Sentiment Analysis – Extracting Decision-Relevant Knowledge from UGC
•Download as PPT, PDF•
0 likes•421 views

This document discusses using sentiment analysis techniques to automatically extract decision-relevant knowledge from user-generated online reviews in the tourism domain. It compares different machine learning and dictionary-based approaches for classifying reviews by sentiment, subjectivity, and properties discussed. Support vector machines achieved the best results for sentiment and property classification, while a dictionary-based approach worked best for subjectivity. The extracted sentiment data is intended to provide benchmarking and feedback for tourism managers to enhance services based on customer opinions.




















Sentiment Analysis – Extracting Decision-Relevant Knowledge from UGC
- 1. Sentiment analysis – extracting decision-relevant knowledge from UGC Sergej Schmunka Wolfram Höpkena Matthias Fuchsb Maria Lexhagenb a University of Applied Sciences Ravensburg-Weingarten Weingarten, Germany {name.surname}@hs-weingarten.de b Mid-Sweden University Östersund, Sweden {name.surname}@miun.se ENTER 2014 Research Track Slide Number 1
- 2. Content • Introduction • Sentiment analysis • Methodology and implementation • Evaluation • Extracted knowledge as input to decision support • Conclusion ENTER 2014 Research Track Slide Number 2
- 3. Content • Introduction • Sentiment analysis • Methodology and implementation • Evaluation • Extracted knowledge as input to decision support • Conclusion ENTER 2014 Research Track Slide Number 3
- 4. Motivation • User generated content (UGC) – Huge potential to reduce information asymmetries • >65% of users use review sites for travel decision • >95% of users consider review sites as credible – Valuable knowledge base for tourism suppliers to enhance service quality • Challenge for tourism managers – Find relevant reviews and analyse them efficiently – Automatic extraction of decision-relevant knowledge – Customer feedback on the level of product properties ENTER 2014 Research Track Slide Number 4
- 5. Objective • Automatic information extraction from textual customer reviews of online review platforms – Identifying the polarity of customer opinions – Assigning opinions to product properties • Evaluation – Compare different data mining techniques (dictionarybased and machine learning approaches) concerning the quality of extracted information – Evaluate decision support in context of a destination MIS ENTER 2014 Research Track Slide Number 5
- 6. Content • Introduction • Sentiment analysis • Methodology and implementation • Evaluation • Extracted knowledge as input to decision support • Conclusion ENTER 2014 Research Track Slide Number 6
- 7. Sentiment analysis • Sentiment analysis / opinion mining – Identification of subjective statements and contained opinions and sentiments within natural texts • Approaches – Machine learning, dictionary-based, statistical and semantic approaches ENTER 2014 Research Track Slide Number 7
- 8. Sentiment analysis • Related work – Ye et al. (2009) apply supervised learning algorithms (Support Vector Machines, Naïve Bayes and n-gram based language models) to complete customer reviews – Kasper and Vela (2011) make use of machine learning and a semantic approach, based on rules to detect linguistic parts of a sentence – Grabner et al. (2012) extract a domain-specific lexicon of semantically relevant words together with their POS tags – García et al. (2012) present a dictionary-based approach, using a dictionary with 6,000 positive and negative words ENTER 2014 Research Track Slide Number 8
- 9. Content • Introduction • Sentiment analysis • Methodology and implementation • Evaluation • Extracted knowledge as input to decision support • Conclusion ENTER 2014 Research Track Slide Number 9
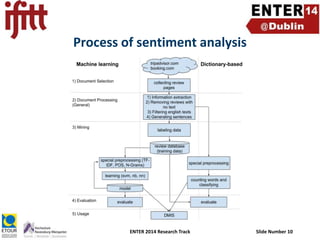
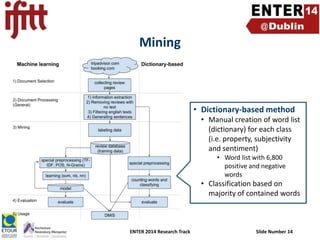
- 10. Process of sentiment analysis ENTER 2014 Research Track Slide Number 10
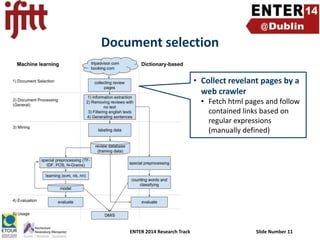
- 11. Document selection • Collect revelant pages by a web crawler • Fetch html pages and follow contained links based on regular expressions (manually defined) ENTER 2014 Research Track Slide Number 11
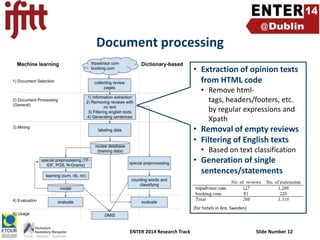
- 12. Document processing • Extraction of opinion texts from HTML code • Remove htmltags, headers/footers, etc. by regular expressions and Xpath • Removal of empty reviews • Filtering of English texts • Based on text classification • Generation of single sentences/statements (for hotels in Are, Sweden) ENTER 2014 Research Track Slide Number 12
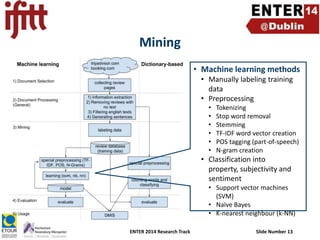
- 13. Mining • Machine learning methods • Manually labeling training data • Preprocessing • • • • • • Tokenizing Stop word removal Stemming TF-IDF word vector creation POS tagging (part-of-speech) N-gram creation • Classification into property, subjectivity and sentiment • Support vector machines (SVM) • Naïve Bayes • K-nearest neighbour (k-NN) ENTER 2014 Research Track Slide Number 13
- 14. Mining • Dictionary-based method • Manual creation of word list (dictionary) for each class (i.e. property, subjectivity and sentiment) • Word list with 6,800 positive and negative words • Classification based on majority of contained words ENTER 2014 Research Track Slide Number 14
- 15. Content • Introduction • Sentiment analysis • Methodology and implementation • Evaluation • Extracted knowledge as input to decision support • Conclusion ENTER 2014 Research Track Slide Number 15
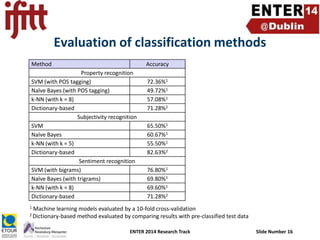
- 16. Evaluation of classification methods Method Accuracy Property recognition SVM (with POS tagging) Naïve Bayes (with POS tagging) k-NN (with k = 8) Dictionary-based Subjectivity recognition SVM Naïve Bayes k-NN (with k = 5) Dictionary-based Sentiment recognition SVM (with bigrams) Naïve Bayes (with trigrams) k-NN (with k = 8) Dictionary-based 1 72.36%1 49.72%1 57.08%1 71.28%2 65.50%1 60.67%1 55.50%1 82.63%2 76.80%1 69.80%1 69.60%1 71.28%2 Machine learning models evaluated by a 10-fold cross-validation method evaluated by comparing results with pre-classified test data 2 Dictionary-based ENTER 2014 Research Track Slide Number 16
- 17. Evaluation of classification methods Method Accuracy Property recognition SVM (with POS tagging) Naïve Bayes (with POS tagging) k-NN (with k = 8) Dictionary-based Subjectivity recognition SVM Naïve Bayes k-NN (with k = 5) Dictionary-based Sentiment recognition SVM (with bigrams) Naïve Bayes (with trigrams) k-NN (with k = 8) Dictionary-based 1 72.36%1 49.72%1 57.08%1 71.28%2 • SVM best machine learning technique for property recognition • Although based on limited training data set size (100) 65.50%1 60.67%1 55.50%1 82.63%2 76.80%1 69.80%1 69.60%1 71.28%2 Machine learning models evaluated by a 10-fold cross-validation method evaluated by comparing results with pre-classified test data 2 Dictionary-based ENTER 2014 Research Track Slide Number 17
- 18. Evaluation of classification methods Method Accuracy Property recognition SVM (with POS tagging) Naïve Bayes (with POS tagging) k-NN (with k = 8) Dictionary-based Subjectivity recognition SVM Naïve Bayes k-NN (with k = 5) Dictionary-based Sentiment recognition SVM (with bigrams) Naïve Bayes (with trigrams) k-NN (with k = 8) Dictionary-based 1 72.36%1 49.72%1 57.08%1 71.28%2 65.50%1 60.67%1 55.50%1 82.63%2 76.80%1 69.80%1 69.60%1 71.28%2 • SVM best machine learning technique for property recognition • Although based on limited training data set size (100) • Dictionary-based method achieved competitive results • Most misclassifications are caused by class “Uncategorized” as only most prominent words have been included in word lists Machine learning models evaluated by a 10-fold cross-validation method evaluated by comparing results with pre-classified test data 2 Dictionary-based ENTER 2014 Research Track Slide Number 18
- 19. Evaluation of classification methods Method Accuracy Property recognition SVM (with POS tagging) Naïve Bayes (with POS tagging) k-NN (with k = 8) Dictionary-based Subjectivity recognition SVM Naïve Bayes k-NN (with k = 5) Dictionary-based Sentiment recognition SVM (with bigrams) Naïve Bayes (with trigrams) k-NN (with k = 8) Dictionary-based 1 72.36%1 49.72%1 57.08%1 71.28%2 65.50%1 60.67%1 55.50%1 82.63%2 76.80%1 69.80%1 69.60%1 71.28%2 • Dictionary-based approach achieved best results • Possibly caused by huge word list (6,800 words) compared to fairly small training data set size (300 per class) of machine learning methods Machine learning models evaluated by a 10-fold cross-validation method evaluated by comparing results with pre-classified test data 2 Dictionary-based ENTER 2014 Research Track Slide Number 19
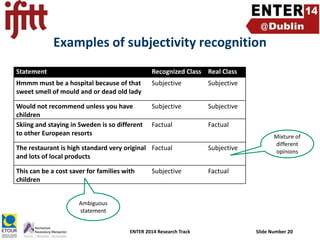
- 20. Examples of subjectivity recognition Statement Recognized Class Real Class Hmmm must be a hospital because of that sweet smell of mould and or dead old lady Subjective Subjective Would not recommend unless you have children Skiing and staying in Sweden is so different to other European resorts Subjective Subjective Factual Factual The restaurant is high standard very original Factual and lots of local products Subjective This can be a cost saver for families with children Mixture of different opinions Factual Subjective Ambiguous statement ENTER 2014 Research Track Slide Number 20
- 21. Evaluation of classification methods Method Accuracy Property recognition SVM (with POS tagging) Naïve Bayes (with POS tagging) k-NN (with k = 8) Dictionary-based Subjectivity recognition SVM Naïve Bayes k-NN (with k = 5) Dictionary-based Sentiment recognition SVM (with bigrams) Naïve Bayes (with trigrams) k-NN (with k = 8) Dictionary-based 1 72.36%1 49.72%1 57.08%1 71.28%2 65.50%1 60.67%1 55.50%1 82.63%2 76.80%1 69.80%1 69.60%1 71.28%2 • SVM method reached best result • Dictionary-based approach suffers from additional class „neutral“ if positive and negative words are equally frequent Machine learning models evaluated by a 10-fold cross-validation method evaluated by comparing results with pre-classified test data 2 Dictionary-based ENTER 2014 Research Track Slide Number 21
- 22. Examples of sentiment recognition Statement Recognized Class Real Class Parts of the hotel seems to be an old hospital Negative Negative All other guests I would recommend hotel Positive diplomat instead The rooms aren’t too big but very clean and Negative comfy Negative Good rooms and nicely clean Positive Positive Very nice breakfast room good selection for breakfast Positive Misleading statement Positive ENTER 2014 Research Track Positive Mixture of different opinions Slide Number 22
- 23. Content • Introduction • Sentiment analysis • Methodology and implementation • Evaluation • Extracted knowledge as input to decision support • Conclusion ENTER 2014 Research Track Slide Number 23
- 24. Core feedback data Core information extracted from review sites ENTER 2014 Research Track Slide Number 24
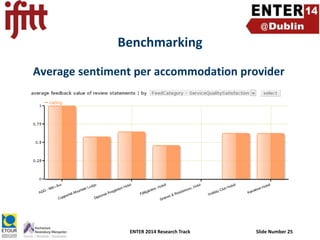
- 25. Benchmarking Average sentiment per accommodation provider ENTER 2014 Research Track Slide Number 25
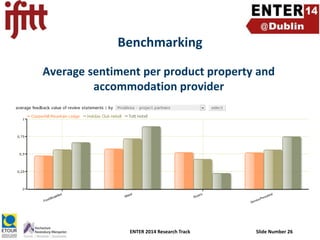
- 26. Benchmarking Average sentiment per product property and accommodation provider ENTER 2014 Research Track Slide Number 26
- 27. Content • Introduction • Sentiment analysis • Methodology and implementation • Evaluation • Extracted knowledge as input to decision support • Conclusion ENTER 2014 Research Track Slide Number 27
- 28. Conclusion • Automatically extracting and analyzing customer reviews from tourism review sites – SVM best machine learning method – POS tagging and N-grams can significantly improve results – Dictionary-based approaches achieve competitive (property) or even superior results (subjectivity) • Extracted knowledge constitutes valuable input to decision support ENTER 2014 Research Track Slide Number 28
- 29. Content • Introduction • Sentiment analysis • Methodology and implementation • Evaluation • Extracted knowledge as input to decision support • Conclusion ENTER 2014 Research Track Slide Number 29