Integrated supercomputing architecture
AI Hypercomputer
AI optimized hardware, software, and consumption, combined to improve productivity and efficiency.

Overview
Performance-optimized hardware
Our performance optimized infrastructure including Google Cloud TPU, Google Cloud GPU, Google Cloud Storage and the underlying Jupiter network consistently provides fastest time to train for large scale state of the art models due to the strong scaling characteristics of the architecture which leads to the best price/performance for serving large models.
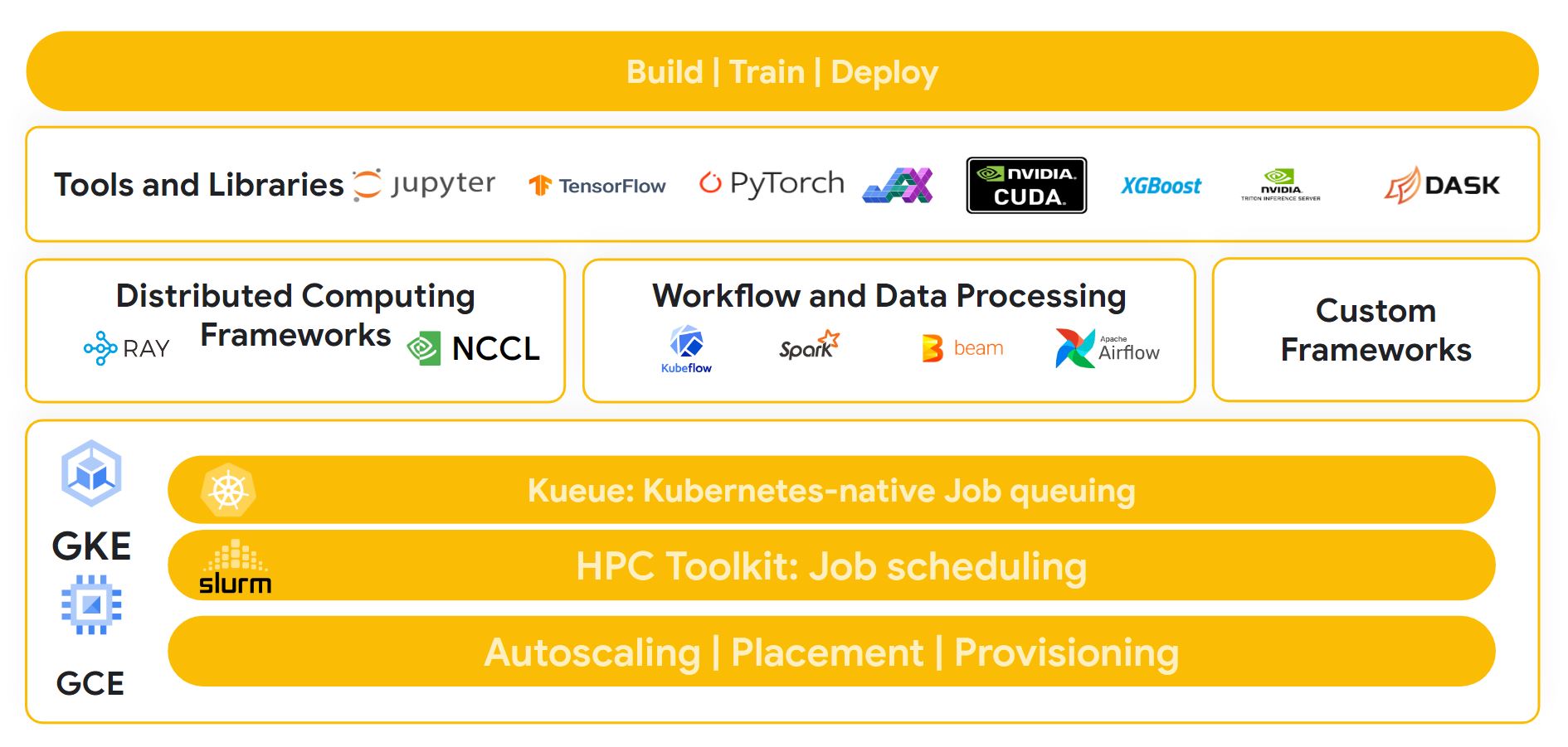
Open software
Our architecture is optimized to support the most common tools and libraries such as Tensorflow, Pytorch and JAX. Plus it allows customers to take advantage of technologies such as Cloud TPU Multislice and Multihost configurations and managed services like Google Kubernetes Engine. This allows customers to deliver turnkey deployment for common workloads like the NVIDIA NeMO framework orchestrated by SLURM.
Flexible consumption
Our flexible consumption models allow customers to choose fixed costs with committed use discounts or dynamic on-demand models to meet their business needs. Dynamic Workload Scheduler helps customers get the capacity they need without over allocating so they are only paying for what they need. Plus, Google Cloud's cost optimization tools help automate resource utilization to reduce manual tasks for engineers.
How It Works
Google is a leader in artificial intelligence with the invention of technologies like TensorFlow. Did you know you can leverage Google’s technology for your own projects? Learn about Google's history of innovation in AI infrastructure and how you can leverage it for your workloads.
Google is a leader in artificial intelligence with the invention of technologies like TensorFlow. Did you know you can leverage Google’s technology for your own projects? Learn about Google's history of innovation in AI infrastructure and how you can leverage it for your workloads.

Common Uses
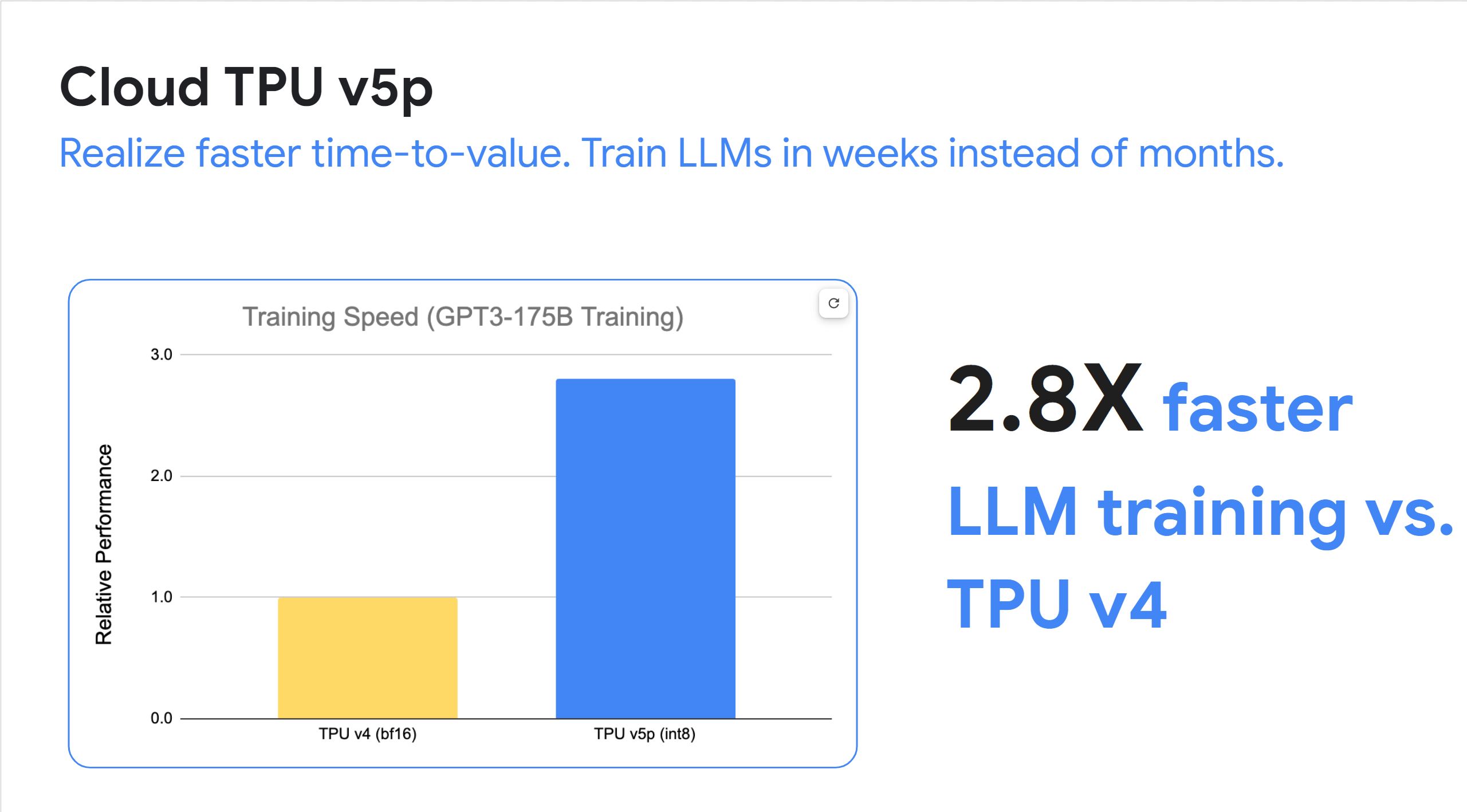
Run large-scale AI training
Powerful, scalable, and efficient AI training
The AI Hypercomputer architecture offers optionality to use the underlying infrastructure that best scales to meet your training needs.
Powerful, scalable, and efficient AI training
Measure the effectiveness of your large scale training the Google way with ML Productivity Goodput.
Character AI leverages Google Cloud to scale up
"We need GPUs to generate responses to users' messages. And as we get more users on our platform, we need more GPUs to serve them. So on Google Cloud, we can experiment to find what is the right platform for a particular workload. It's great to have that flexibility to choose which solutions are most valuable." Myle Ott, Founding Engineer, Character.AI




How-tos
Powerful, scalable, and efficient AI training
The AI Hypercomputer architecture offers optionality to use the underlying infrastructure that best scales to meet your training needs.
Additional resources
Powerful, scalable, and efficient AI training
Measure the effectiveness of your large scale training the Google way with ML Productivity Goodput.
Customer examples
Character AI leverages Google Cloud to scale up
"We need GPUs to generate responses to users' messages. And as we get more users on our platform, we need more GPUs to serve them. So on Google Cloud, we can experiment to find what is the right platform for a particular workload. It's great to have that flexibility to choose which solutions are most valuable." Myle Ott, Founding Engineer, Character.AI
Deliver AI powered applications
Leverage open frameworks to deliver AI powered experiences
Google cloud is committed to ensuring open frameworks work well within the AI Hypercomputer architecture.
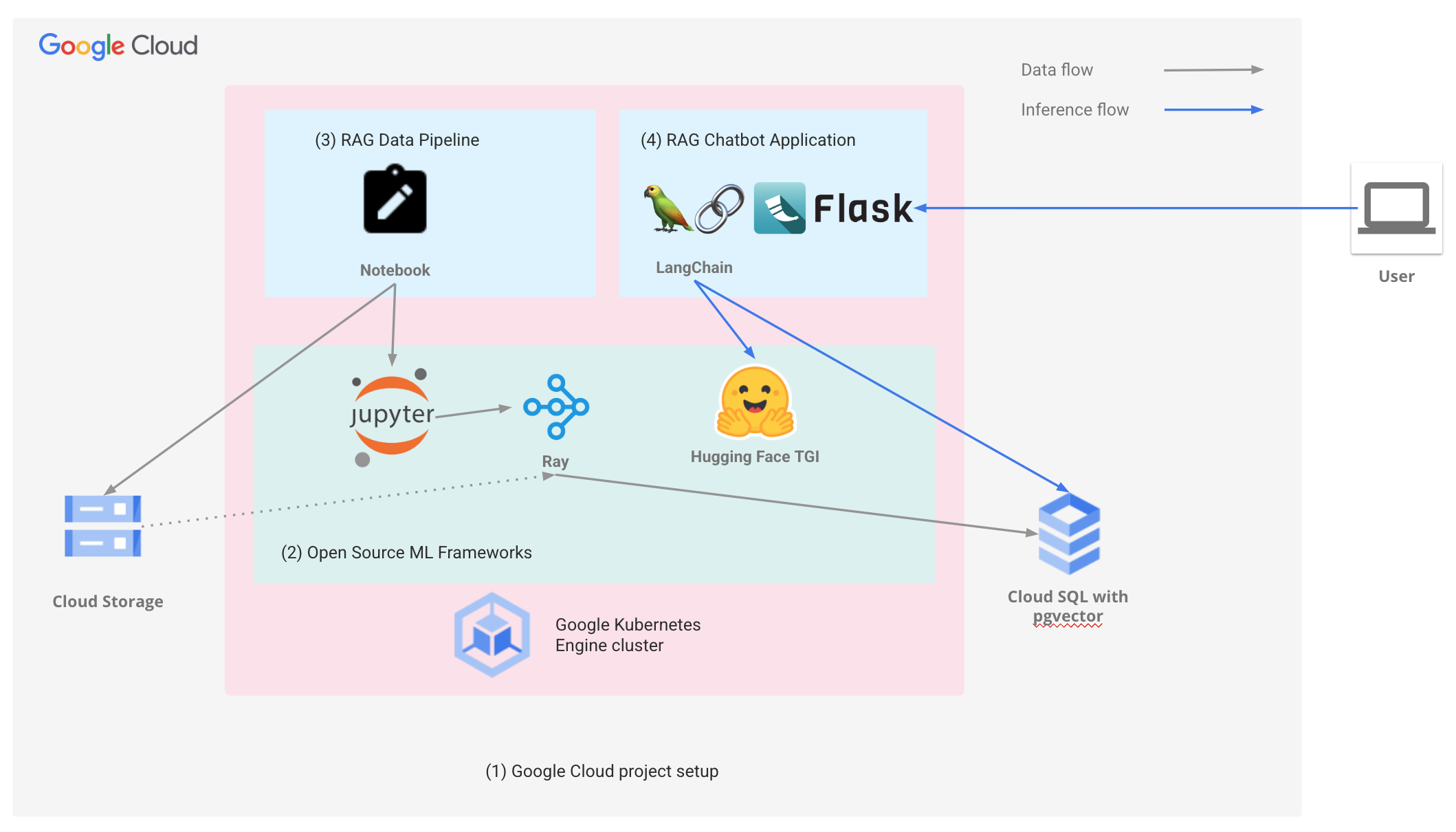
Leverage open frameworks to deliver AI powered experiences
Google Cloud's open software ecosystem allows you to build applications with the tools and frameworks you are most comfortable with, while taking advantage of the price-performance benefits of the AI Hypercomputer architecture.
Priceline: Helping travelers curate unique experiences
"Working with Google Cloud to incorporate generative AI allows us to create a bespoke travel concierge within our chatbot. We want our customers to go beyond planning a trip and help them curate their unique travel experience." Martin Brodbeck, CTO, Priceline




How-tos
Leverage open frameworks to deliver AI powered experiences
Google cloud is committed to ensuring open frameworks work well within the AI Hypercomputer architecture.
Additional resources
Leverage open frameworks to deliver AI powered experiences
Google Cloud's open software ecosystem allows you to build applications with the tools and frameworks you are most comfortable with, while taking advantage of the price-performance benefits of the AI Hypercomputer architecture.
Customer examples
Priceline: Helping travelers curate unique experiences
"Working with Google Cloud to incorporate generative AI allows us to create a bespoke travel concierge within our chatbot. We want our customers to go beyond planning a trip and help them curate their unique travel experience." Martin Brodbeck, CTO, Priceline
Cost efficiently serve models at scale
Maximize price/performance for serving AI at scale
Google Cloud provides industry leading price/performance for serving AI models with accelerator optionality to address any workload's needs.
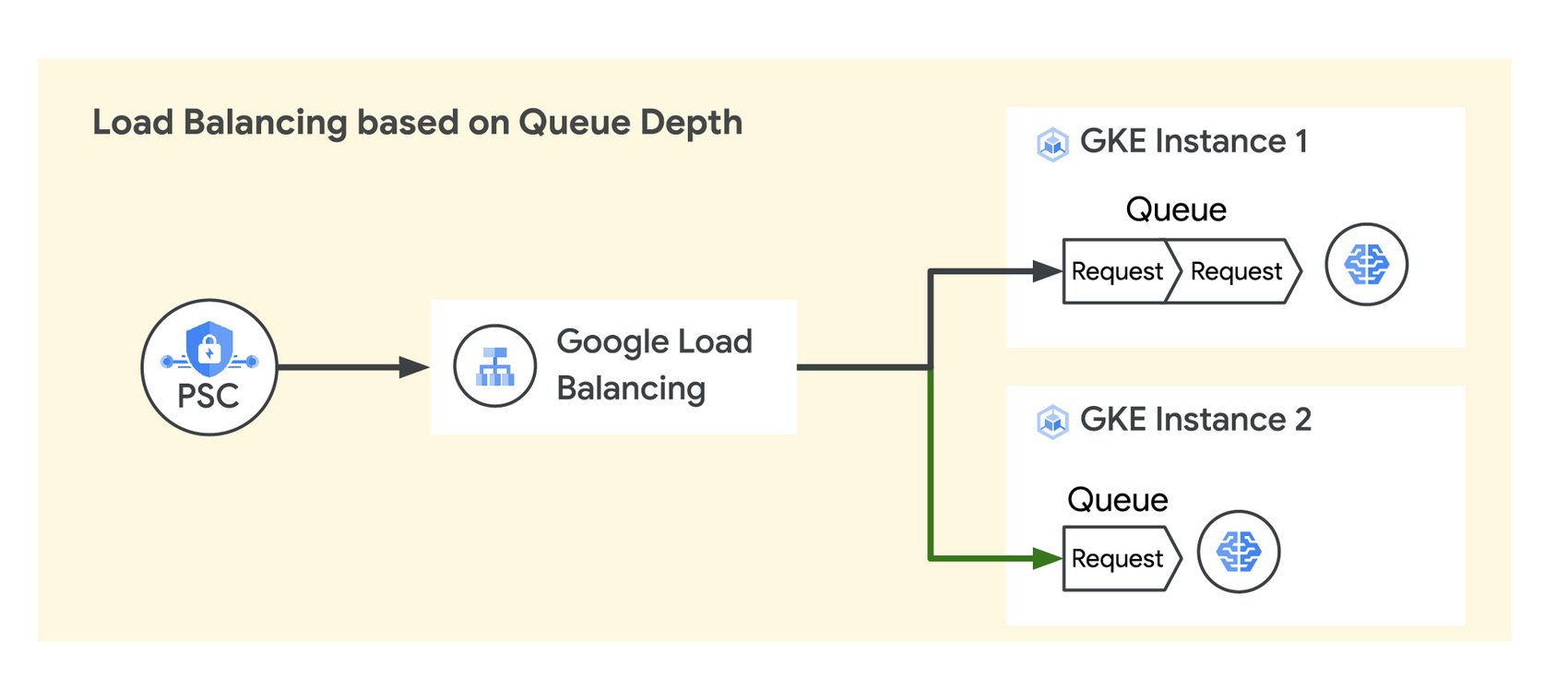
Maximize price/performance for serving AI at scale
Cloud TPU v5e and G2 VM Instances delivering NVIDIA L4 GPUs enable high-performance and cost-effective inference for a wide range of AI workloads, including the latest LLMs and Gen AI models. Both offer significant price performance improvements over previous models and Google Cloud's AI Hypercomputer architecture enables customers to scale their deployments to industry leading levels.
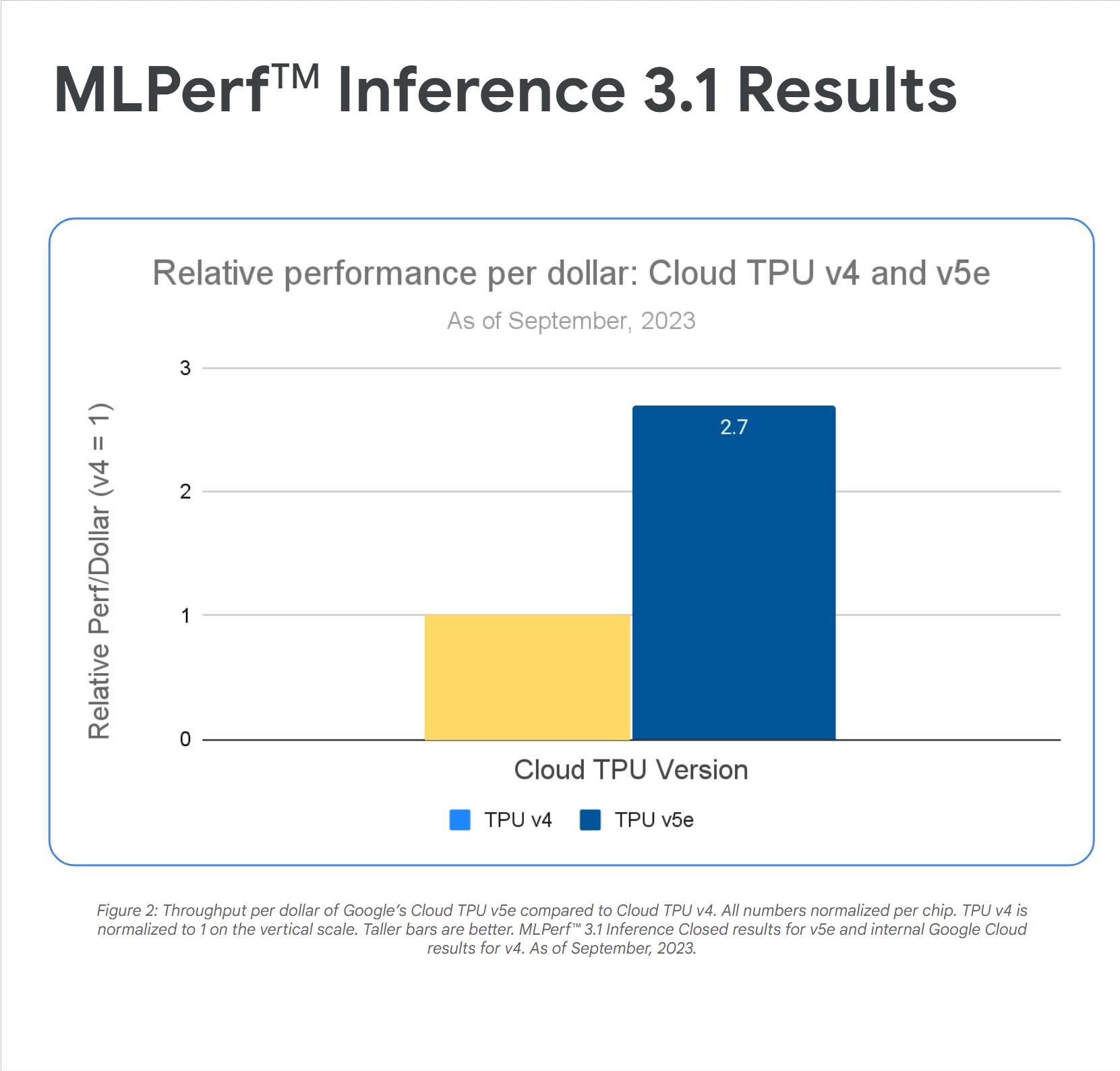

Assembly AI leverage Google Cloud for cost efficiency
"Our experimental results show that Cloud TPU v5e is the most cost-efficient accelerator on which to run large-scale inference for our model. It delivers 2.7x greater performance per dollar than G2 and 4.2x greater performance per dollar than A2 instances." Domenic Donato,
VP of Technology, AssemblyAI


How-tos
Maximize price/performance for serving AI at scale
Google Cloud provides industry leading price/performance for serving AI models with accelerator optionality to address any workload's needs.
Additional resources
Maximize price/performance for serving AI at scale
Cloud TPU v5e and G2 VM Instances delivering NVIDIA L4 GPUs enable high-performance and cost-effective inference for a wide range of AI workloads, including the latest LLMs and Gen AI models. Both offer significant price performance improvements over previous models and Google Cloud's AI Hypercomputer architecture enables customers to scale their deployments to industry leading levels.
Customer examples
Assembly AI leverage Google Cloud for cost efficiency
"Our experimental results show that Cloud TPU v5e is the most cost-efficient accelerator on which to run large-scale inference for our model. It delivers 2.7x greater performance per dollar than G2 and 4.2x greater performance per dollar than A2 instances." Domenic Donato,
VP of Technology, AssemblyAI





















