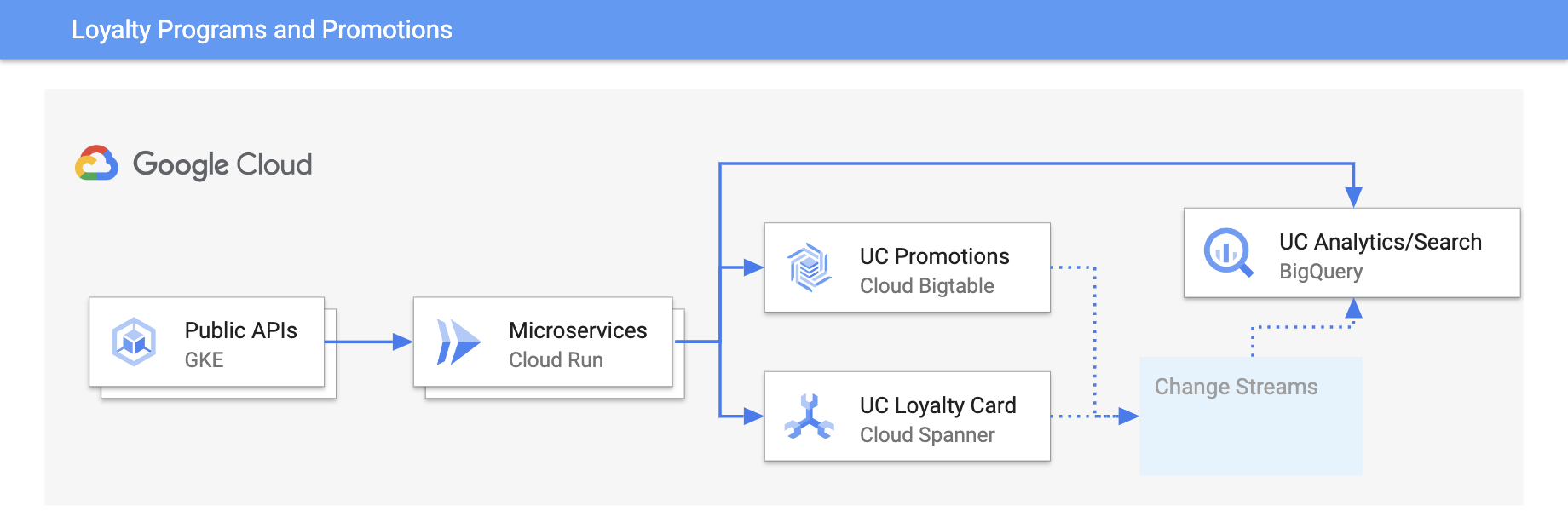
チュートリアル、クイックスタート、ラボ
リアルタイム アップデートでエクスペリエンスをカスタマイズする
オムニチャネル在庫管理
複数のチャネルとアプリで一貫性のあるビューを提供する
Spanner は、小売業の在庫と注文に関して、高パフォーマンスで信頼できる唯一の情報源を提供します。オンライン、店舗、配送センター、配送全体で在庫と需要を照合し、カスタマー エクスペリエンスと収益性を向上させます。ゲーム会社も同様に、Spanner を使用してゲーム内のインベントリ データを保存しています。
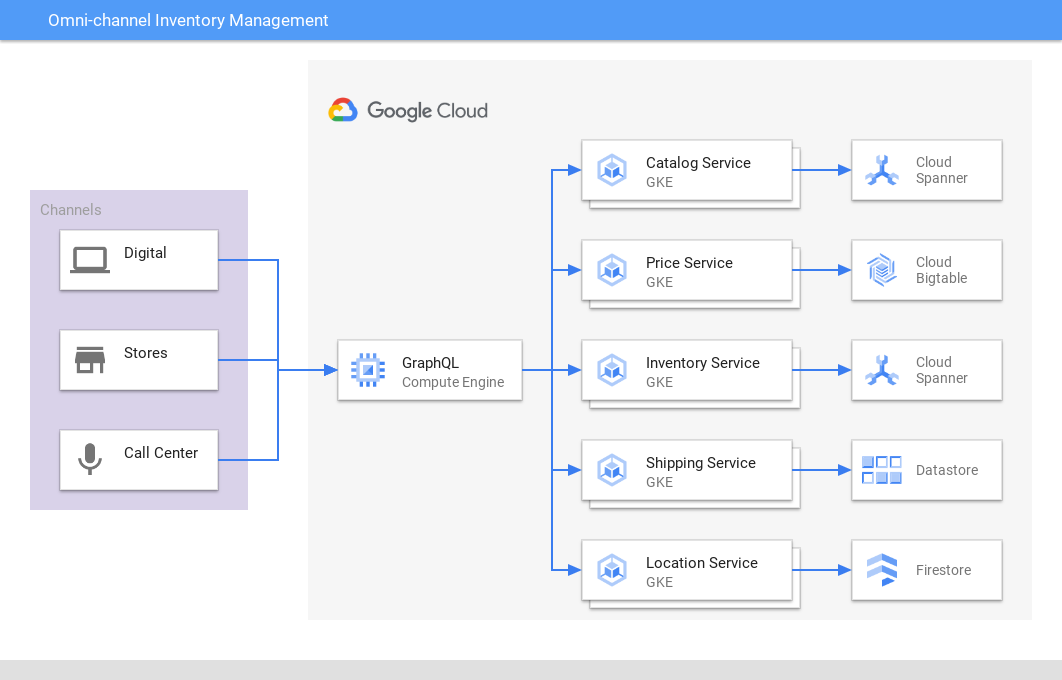
チュートリアル、クイックスタート、ラボ
複数のチャネルとアプリで一貫性のあるビューを提供する
Spanner は、小売業の在庫と注文に関して、高パフォーマンスで信頼できる唯一の情報源を提供します。オンライン、店舗、配送センター、配送全体で在庫と需要を照合し、カスタマー エクスペリエンスと収益性を向上させます。ゲーム会社も同様に、Spanner を使用してゲーム内のインベントリ データを保存しています。
ナレッジグラフ
データの隠れた関係性やつながりを明らかにする
データの隠れた関係性やつながりを明らかにする
Spanner Graph を使用すると、ノードとして表されるエンティティ間の複雑なつながりと、エッジとして表されるそれらの関係をキャプチャするナレッジグラフを開発できます。こうしたつながりによって豊富なコンテキストが提供されるため、ナレッジグラフはナレッジベース システムやレコメンデーション エンジンの開発に非常に役立ちます。統合された検索機能により、セマンティック理解、キーワードベースの検索、グラフをシームレスに統合して、包括的な結果を得ることができます。
チュートリアル、クイックスタート、ラボ
データの隠れた関係性やつながりを明らかにする
データの隠れた関係性やつながりを明らかにする
Spanner Graph を使用すると、ノードとして表されるエンティティ間の複雑なつながりと、エッジとして表されるそれらの関係をキャプチャするナレッジグラフを開発できます。こうしたつながりによって豊富なコンテキストが提供されるため、ナレッジグラフはナレッジベース システムやレコメンデーション エンジンの開発に非常に役立ちます。統合された検索機能により、セマンティック理解、キーワードベースの検索、グラフをシームレスに統合して、包括的な結果を得ることができます。
料金
| Spanner の料金の仕組み | Spanner の料金は、コンピューティング容量、Spanner Data Boost、データベース ストレージ、バックアップ ストレージ、レプリケーション、ネットワーク使用量に基づきます。コンピューティングの料金は、選択したエディションと構成によって異なります。確約利用割引により、コンピューティング料金をさらに削減できます。 | |
|---|---|---|
| サービス | 説明 | 価格(米ドル) |
コンピューティング | Standard エディション リージョン(シングルリージョン)構成向けに確立された機能の包括的なスイートを搭載 コンピューティング容量は、処理ユニットまたはノード(1 ノード = 1,000 処理ユニット)単位でプロビジョニングされます。 | Starting at $0.030 / 100 処理ユニット(レプリカごとに 1 時間あたり) |
Enterprise エディション 運用の簡素化と効率性を高めた、追加のマルチモデル検索機能と検索オプション機能を備えています コンピューティング容量は、処理ユニットまたはノード(1 ノード = 1,000 処理ユニット)単位でプロビジョニングされます。 | Starting at $0.041 / 100 処理ユニット(レプリカごとに 1 時間あたり) | |
Enterprise Plus エディション 最高レベルの可用性、パフォーマンス、コンプライアンス、ガバナンスを備え、特に要求の厳しいワークロードをサポート コンピューティング容量は、処理ユニットまたはノード(1 ノード = 1,000 処理ユニット)単位でプロビジョニングされます。 | Starting at $0.057 / 100 処理ユニット(レプリカごとに 1 時間あたり) | |
Data Boost | CPU、メモリ、ローカルデータ転送などのオンデマンドの分離コンピューティング リソース | Starting at $0.00117 サーバーレス処理ユニットごと、1 時間あたり |
データベース ストレージ | 料金はデータベースに保存されているデータの量に基づいており、読み取り / 書き込みレプリカと読み取り専用レプリカのストレージ費用が含まれています。ウィットネス レプリカは無料です。 | Starting at $0.10 GB/月、レプリカあたり |
バックアップ ストレージ | リージョン構成 料金はバックアップ ストレージの量に基づいて計算され、すべてのレプリカのストレージ費用が含まれます。 | Starting at $0.10 /GB/月(すべてのレプリカを含む) |
デュアルリージョンとマルチリージョンの構成 料金はバックアップ ストレージの量に基づいて計算され、すべてのレプリカのストレージ費用が含まれます。 | Starting at $0.30 /GB/月(すべてのレプリカを含む) | |
レプリケーション | リージョン内レプリケーション | 無料 |
リージョン間レプリケーション | Starting at $0.04 GB 単位 | |
ネットワーク | 上り(内向き) | 無料 |
リージョン内の下り(外向き) | 無料 | |
リージョン間の下り(外向き) | Starting at $0.01 GB 単位 | |
Spanner の料金の仕組み
Spanner の料金は、コンピューティング容量、Spanner Data Boost、データベース ストレージ、バックアップ ストレージ、レプリケーション、ネットワーク使用量に基づきます。コンピューティングの料金は、選択したエディションと構成によって異なります。確約利用割引により、コンピューティング料金をさらに削減できます。
Standard エディション
リージョン(シングルリージョン)構成向けに確立された機能の包括的なスイートを搭載
コンピューティング容量は、処理ユニットまたはノード(1 ノード = 1,000 処理ユニット)単位でプロビジョニングされます。
Starting at
$0.030
/ 100 処理ユニット(レプリカごとに 1 時間あたり)
Enterprise エディション
運用の簡素化と効率性を高めた、追加のマルチモデル検索機能と検索オプション機能を備えています
コンピューティング容量は、処理ユニットまたはノード(1 ノード = 1,000 処理ユニット)単位でプロビジョニングされます。
Starting at
$0.041
/ 100 処理ユニット(レプリカごとに 1 時間あたり)
Enterprise Plus エディション
最高レベルの可用性、パフォーマンス、コンプライアンス、ガバナンスを備え、特に要求の厳しいワークロードをサポート
コンピューティング容量は、処理ユニットまたはノード(1 ノード = 1,000 処理ユニット)単位でプロビジョニングされます。
Starting at
$0.057
/ 100 処理ユニット(レプリカごとに 1 時間あたり)
Data Boost
CPU、メモリ、ローカルデータ転送などのオンデマンドの分離コンピューティング リソース
Starting at
$0.00117
サーバーレス処理ユニットごと、1 時間あたり
データベース ストレージ
料金はデータベースに保存されているデータの量に基づいており、読み取り / 書き込みレプリカと読み取り専用レプリカのストレージ費用が含まれています。ウィットネス レプリカは無料です。
Starting at
$0.10
GB/月、レプリカあたり
バックアップ ストレージ
リージョン構成
料金はバックアップ ストレージの量に基づいて計算され、すべてのレプリカのストレージ費用が含まれます。
Starting at
$0.10
/GB/月(すべてのレプリカを含む)
デュアルリージョンとマルチリージョンの構成
料金はバックアップ ストレージの量に基づいて計算され、すべてのレプリカのストレージ費用が含まれます。
Starting at
$0.30
/GB/月(すべてのレプリカを含む)
レプリケーション
リージョン内レプリケーション
無料
リージョン間レプリケーション
Starting at
$0.04
GB 単位
ネットワーク
上り(内向き)
無料
リージョン内の下り(外向き)
無料
リージョン間の下り(外向き)
Starting at
$0.01
GB 単位
料金計算ツール
カスタムの見積もり
概念実証を開始する
90 日間の Spanner 無料トライアル インスタンスを作成しましょう。
Spanner の使用方法を確認する
コンソールでデータベースを作成してクエリを実行する
SQL ステートメントの作成に関するベスト プラクティスを確認する
サンプルを使用してコーディングを行う
ビジネスケース
他の企業が Spanner を利用して革新的なアプリを作成し、優れたカスタマー エクスペリエンスを実現し、コストを削減し、ROI を向上させた方法をご覧ください




注目の利点とお客様
あらゆるニーズに応じて無制限にスケーリングできる革新的なアプリケーションで、ビジネスを拡大しましょう。
TCO を削減し、デベロッパーを煩雑な作業から解放できます。目標を高く持ち、開発を迅速化しましょう。
月額 $40 からの従量制で、優れたコスト パフォーマンスを獲得できます。







パートナーとインテグレーション
評価からビジネスケース、移行、Spanner での新しいアプリのビルドまで、お客様のあらゆる段階で、Spanner の専門知識を持つパートナーをご活用ください。











システム インテグレータ
Spanner パートナーが、アプリケーションのモダナイゼーションとクラウドへのシームレスな移行を支援します。Google Cloud のディレクトリで、理想的なパートナーやサードパーティ統合を見つけましょう。
よくある質問
Spanner はリレーショナル データベースですか、それとも非リレーショナル データベースですか?
Spanner は、リレーショナル、Key-Value、グラフ、ベクトル検索のワークロードをすべて同じデータベースに統合することで、データ アーキテクチャを簡素化します。Spanner は、セカンダリ インデックス、強整合性、スキーマ、SQL などのリレーショナル セマンティクスを組み合わせ、単一の簡単なソリューションで 99.999% の可用性を提供する、スケーラビリティの高いデータベースです。そのため、リレーショナル ワークロードと非リレーショナル ワークロードの両方に適しています。
Spanner は SQL を使用しますか?
データベースを Spanner に移行するにはどうすればよいですか?
Spanner への移行は、ソース データベース、データサイズ、ダウンタイム要件、アプリケーション コードの複雑さ、シャーディング スキーマ、カスタム関数または変換、フェイルオーバーとレプリケーション戦略など、多くの要因によって大きく異なる場合があります。スキーマとデータの移行用には Spanner 移行ツールなどのオープンソース ツール、評価用には migVisor などのサードパーティ ツールをおすすめします。移行プロセスの詳細については、ドキュメントをご覧ください。
Spanner を運用するうえで考慮すべき重要事項は何ですか?
Spanner はフルマネージドのデータベースなので、インフラストラクチャの包括的な管理機能が自動的に提供されますが、ワークロードによっては、アプリケーション固有の管理アクションが必要になる場合があります。本番環境を常にスムーズに稼働させるには、適切なアラートとモニタリングをセットアップし、注意深く監視する必要があります。時間の経過とともにトラフィックが有機的に増加した場合やピーク トラフィックが想定される場合に、どう対処すべきかや、アプリケーションのバグに起因するデータの破損を処理する方法を理解する必要があります。さらに、パフォーマンスの問題をトラブルシューティングする方法と、レイテンシ増加の原因となるコンポーネントを把握する方法を理解することも重要です。





















