
随着机器人和 自动驾驶汽车 的发展,加速 物理 AI 的发展变得至关重要,而物理 AI 使自主机器能够感知、理解并在现实世界中执行复杂的操作。这些系统的核心是 世界基础模型 (WFMs),即通过物理感知视频模拟物理状态的 AI 模型,使机器能够做出准确决策并与周围环境无缝交互。
NVIDIA Cosmos 平台可帮助开发者大规模为物理 AI 系统构建自定义世界模型。它为从数据管护、训练到定制的每个开发阶段提供开放世界基础模型和工具。
本文将介绍 Cosmos 及其加速物理 AI 开发的主要功能。Cosmos 是一种开源的 Python 库,用于加速物理 AI 开发。
借助 NVIDIA Cosmos 加速世界模型开发
构建物理 AI 极具挑战性,需要精确的模拟以及真实世界的行为理解和预测。克服这些挑战的一个关键工具是世界模型,该模型根据过去的观察结果和当前的输入结果预测未来的环境状态。这些模型对于物理 AI 构建者来说非常重要,使他们能够在受控环境中模拟、训练和优化系统。
然而,开发有效的世界模型需要大量数据、计算能力和真实世界的测试,这可能会带来重大的安全风险、物流障碍和高昂的成本。为了应对这些挑战,开发者通常会使用通过 3D 仿真生成的 合成数据 来训练模型。虽然合成数据是一种功能强大的工具,但创建合成数据需要大量资源,可能无法准确反映现实世界的物理特性,在复杂或边缘情况下尤其如此。
端到端 NVIDIA Cosmos 平台 可加速物理 AI 系统的世界模型开发。Cosmos 基于 CUDA 构建,结合了先进的世界基础模型、视频标记器和 AI 加速的数据处理流程。
开发者可以通过微调 Cosmos 世界基础模型或从头开始构建新模型来加速世界模型的开发。除了 Cosmos 世界基础模型之外,该平台还包括:
- 用于高效视频数据管护的 NVIDIA NeMo Curator
- Cosmos Tokenizer 可实现高效、紧凑和高保真的视频标记化
- 为机器人和自动驾驶应用预训练的 Cosmos World Foundation 模型
- 用于模型训练和优化的 NVIDIA NeMo 框架
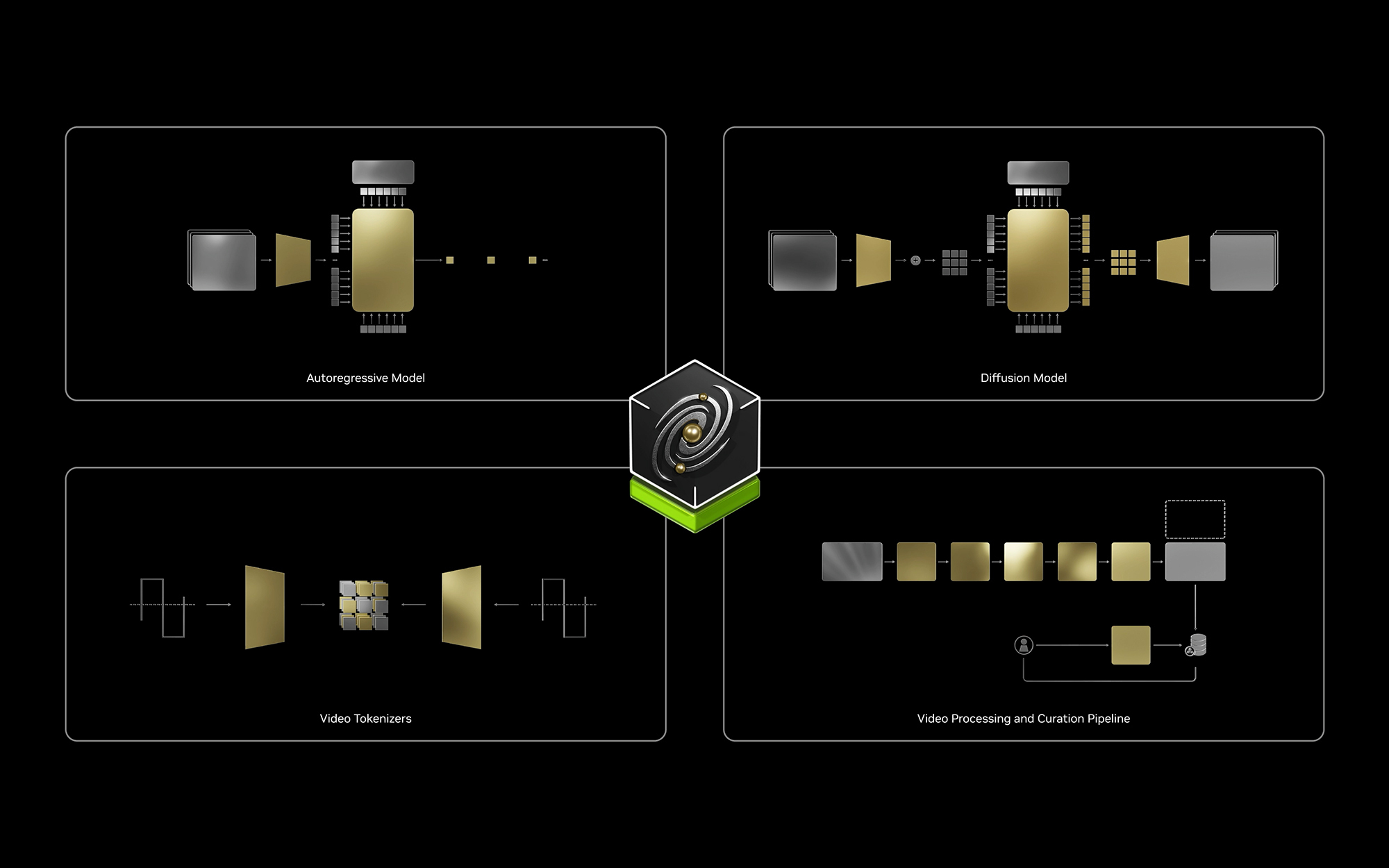
适用于物理 AI 的 预训练世界基础模型
Cosmos 世界基础模型是预训练的大型生成式 AI 模型,使用 9000 万亿个令牌进行训练,其中包括来自 自动驾驶 、 机器人 开发、合成环境和其他相关领域的 2000 万个小时的数据。这些模型可创建有关环境和交互的逼真合成视频,为训练复杂系统 (从模拟执行高级动作的类 人型机器人 到开发端到端自动驾驶模型) 提供可扩展的基础。
这些模型使用两种架构:自回归和扩散。这两种方法都使用 Transformer 架构,因为其可扩展性和有效性可用于处理复杂的时间依赖项。
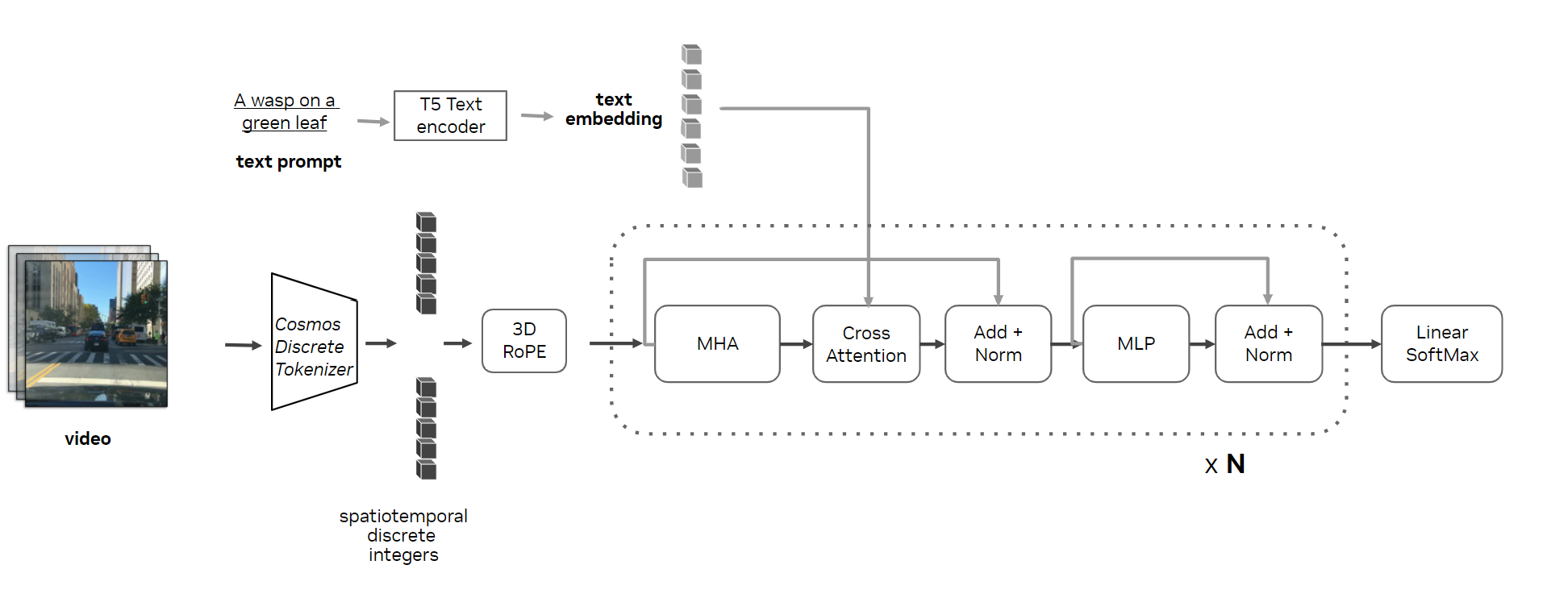
自回归模型
Cosmos 自回归模型专为视频生成而设计,可根据输入文本和过去的视频帧预测下一个令牌。它使用 Transformer 解码器架构,并针对世界模型开发进行了关键修改。
- 3D RoPE (Rotary Position Embeddings) 可分别对空间和时间维度进行编码,确保精确的视频序列表示。
- 交叉注意力层支持文本输入,从而更好地控制世界生成。
- QK 标准化可增强训练稳定性。
此模型的预训练是渐进式的,首先从单个输入帧预测多达 17 帧的未来帧,然后扩展到 34 帧,最终达到 121 帧 (或 50,000 个 tokens)。引入文本输入以将描述与视频帧相结合,并使用高质量数据对模型进行微调,以实现强大的性能。这种结构化方法使模型能够生成长度和复杂性各不相同的视频,无论是否输入文本。
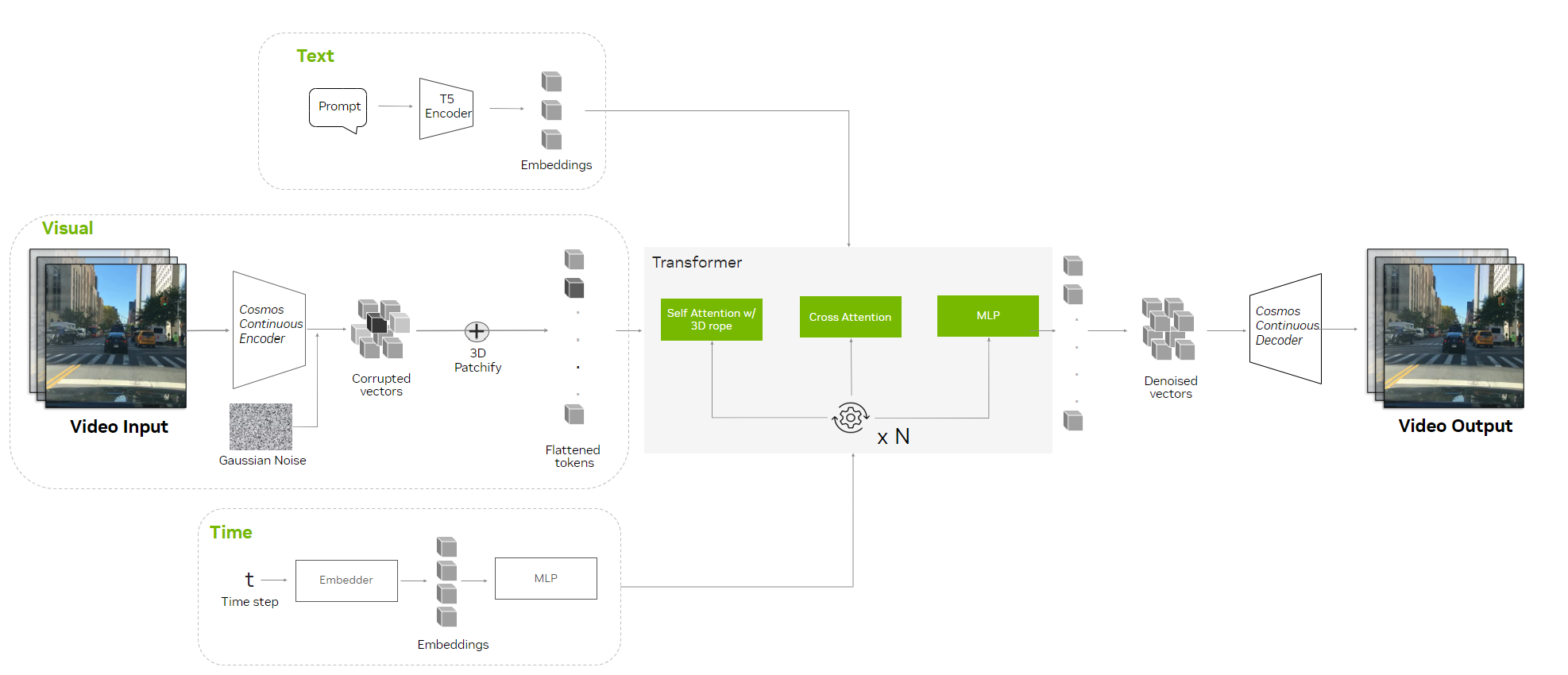
扩散模型
Diffusion 模型在生成图像、视频和音频方面很受欢迎,因为它们能够解构训练数据并根据用户输入进行重建,从而生成高质量、逼真的输出。
扩散模型分为两个阶段:
- 前向扩散过程: 通过在多个步骤中添加高斯噪声,有效地将其转换为纯噪声,训练数据会逐渐损坏。
- 反向扩散过程: 模型会逐步学习反向噪声,通过对损坏的输入降噪来恢复原始数据,例如使用 Stable Diffusion 模型。
经过训练后,扩散模型通过对随机高斯噪声进行采样并将其传递给学习的降噪过程来生成新数据。此外,Cosmos 扩散模型还获得了一些专为物理 AI 开发打造的关键更新。
- 3D Patchification 将视频处理为更小的分块,从而简化时空序列表示。
- 混合位置嵌入可处理空间和时间维度,支持具有不同分辨率和帧率的视频。
- 交叉注意力层整合文本输入,从而更好地控制基于描述生成的视频。
- 采用 LoRA 的自适应层归一化可将模型大小减少 36%,从而以更少的资源保持高性能。
满足不同需求的模型大小
开发者可以从以下三种模型大小中进行选择,以满足性能、质量和部署需求。
- Nano: 针对实时、低延迟推理和边缘部署进行优化。
- Super: 设计为高性能基准模型。
- Ultra:专注于最大化质量和保真度,适合提取自定义模型。
优点和局限性
Cosmos 世界基础模型生成低分辨率、真实世界准确的合成视频数据,这对于训练 机器人 和自动驾驶汽车系统至关重要。虽然它们缺乏艺术天赋,但其输出结果密切复制了物理世界,因此非常适合在物理 AI 模型训练中实现精确的物体持久性和逼真的场景。
用于安全使用 Cosmos World 基础模型的护栏
AI 模型需要护栏来确保可靠性,具体方法包括减少幻影、防止有害输出、保护隐私,以及符合 AI 标准以实现安全可控的部署。Cosmos 通过可定制的双阶段护栏系统确保其 World Foundation 模型的安全使用,该系统符合 NVIDIA 对值得信赖的 AI 的承诺。
Cosmos Guardrails 分为两个阶段:Pre-guard 和 Post-guard。
预防护
此阶段涉及基于文本提示的安全措施,使用两层:
- 关键字屏蔽:屏蔽列表检查器会扫描不安全关键字的提示,使用引言化来检测变异,并阻止非英语术语或拼写错误。
- Aegis Guardrail: 经过 NVIDIA 微调的 Aegis AI 内容安全模型可以检测并阻止语义上不安全的提示,包括暴力、骚扰和冒犯等类别。不安全提示停止视频生成并返回错误消息。
护卫队队员
Post-guard Stage 通过以下方式确保生成视频的安全性:
- 视频内容安全分类器: 多类别分类器评估每个视频帧的安全性。如果任何帧被标记为不安全,则整个视频将被拒绝。
- 面部模糊滤镜: 使用 RetinaFace 模型对生成的视频中的所有人脸进行模糊处理,以保护隐私并减少基于年龄、性别或种族的偏见。
NVIDIA 专家使用对抗示例进行严格测试,标注超过 10,000 个提示视频对,以优化系统并解决边缘案例。
评估 Cosmos 世界基础模型,以实现 3D 一致性和物理对齐
Cosmos 基准测试在评估世界基础模型为物理 AI 应用准确高效地模拟真实物理的能力方面发挥着至关重要的作用。虽然公开可用的视频生成基准测试侧重于保真度、时间一致性和生成视频的速度,但 Cosmos 基准测试增加了新的维度来评估通用模型:3D 一致性和物理对齐,确保根据物理 AI 系统所需的准确性评估视频。
3D 一致性
Cosmos 模型在 开放数据集 中的 500 个精选视频子集中进行了静态场景的 3D 一致性测试。生成描述视频的文本提示是为了避免与动作相关的复杂性。并与基准生成模型 VideoLDM 进行了比较。
所用指标
- 几何一致性:使用 Sampson 误差和摄像头姿态估计成功率等指标通过外极性几何约束条件进行评估。
- 查看合成一致性: 通过峰值信噪比 (Peak Signal-to-Noise Ratio, PSNR)、结构相似性指数 (Structural Similarity Index, SSIM) 和学习感知图像块相似性 (Learned Perceptual Image Patch Similarity, LPIPS) 等指标进行评估。这些指标用于测量从插入的摄像头位置合成视图的质量。
更低的 Sampson 误差和更高的成功率表明 3D 对齐效果更好。同样,较高的 PSNR 和 SSIM 以及较低的 LPIPS 都表示质量有所提高。
| 模型 | Sampson 错误* | 姿态估计成功率 (%)* | PSNR* | SSIM | LPIPS |
| VideoLDM | 0.841 | 4.40% | 26.23 | 0.783 | 0.135 |
| Cosmos 1.0 Diffusion Text2World 7B | 0.355 | 62.60% | 33.02 | 0.939 | 0.070 |
| Cosmos 1.0 Diffusion Video2World 7B | 0.473 | 68.40% | 30.66 | 0.929 | 0.085 |
| Cosmos 1.0 Autoregressive 4B | 0.433 | 35.60% | 32.56 | 0.933 | 0.090 |
| Cosmos 1.0 Autoregressive Video2World 5B | 0.392 | 27.00% | 32.18 | 0.931 | 0.090 |
| 真实视频 (参考) | 0.431 | 56.40% | 35.38 | 0.962 | 0.054 |
成果
Cosmos 世界基础模型在 3D 一致性方面的表现优于基准 (表 1),具有更高的几何对齐和摄像头姿态成功率。其合成视图与真实世界的质量相匹配,证实了其作为世界模拟器的有效性。
物理对齐
物理对齐测试 Cosmos 模型在模拟真实物理 (包括运动、重力和能量动力学) 时的效果。借助 NVIDIA PhysX 和 NVIDIA Isaac Sim ,设计出八个受控场景,用于评估虚拟环境中的重力、碰撞、扭矩和惯性等属性。
所用指标
- 像素级指标 :峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)可测量模型输出的像素值与参考视频的匹配程度。值越高表示噪点越小,准确性越高。结构相似性指数指标(Structural Similarity Index Measure,SSIM)用于评估生成的帧与真实帧之间在结构、亮度和对比度方面的相似性。较高的 SSIM 值反映了更高的视觉保真度。
- 特征级别指标 :DreamSim 测量从两个视频中提取的高级特征之间的相似性。这种方法评估生成内容的语义一致性,重点关注物体和运动,而不是单个像素。
- 目标级别指标: 交集并集比 (Intersection-over-Union,IoU) 用于计算视频中预测的目标区域与实际目标区域之间的重叠。这对于在整个模拟过程中追踪特定物体特别有用,可确保其行为符合物理预期。
PSNR、SSIM、DreamSim 和 IoU 越高,表示物理对齐越好。
| 模型 | 调节 | PSNR* | SSIM | DreamSim™ | 平均值。IoU* |
| Cosmos 1.0 Diffusion Video2World 7B | 提示符 = 1 帧 | 17.34 | 0.54 | 0.84 | 0.332 |
| Cosmos 1.0 Diffusion Video2World 7B | 提示符 = 9 帧 | 21.06 | 0.69 | 0.86 | 0.592 |
| Cosmos 1.0 Diffusion Video2World 14B | 提示符 = 1 帧 | 16.81 | 0.52 | 0.84 | 0.338 |
| Cosmos 1.0 Diffusion Video2World 14B | 提示符 = 9 帧 | 20.21 | 0.64 | 0.86 | 0.598 |
| Cosmos 1.0 Autoregressive 4B | 1 帧 | 17.91 | 0.49 | 0.83 | 0.394 |
| Cosmos 1.0 Autoregressive 4B | 9 帧 | 18.13 | 0.48 | 0.86 | 0.481 |
| Cosmos 1.0 Autoregressive Video2World 5B | 提示符 = 1 帧 | 17.67 | 0.48 | 0.82 | 0.376 |
| Cosmos 1.0 Autoregressive Video2World 5B | 提示符 = 9 帧 | 18.29 | 0.48 | 0.86 | 0.481 |
| Cosmos 1.0 Autoregressive Video2World 12B | 1 帧 | 17.94 | 0.49 | 0.83 | 0.395 |
| Cosmos 1.0 Autoregressive Video2World 12B | 9 帧 | 18.22 | 0.49 | 0.87 | 0.487 |
| Cosmos 1.0 Autoregressive Video2World 13B | 提示符 = 1 帧 | 18 | 0.49 | 0.83 | 0.397 |
| Cosmos 1.0 Autoregressive Video2World 13B | 提示符 = 9 帧 | 18.26 | 0.48 | 0.87 | 0.482 |
成果
Cosmos 世界基础模型非常遵守物理定律 (表 2),尤其是在条件数据增加的情况下。与基线模型相比,在摄像头调节数据集上进行后训练后,姿态估计的成功率提高了两倍。然而,物体无常 (物体意外消失或出现) 和难以置信的行为 (如违反重力) 等挑战凸显了需要改进的领域。
使用 Cosmos 和 NVIDIA Omniverse 定制物理 AI 应用
- 视频搜索和理解: 通过了解空间和时间模式来简化视频标记和搜索,从而更轻松地准备训练数据
- 可控的 3D 到真实合成数据生成: 借助 NVIDIA Omniverse ,开发者可以创建 3D 场景,并使用 Cosmos 生成逼真的视频,这些视频由 3D 场景精确控制,用于高度定制的合成数据集。
- 策略模型开发和评估: World foundation models 针对动作条件视频预测进行了微调,可实现策略模型的可扩展、可再现评估 (将状态映射到动作的策略),从而减少对障碍物导航或对象操作等任务进行风险真实测试或复杂模拟的依赖。
- 行动选择前瞻: Cosmos 为物理 AI 模型配备预测功能,以评估潜在行动的结果。
- Multiverse 模拟: 借助 Cosmos 和 NVIDIA Omniverse,开发者可以模拟多种未来结果,帮助 AI 模型评估和选择实现目标的最佳策略,从而使预测性维护和自主决策等应用受益。
从通用模型到定制的专业模型
Cosmos 为世界模型训练引入了一种分为两个阶段的方法。
多面手模型:Cosmos 世界基础模型以多面手的身份构建,基于涵盖各种真实物理和环境的大量数据集进行训练。这些开放模型能够处理从自然动力学到机器人交互的各种场景,为任何物理 AI 任务提供坚实的基础。
专业模型:开发者可以使用更小的定向数据集微调通用模型,为特定应用(如自动驾驶或人形机器人)打造量身定制的专家模型,也可以生成定制的合成场景,如夜间场景中的紧急车辆或高保真工业机器人环境。与从头开始训练模型相比,这种微调过程可显著减少所需的数据和训练时间。
Cosmos 通过高效的视频处理流程、高性能的 tokenizer 和高级训练框架加速训练和微调,使开发者能够满足运营需求和边缘案例,推动物理 AI 的发展。
借助 NVIDIA NeMo Curator 加速数据处理
训练模型需要精心挑选的高质量数据,而且需要耗费大量时间和资源。NVIDIA Cosmos 包含由 NVIDIA NeMo Curator 提供支持并针对 NVIDIA 数据中心 GPU 进行优化的数据处理和管护流程。
借助 NVIDIA NeMo Curator,机器人和自动驾驶(AV)开发者能够高效处理庞大的数据集。例如,20 million 小时的视频可以在 40 天内在 NVIDIA Hopper GPU 上处理完毕,或仅在 14 天内在 NVIDIA Blackwell GPU 上处理完毕——相比之下,未经优化的 CPU 流水线需要 3.4 年。
主要优势包括:
- PyTorch、pandas、LangChain、Megatron、NVIDIA、cuOpt、Stable Diffusion、Llama、Jetson、Google、Python、Hugging Face、Arm、Anaconda、Siemens、DPU、GPU 和 Github 等技术的 89 倍管护速度:显著缩短处理时间
- 可扩展性: 无缝处理 100 多个 PB 的数据
- 高吞吐量:高级过滤、字幕和嵌入可在不牺牲速度的情况下确保质量

使用 Cosmos Tokenizer 实现高保真压缩和重建
整理数据后,必须对其进行标记化以进行训练。标记化将复杂的数据分解为可管理的单元,使模型能够更高效地处理数据并从中学习。
Cosmos 标记器可简化此过程,加快压缩和视觉重建速度,同时保持质量,降低成本和复杂性。对于自回归模型,离散分词器可将数据压缩为时间的 8 倍,在空间中压缩为 16 × 16,一次最多处理 49 帧。对于扩散模型,连续分词器可实现 8 倍的时间和 8 × 8 的空间压缩,最多可处理 121 帧。
使用 NVIDIA NeMo 进行微调
开发者可以使用 NVIDIA NeMo 框架微调 Cosmos 世界基础模型。NeMo 框架可以在 GPU 驱动的系统上加速模型训练,无论是增强现有模型还是构建新模型,从本地数据中心到云端。
NeMo 框架通过以下方式高效加载多模态数据:
- 将 TB 大小的数据集分片到压缩文件中,以减少 IO 开销。
- 决定性地保存和加载数据集,以避免重复并尽可能减少计算浪费。
- 在使用优化的通信交换数据时降低网络带宽。
开始使用 NVIDIA Cosmos
Cosmos World Foundation 模型现已开放,可在 NGC 和 Hugging Face 上获取。开发者还可以在 NVIDIA API Catalog 上运行 Cosmos World Foundation 模型。API Catalog 上还提供了用于增强文本提示以提高准确性的 Cosmos 工具、支持未来轻松识别 AI 生成序列的内置水印系统,以及用于解码视频序列以用于增强现实应用的专用模型。如需了解详情,请观看演示。
NeMo Curator for accelerated data processing pipelines is available as a managed service and SDK. Developers can now apply for early access . Cosmos tokenizers are open neural networks available on GitHub and Hugging Face .






